内存管理笔记十、buddy伙伴系统
引言:上一篇笔记中,我们介绍了段页式的内存管理方式其不仅获得分段和分页的好处,又规避了单纯分段和分页的缺陷。这看似是一个完美的解决方案。但每次申请内存,均要完成虚拟地址至物理地址的映射、要改写内核的页表项、刷新TLB,以页为单位降低了内存分配速度。因此linux在段页式内存管理基础上,增加伙伴系统分配机制,可以理解为以空间换取时间和性能的机制。
一、linux物理内存划分管理
为了有效的管理物理内存(分配、回收),Linux将整个物理内存划分为若干页,对每一个页,都有相关的数据结构来记录该页的状态和使用信息。在Linux中,每个页的大小是4KB。对于一个512MB的物理内存一共有(512 * 1024)/ 4 = 131072个页。对于每一个页,Linux都有一个struct page数据结构来记录该物理页的使用情况。所有页的struct page结构组成一个连续的数组存放在物理内存的某个地方。某页在物理内存中的物理地址除以4KB,就得到该页是第几个物理页索引,然后索引就可以查询struct page数组,得到该页的具体信息。
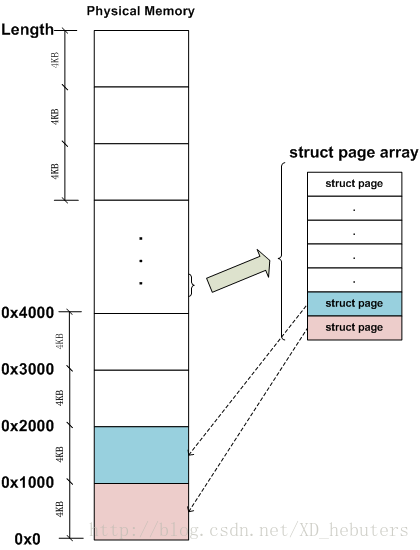
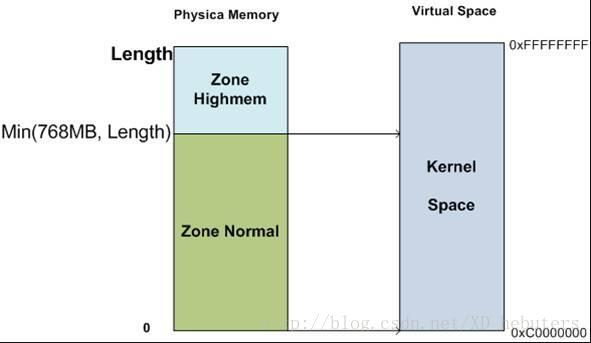
除了使用struct page来记录某个4KB物理页的状态和使用信息外,Linux还将整个物理内存根据物理地址划分为不同的区。区的划分是与体系结构相关的(由于硬件的限制,内核不能对所有的页一视同仁)。对于X86,ZONE可以划分为DMA区[0,16MB]、NORMAL区[16MB, 896MB]和HIGHMEM区[896MB,memory length]。对于ARM,ZONE划分为NORMAL区和HIGHMEM区。其中NORMAL区对应线性映射的物理内存,HIGHMEM区对应非线性映射的物理内存。
二、Buddy伙伴系统
我们介绍分页系统时已经讲过,分页系统不会产生外部碎片,一个进程占用的内存空间可以是不连续的,并且一个进程的虚拟页面在不需要的时候可以存放在磁盘上。当进程需要较大运行内存,以页为单位分配物理内存,每页均要完成虚拟地址至物理地址的映射、改写内核页表项、刷新TLB,效率较低。因此linux在段页式内存管理基础上,增加伙伴系统分配机制,我理解其为以空间换取性能的一种方式。
2.1、伙伴系统的作用:
它要解决的问题是频繁地请求和释放不同大小的一组连续页框,必然导致在已分配的块内分散了许多小块的空闲页面,由此带来的问题是,即使有足够的空闲页面可以满足请求,但要分配一个大块的连续页框可能无法满足请求。其要完成的作用,即高效的分配和回收资源,降低外部碎片。
2.2、伙伴系统的介绍:
Buddy System是Linux Kernel 进行物理内存页管理的一个子系统。在Buddy System中,管理的一个基本单位是block,每一个block有若干个连续的物理页组成,物理页的个数为2n,这个n在buddy system中被称为order。相同order的block,挂载一条双向链表上。
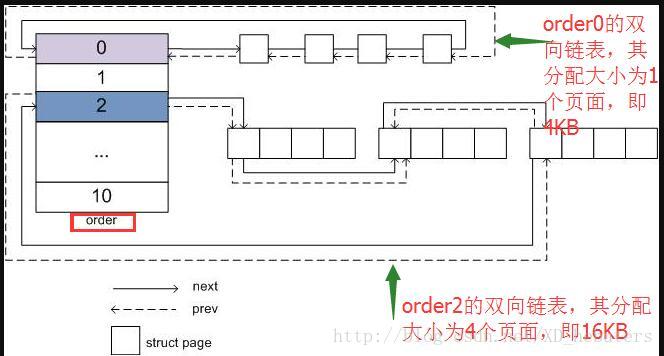
当某个block空闲时,只要发现对应的伙伴也是空闲的,就和伙伴组成一个页数为2n+1的block,挂载在order为(n+1)的双向链表上,换句话说一个页数为2n的block,是由两个页数为2n-1的伙伴block组成的。因此,一个block的伙伴肯定是和这个block在物理地址上是连续的。在Linux中,order的默认的取值范围是[0,10],其单次分配的最大内存为4M,即210 个4K页面。
