JFinal 是目前在 git.oschina.net java中关注最多的项目.
亲自用JFinal开发过有上百张表的项目.项目完结后总要做个总结
这篇文章是介绍项目中开发的一些经历.
- 会首先列出JFinal的Model开发 (只是Model的使用)
- 使用Beetlsql替换JFinal的Model (给出一种较爽编码方式)
- 对比两个在写多条件查询sql时, (就是需要条件判断, 为null的不参与查询)
1.JFinal的Model开发
JFinal的ORM下面称JFinal的Model
这是Model的新增 修改 删除
jfinal 实体类1
public class Elephant extends Model<Elephant> {
public static final Elephant Dao = new Elephant();
public List<Integer> findIds() {
return Db.query("select id from tb_bird");
}
}jfinal 测试用例1
@Log4j
public class ElephantTest {
@Test
public void testChainSave() {
// 无需要创建字段
new Elephant().set("age", 17).set("name", "jfinal").set("desc", "mvc + orm").save();
}
@Test
public void testUpdate() {
Elephant elephant = Elephant.Dao.findById(1);
elephant.set("age", 18).update();
}
@Test
public void testDelete() {
Elephant elephant = Elephant.Dao.findById(1);
elephant.delete();
}
}说实话,刚开始看示例的时候感觉很不错. 毕竟不需要自己定义任何字段就能直接将数据保存到表中.
刚开始也使用这种方式进行开发, 但是如果有多个地方使用了这样的代码, 并且产品开发过程中需要更改某几个字段,那么小噩梦就开始了. 毕竟没有工具可以进行这种检测. 表字段名直接写成字符串也都是合法的.那么唯一可以做的就只能搜索整个项目使用到这个类的地方, 然后逐个检查而且需要看得很细. 因为这是人工的检查,所以工具并不能帮上你很大忙.
还有一点是采用这种方式开发就是你必须记住每个表的每个字段, 并且不能出错(需要手动在代码中敲击数据库表字段的名字).
如果是几张表并且字段少的情况下这样玩代码也没有什么. 如果是百张表的项目你会工作得很愉快.
所以就约定了实体类代码必须提供getter,setter. 这样做工具可以提供错误检测
于是项目中的实体类就变成了下面的方式
jfinal 实体类2 getter, setter
public class Elephant extends Model<Elephant> {
public static final Elephant Dao = new Elephant();
public int getId() {
return this.getInt("id");
}
public Elephant setId(int id) {
this.set("id", id);
return this;
}
public int getAge() {
return this.getInt("age");
}
public Elephant setAge(int age) {
this.set("age", age);
return this;
}
public String getName() {
return this.getStr("name");
}
public Elephant setName(String name) {
this.set("name", name);
return this;
}
public String getDesc() {
return this.getStr("desc");
}
public Elephant setDesc(String desc) {
this.set("desc", desc);
return this;
}
public List<Integer> findIds() {
return Db.query("select id from tb_bird");
}
}实体类代码提供了getter,setter (为了继续保持链式风格在setter都返回了自身). 这样做工具可以提供错误检测, 看起来这样很不错了.
jfinal 测试用例2
这是添加getter,setter后的测试用例
@Log4j
public class ElephantChainTest {
@Test
public void testChainSave() {
new Elephant().setAge(17).setName("jfinal").setDesc("mvc + orm").save();
}
@Test
public void testUpdate() {
Elephant elephant = Elephant.Dao.findById(1);
elephant.setAge(18).update();
}
@Test
public void testDelete() {
Elephant elephant = Elephant.Dao.findById(1);
elephant.delete();
}
}好了, Model实体类都拥有了getter, setter方法了. 即便表业务需要改一个字段的名字也没什么大碍, 我就改这个实体类对应的方法名就行. 工具会给我们报错在代码的哪一行使用到了这个属性(字段). 并且也不需要使用到这个实体类的地方都手动敲击这个字段名了. 很不错. 方便了很多!
但是我要告诉你们的是这些getter, setter代码都是人工手动敲上去的. 当初是想用JFinal的Model节省时间的,毫无疑问的是这样做并没有节省我的时间,而且还浪费了很多时间.
