最近偷空研究了一下python,准备用python写一个爬虫。
在使用scrapy,爬取网页信息时,我需要去定位节点,所以也就有了下面这篇文章。
例子代码:
1 import scrapy 2 from tutorial.items import DemozItem 3 4 class DmozSpider(scrapy.Spider): 5 name = "dmoz" 6 allowed_domains = ["dmoz.org"] 7 start_urls = [ 8 "file:///D:/pyscrapy/tutorial/tutorial/spiders/test.html" 9 ] 10 def parse(self, response): 11 #将爬取的数据以Item对象的形式返回 12 for sel in response.xpath("//p/a[@name='链接']"): 13 #item = DemozItem() 14 list = sel.xpath('text()').extract() 15 if len(list) != 0: 16 print(list[0].replace(' ', ''))
从例子代码中可以看到xpath()方法中的参数为xpath路径表达式。我要去写我所需要信息的xpath,才能抓取到我需要的信息,所以书写xpath表达式是必然的。
在探索中我找到了一个可以很方便查找xpath表达式的插件,由于我是chrome浏览器所以安装这个插件网上很多介绍,你可以去这里下载并了解这个插件:在这里 这里面讲解很详细包括安装和使用。
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。(W3School 中有一些用法)
获取父节点的使用方式:
获取name为“现病史”结点父节点的父节点(p):
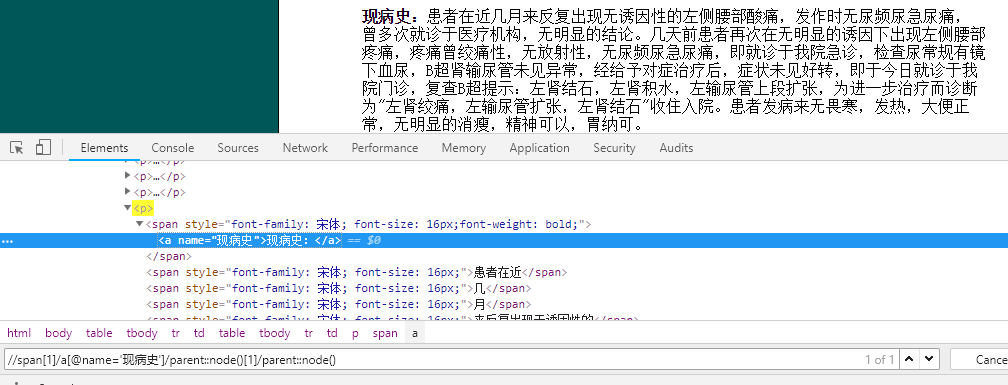
可以看到表达式锁定的p颜色为标记为了黄色。
//span[1]/a[@name='现病史']/parent::node()[1]/parent::node()
获取子节点(child::node()[1]代表取子节点的第一个,如果不写则是取所有):
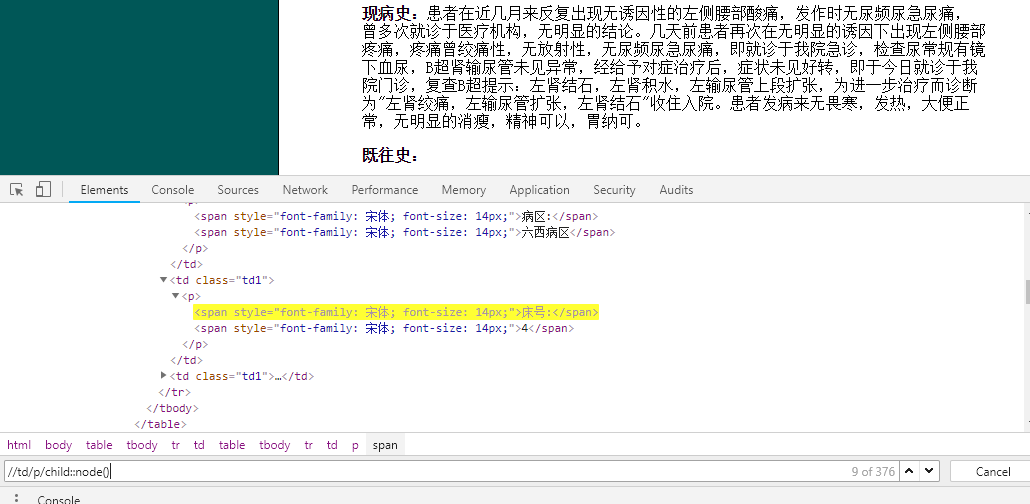
可以看到一共匹配了376个结果,当前是第九个满足匹配的节点。