2.3、申请和释放过程:
申请物理内存过程:假设请求一个页框的块(即4KB),算法先在1个页框的链表中检查是否有空闲块。若没有,则查找下一个更大的块,即在2个页框的链表中找一个空闲块。如果存在这样的块,内核就把2的页框分成两等份,一半用作满足请求,另一半插入到1 个页框的链表中。
如果在2个页框的块链表中也没找到空闲块,就继续找更大的块 —— 4个页框的块。如果这样的块存在,内核把4个页框块的1 个页框用作请求,然后从剩余的3个页框中拿2个插入到2个页框的链表中,再把最后的1个插入到1个页框的链表中。如果最终至1024个页框的链表还是空的,算法就放弃并发出错信号。

释放物理内存过程:以上过程的逆过程就是页框块的释放过程,也是该算法名字的由来。内核试图把大小为b的一对空闲伙伴(两个块具有相同大小,且它们物理地址连续)合并为一个大小为2b的单独块。这个算法是迭代的,如果它成功合并所释放的块,它会试图合并2b 的块,以再次试图形成更大的块。
2.4、伙伴系统实现 ——相关数据结构:
我们介绍了区的概念,每个管理区都有自己的struct zone, 而struct zone中的struct free_area则是用来描述该管理区伙伴系统的空闲内存块的。其部分代码如下:
struct zone {
...
...
struct free_area free_area[MAX_ORDER];
...
...
} struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
}; free_area共有MAX_ORDER个元素,,这些空闲块在free_list中以双向链表的形式组织起来,对于同等大小的空闲块,其类型不同,将组织在不同的free_list中,nr_free记录了该free_area中总共的空闲内存块的数量。MAX_ORDER的默认值为11,这意味着最大内存块的大小为2^10=1024个页框。
关于伙伴系统的内核实现及相关细节,可以参考伙伴系统概述、伙伴系统初始化、伙伴系统分配页、伙伴系统释放页、通过迁移类型实现反碎片等。
2.5、伙伴算法的优缺点分析:
优点:
1)、较好的解决外部碎片问题
2)、当需要分配若干个内存页面时,用于DMA的内存页面必须连续,伙伴算法很好的满足了这个要求
3)、只要请求的块不超过1024个页面(4M),内核就尽量分配连续的页面。
4)、针对大内存分配设计
缺点:
1)、合并的要求太过严格,只能是满足伙伴关系的块才能合并
2)、 碎片问题:一个连续的内存中仅仅一个页面被占用,导致整块内存区都不具备合并的条件
3)、浪费问题:伙伴算法只能分配2的幂次方内存区,当需要8K(2页)时,好说,当需要9K时,那就需要分配16K(4页)的内存空间,但是实际只用到9K空间,多余的7K空间就被浪费掉。
4)、算法的效率问题: 伙伴算法涉及了比较多的计算还有链表和位图的操作,开销还是比较大的,如果每次2^n大小的伙伴块就会合并到2^(n+1)的链表队列中,那么2^n大小链表中的块就会因为合并操作而减少,但系统随后立即有可能又有对该大小块的需求,为此必须再从2^(n+1)大小的链表中拆分,这样的合并又立即拆分的过程是无效率的。
总结: Linux针对大内存的物理地址分配,采用伙伴算法,如果是针对小于一个page的内存,频繁的分配和释放,有更加适宜的解决方案,如slab,那是后面笔记的内容
参考内容:
认识Linux物理内存管理系统 - Buddy System
Linux伙伴算法介绍
linux伙伴系统概述
纠错与建议
邮箱:[email protected]