这里只是其中一个表对应的实体类(字段也很少, 因为是举例这里只用了4个字段). 如果百个实体类而有的实体类有8个,15个甚至更多属性(是的,你没看错, 你会越来越愉快).
上面说到为什么这些代码是人工手动敲上去的. 工具不是可以生成getter,setter吗. 我想说的的确是可以生成, 但是工具生成这些代码是有前提条件的. 这些条件就是你必须显示的拥有类的成员属性.
所以很遗憾, 你享受不到工具带来的便捷
好了, 代码约定Model实体类都必须提供getter, setter方法. 那么代码总要加上点注释吧. 于是代码就变成如下:
public class Elephant extends Model<Elephant> {
public static final Elephant Dao = new Elephant();
/**
* @return 年龄
*/
public int getAge() {
return this.getInt("age");
}
/**
* @param age 年龄
* @return this
*/
public Elephant setAge(int age) {
this.set("age", age);
return this;
}
/**
* @return 名字
*/
public String getName() {
return this.getStr("name");
}
/**
* @param name 名字
* @return this
*/
public Elephant setName(String name) {
this.set("name", name);
return this;
}
/**
* @return 描述
*/
public String getDesc() {
return this.getStr("desc");
}
/**
* @param desc 描述
* @return this
*/
public Elephant setDesc(String desc) {
this.set("desc", desc);
return this;
}
public List<Integer> findIds() {
return Db.query("select id from tb_bird");
}
}这样从一个最初只有1行代码的实体类, 最后变成了这样. 如果你在看这篇文字, 感觉变成了这样并有没什么. 但是你想知道变成拥有getter, setter加上注释花了多少时间吗? (请读者自行建立一个拥有8个字段的实体玩下).
我在想我为什么要花如此多的时间创建在model上 (我这样安慰我自己的, 这也属于有氧运动吧).
JAVA 极速WEB+ORM框架 JFinal
JFinal 是基于 Java 语言的极速 WEB + ORM 框架,其核心设计目标是开发迅速、代码量少、学习简单、功能强大、轻量级、易扩展、Restful。在拥有Java语言所有优势的同时再拥有ruby、python等动态语言的开发效率!为您节约更多时间,去陪恋人、家人和朋友 ;)
块引用中的开发迅速与代码量少.没有明确的说是JFianl的代码量少还是使用JFinal开发项目的代码量少. 至少我认为项目中的Model如果显示提供getter,setter代码量就已经巨大且编码效率极慢(仅是JFinal的ORM给我的感觉. 也并不完全是感觉, 毕竟上面的代码示例包含了我想说的话了).
显示提供也不是,不显示提供也不是. 两难.
2.使用Beetlsql替换JFinal的Model
beetlsql + java8 + lombok 结合使用,达到代码最简洁效果, 并且可阅读性更强 (下面称为第二种编码方式)
(极简版)实体类1
@Data
@FieldDefaults(level = AccessLevel.PRIVATE) // 属性默认都是private
@lombok.experimental.Accessors(chain = true) // 链式编程
@Table(name = "tb_bird") // 实体类与表映射
public class Bee implements $Sql { // 实现$Sql接口, 可以在对象上直接使用 save, update, delete 方法 (不是必须的)
int id;
/** 年龄 */
Integer age;
/** 名字 */
String name;
/** 描述 */
String desc;
}lombok.@Data自动提供getter,setter,toString等方法. 所以并不需要在代码中显示的生成getter,setter方法(方法上都会有注释), 这让实体类更加的干净.
上面的示例中实体类只需要实现接口,而不需要任何继承就能达到想要的效果.(Effective Java 第18条:接口优于抽象类)
测试类
@Log4j
public class BeeChainTest {
@Test
public void testChainSave() {
new Bee().setAge(17).setName("beetl").setDesc("beetlsql + orm").save();
}
@Test
public void testUpdate() {
Bee bee = Bee.Dao.$.unique(1);
bee.setAge(18).update();
}
@Test
public void testDelete() {
Bee bee = Bee.Dao.$.unique(1);
bee.delete();
}
}可以看出, 就ORM方式而言. 我更倾向于后面这种结合.
