语言模型会估计某个句子序列各个单词出现的概率
如何构建语言模型?
为了使用RNN建立出这样的模型,首先我们需要一个训练集,包含一个很大的英文文本语料库(a corpus of English text),语料,即语言材料。其他语言也可。
标记化:Tokenize
建立一个字典,将每个单词转成一个one-hot向量,也就是字典中的索引。使用EOS标记附加到训练集中每个句子的结尾。
如果有些单词不在词典里(生词),可以把他替换为UNK(unkwon word),我们只针对UNK建立概率模型,而不针对具体的词。
标志化完成后,将输入的各个单词都映射懂了各个标志(token)上,或者说字典中的各个词上。
下一步我们要构建一个rnn来构建这些序列的概率模型。
第0个time-step,我们要计算激活项a<1>,它是以x<1>作为输入的函数,而
x<1>会被设为全为0的集合零向量。a<0>也是。
a<1>会通过softmax进行预测,计算第一个单词y<1>会是什么。
这一步要做的就是,通过一个softmax层预测字典中的任何一个词是第一个词的概率
如果字典中有10000个词,则softmax层的输出可能也有10000(+2)个(unk 、eos)。
下一个time-step使用激活项a<1>,我们要预测第二个单词是什么。现在我们依然传递给他们。
正确的第一个词y<1>(=x<2>),此时输出也是经过softmax层的输出,是字典中各个词出现的概率。
只考虑之前的单词。之后的预测以此类推。

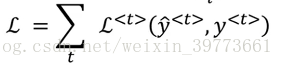
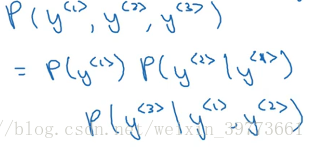
预测三个单词的情况,概率相乘结果。(符合概率论中的条件分布,在已知y1的情况下预测y2,在已知y1、y2的情况下预测y3。三者相乘的概率等于直接预测三者是一个整体的概率)