二叉排序(搜索)树是以关键码为结点的二叉树,其性质:如果任一结点的左子树非空,则左子树的所有结点的关键码都小于根结点的关键码;如果任一结点的右子树非空,则右子树的所有结点的关键码都大于根结点的关键码。二叉排序树的存储结构如下,
typedef struct BinSortNode* PBinSortNode;
typedef struct BinSortNode* BinSortTree;
typedef BinSortTree* PBinSort
struct BinSortNode
{
KeyType key;
PBinSortNode llink, rlink;
};下面是一颗二叉排序树,
二叉排序树的检索
要向二叉排序树插入一个新的结点,需要先在树中进行检索,检索的过程与二分法检索相似,逐步缩小检索的范围 。设在二叉排序树上查找关键码为key的结点,检索成功时,position指向查找到的结点指针;检索失败时,position指向该节点应该插入位置的父节点。注意,position是结点指针的指针类型,为什么函数不直接返回结点指针类型?因为函数返回整型可以确定检索的成功与否,同时又可以通过position得到新的结点应该插入位置的父节点,算法实现如下,
int Search(BinSortTree t, KeyType key, PBinSortNode *position)
{
PBinSortNode p = t,pre;
while(p != NULL){
pre = p;
if(p->key == key){
*position = p; return 1;
}
else if(key < pre->key) p=p->llink;
else p=p->rlink;
}
*position = pre;
return 0;
}假设二叉排序树共有n个结点,高度是h(log2n≤h≤n),则检索的时间代价最坏为O(h)。
二叉排序树的插入
实现了上面二叉排序树的检索,就可以很快地插入结点,即检索操作是插入操作的一部分。所以,如果二叉排序树为空树,则新结点作为根结点。如果非空,则将新结点的关键码与position的关键码作比较,若前者小则将新结点插入到position的左子树,否则插入到position的右子树。具体算法如下,
int Insert(BinSortTree t, KeyType key)
{
PBinSortNode p, position;
if(Search(t, ket, &position)==1) {
cout>>"Exist the node"; return 1; //已存放该节点
}
p = new struct BinSortNode;
if(p == NULL) {
cout<<"Error"; return 0;
}
p->key = key; p->llink=p->rlink=NULL;
if(position == NULL) t = p; //原树为空树
else if(key < position->key) position->llink = p;
else position->rlink = p;
return 1;
}二叉排序树的构造
既然实现了新结点的插入操作,那么就可以将字典的关键码一一插入到二叉排序树中,从而实现二叉排序树的构造算法,
int CreateSortTree(BinSortTree t, KeyType *dic)
{
*t = NULL; //将二叉排序树置为空
for( int = 0; i < strlen(dic); i++) //将新结点插入树中
if(!Insert(t, dic[i])) return 0;
return 1;
}二叉排序树的删除
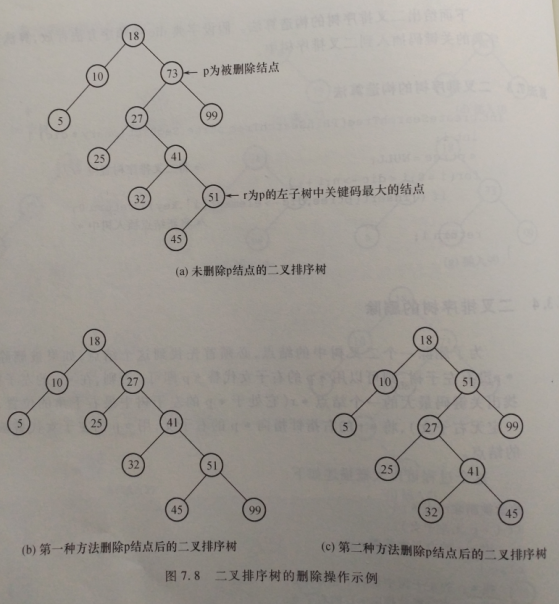
为了删除一个结点,必须首先找到它。注意,这里没有用到上面的检索操作,因为那只提供了该节点的位置,但不知道其父节点的位置(不同于插入位置的父节点)。删除操作的一种方式如下:
检索被删除结点p;
if(p无左子女)
用p的右子女代替p;
else{
找p的左子树中关键码最大的结点MAX(最右下结点);
用MAX的右指针指向p的右子女;
用p的左子女代替p;另一种删除方式区别于上面带下划线斜体部分,用下面语句代替:
用MAX结点代替被删除的结点p;
用原来MAX的左子女代替MAX;如下图,(b)和(c)分别是删除操作的两种方式示例,
第一种方式的代码实现如下:
int Delete(BinSortTree t, KeyType key)
{
PBinSortNode pre, p, MAX;
p = t; pre = NULL;
while(p!=NULL){ //找关键码为key的结点
if(p -> key==key) break;
pre = p;
if(key < p->key) p = p->llink;
else p = p->rlink;
}
if(p == NULL) return 0; //不存在
if(p->llink == NULL){ //无左子树
if(pre == NULL) //删除的是树根结点
t = p->rlink;
else if(pre->llink == p) //将p的右子树接到父节点的左链
pre->llink = p->rlink;
else //将p的右子树接到父节点的右链
pre->rlink = p->rlink;
}
else{ //有左子树
MAX = p->llink;
while(MAX->rlink != NULL) MAX = MAX->rlink; //找p的左子树中关键值最大的结点
MAX->rlink = p->rlink; //用MAX的右指针指向p的右子女
if(pre = NULL) //删除的是树根结点
t = p->llink;
else if(pre->llink == p) //将p的左子树接到父节点的左链
pre->llink = p->llink;
else //将p的左子树接到父节点的右链
pre->rlink = p->llink;
}
delete p;
return 1;
}另一种不同于下划线部分:
else{
MAX = p->llink;
PBinSortNode preMAX = MAX; //引进局部变量preMAX,初始化为MAX
while(MAX->rlink != NULL){ //找p的左子树中关键值最大的结点,并用preMAX保存最大结点的父节点
preMAX = MAX; MAX = MAX->rlink;
}
p->key = MAX->key; //复制结点信息,实现所谓的代替
if(preMAX == p) p->llink = MAX->llink; //MAX的父节点就是p
else preMAX->rlink = MAX->llink; //用MAX的左子女代替MAX
p = MAX; //为统一在下面释放内存
}