- 自动拥有getter setter, 在也不需要手工敲击(有氧运动)
- 代码更加清晰,简洁, 甚至可以说真正的做到了代码量少. 让你开发更迅速.
在上面JFinal的Model中和下面一种方式, 如果我们都在两个实体类中在追加1个字段(并加上注释), 第二种方式无疑是最方便的.
因为JFinal的Model添加一个字段的getter setter并加上注释 需要14行代码, 而第二种方式只需要两行(可以在上面给出的示例中自己数).也就是说实体类每增加一个字段, 你的Model类相比使用第二种方式多出12行代码(7倍代码量, 这还是在你手工敲击getter setter名字完全正确率100%的情况下, getName getNema不出现这种拼写意外).
所以为了防止这种意外你也许会说我可以在Model里面先定义属性并确定类型, 然后使用工具生成getter setter经过部分改动接着在把这个定义的属性删除掉就行了(这样就不会产生拼写意外, 而且能享受工具生成代码的便捷). 我想说的是你很幽默. 并且我想对你说的是曾经我也这样幽默过.
说实话假设类有10个字段. 那么一个是140代码量和一个是20行代码量的,你更愿意看见哪一个? 不知道你们是怎么想的,我看140行代码的时候, 我还得在工具里上下翻滚.而第二种方式我一眼就能明白是怎么回事.
如果字段改个名字那么Model需要改动的地方有7处(换句话说就是维护7处). 第二种方式只需要改1处. (这里仅计算实体类里面的改动, 暂不考虑被项目中其他地方引用该实体类的地方)
beetlsql的链式编程
有一个坏消息是beetlsql在发布这篇文章的时候还不能支持链式编程
因为setter方法这种写法不是Javabean的标准写法,所以beetl无法认定这是一个属性,因此才会有刚才那种生成的sql语句
beetlsql会在下个版本支持读取field而不是getter,setter,不过需要点时间
当然有坏消息就会有好消息. 细心的朋友会发现将来的版本中作者会提供
3.对比两个在写多条件查询sql时
当然,如果仅仅是从上面的Model做对比还是无法吸引你的话,那么这一节中就要拿出Beetlsql锋利的一面了(这里不会列举得很详细,只是简单的几个方法介绍).更具体的得到beetlsql官网上查阅资料.
有多个条件参数(就是需要条件判断, 为null的不参与查询)
下面各举三个方法执行同样的sql查询做比较
- 查询所有id - findIds
- 三个条件参数来查询单个对象 - findOne
- 两个条件参数来查询一个对象列表 - finds
jfinal Model类现在的代码加上这三个查询后的代码
public class Elephant extends Model<Elephant> {
public static final Elephant Dao = new Elephant();
/**
* @return 年龄
*/
public int getAge() {
return this.getInt("age");
}
/**
* @param age 年龄
* @return this
*/
public Elephant setAge(int age) {
this.set("age", age);
return this;
}
/**
* @return 名字
*/
public String getName() {
return this.getStr("name");
}
/**
* @param name 名字
* @return this
*/
public Elephant setName(String name) {
this.set("name", name);
return this;
}
/**
* @return 描述
*/
public String getDescription() {
return this.getStr("description");
}
/**
* @param description 描述
* @return this
*/
public Elephant setDescription(String description) {
this.set("description", description);
return this;
}
public List<Integer> findIds() {
return Db.query("select id from tb_bird");
}
public Elephant findOne(int age, String name, String description) {
StringBuilder sql = new StringBuilder("select * from tb_bird where 1 = 1");
List<Object> pars = new LinkedList<>();
if (age != 0) {
sql.append(" and age = ? ");
pars.add(age);
}
if (name != null) {
sql.append(" and name = ? ");
pars.add(name);
}
if (description != null) {
sql.append(" and description = ? ");
pars.add(description);
}
return this.findFirst(sql.toString(), pars.toArray());
}
public List<Elephant> finds(int age, String name) {
StringBuilder sql = new StringBuilder("select * from tb_bird where 1 = 1");
List<Object> pars = new LinkedList<>();
if (age != 0) {
sql.append(" and age = ? ");
pars.add(age);
}
if (name != null) {
sql.append(" and name = ? ");
pars.add(name);
}
return Db.query(sql.toString(), pars.toArray());
}
}jfinal Model查询测试用例
@Log4j
public class ElephantFindTest {
@Before
public void bf() {
Config.jfinalInit();
}
@Test
public void findIds() {
// 查询所有主键
List<Integer> ids = Elephant.Dao.findIds();
log.info(ids);
}
@Test
public void findOne() {
Elephant one = Elephant.Dao.findOne(18, "a", "n");
log.info(one);
}
@Test
public void finds() {
List<Elephant> list = Elephant.Dao.finds(18, "b");
log.info(list);
}
}(极简版) 第二种方式类现在的代码加上这三个查询后的代码
@Data
@FieldDefaults(level = AccessLevel.PRIVATE) // 属性默认都是private
@lombok.experimental.Accessors(chain = true) // 链式编程
@Table(name = "tb_bird") // 实体类与表映射
public class Bee implements $Sql { // 实现$Sql接口, 可以在对象上直接使用 save, update, delete 方法 (不是必须的)
int id;
/** 年龄 */
Integer age;
/** 名字 */
String name;
/** 描述 */
String description;
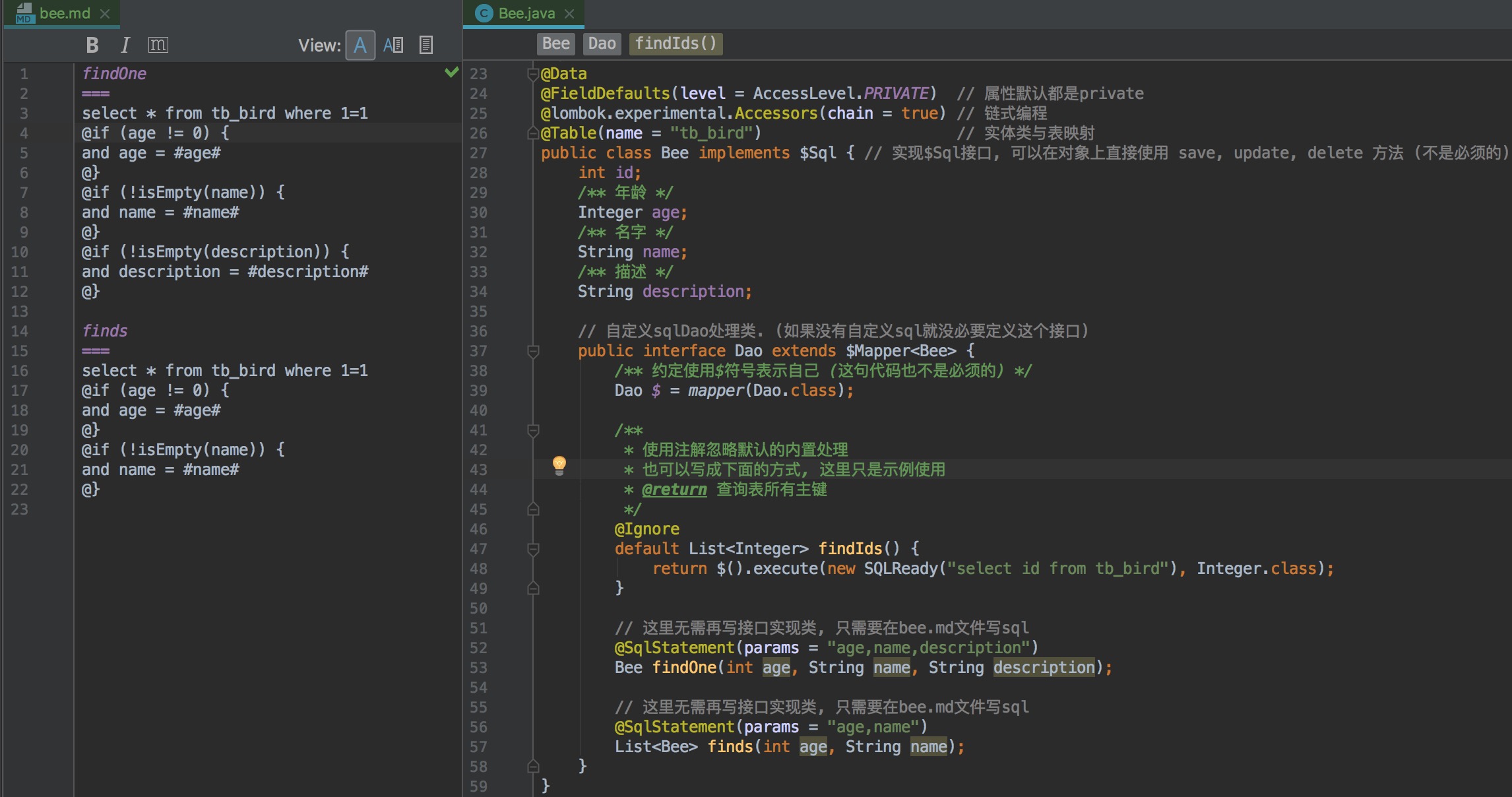
// 自定义sqlDao处理类. (如果没有自定义sql就没必要定义这个接口)
public interface Dao extends $Mapper<Bee> {
/** 约定使用$符号表示自己 (这句代码也不是必须的) */
Dao $ = mapper(Dao.class);
/**
* 使用注解忽略默认的内置处理
* 也可以写成下面的方式, 这里只是示例使用
* @return 查询表所有主键
*/
@Ignore
default List<Integer> findIds() {
return $().execute(new SQLReady("select id from tb_bird"), Integer.class);
}
// 这里无需再写接口实现类, 只需要在bee.md文件写sql
@SqlStatement(params = "age,name,description")
Bee findOne(int age, String name, String description);
// 这里无需再写接口实现类, 只需要在bee.md文件写sql
@SqlStatement(params = "age,name")
List<Bee> finds(int age, String name);
}
}第二种方式查询测试用例
@Log4j
public class BeeFindTest {
@Before
public void bf() {
Config.dbInit();
}
@Test
public void findIds() {
// 查询所有主键
List<Integer> ids = Bee.Dao.$.findIds();
log.info(ids);
}
@Test
public void findOne() {
Bee one = Bee.Dao.$.findOne(18, "a", "n");
log.info(one);
}
@Test
public void finds() {
List<Bee> list = Bee.Dao.$.finds(18, "b");
log.info(list);
}
}从上面两个示例代码中可以看出优缺点:
试着想一下,假设这类有15个字段并且与数据库交互的方法有10个左右.这里只是这样列举了一个类的三个方法(并且最多的查询条件只有三个,Model需要代码量就太多了点.那么我相信你的项目中有条件参数的并且大于三个的不会没有), 实际项目中表的数量比这个恐怖得多,这个时候就不是假设了,而是玩真的了.
关于Model
Model把所有与数据库打交道的地方都写在一个类里面. , 你可以想象这个Model的代码有多庞大与臃肿,维护费时
关于beetlsql
不需要编写数据库打交道的实体类. 只需要定义接口并编写对应 md文件
所有sql语句都存放类对应的md文件中管理 (如果简单的语句可以直接写在接口中, 声明default就可以)
在两个实现同样功能的情况下, 而第二种方式编写代码是极其的简洁, 甚至预览代码都快很多倍.
这里在放上第二种方式与md(sql)文件管理的截图
最后
上面都是亲自开发在有很多表的项目中的一些总结与讨论.
当然本文并不是说JFinal的Model不好用也不是说jfinal的缺点, 而是找到了一种(这个是仅是自认为)可以替代Model更好的编码方式.
这里是一个 beetlsql demo 大家可以参考.
最后我想说的是,一旦你使用beetlsql并结合上面推荐的方式编码. 你就在也回不去了,因为真的很爽.
曾经使用过 (Hibernate Mybatis) 在使用beetlsql, 你也不会想回到过去