一、GROUP BY 语句
1、为什么SQL数据要进行分组,即为什么要有GROUP BY 语句?
SQL语句中可对数据进行函数运算,而函数大部分属于聚合函数,只出现一个值,而有时我们会想要查看一个表格中不同种类的不同函数值,这就需要进行分组了。
2、如何分组?
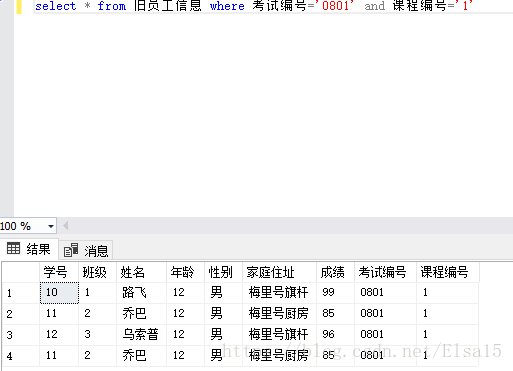
首先查询数据,先查询一下考试编号为0801的数据
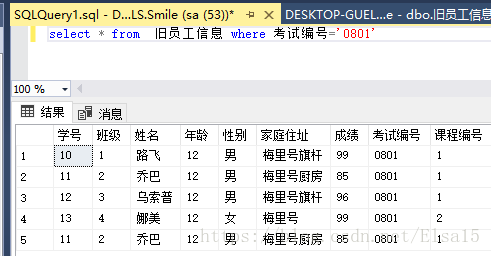
其次:对所查出的0801编号里的课程编号进行分组统计,就用到了我们的分组group by语句
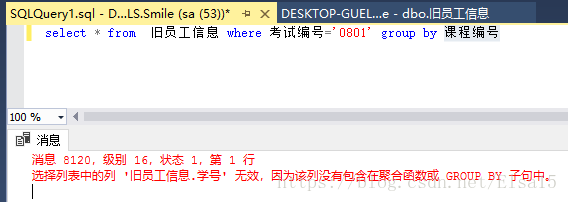
报错,这个错误的解决方法在以下链接中已有说明:
对此代码进行了如下更改,便查询出来了结果
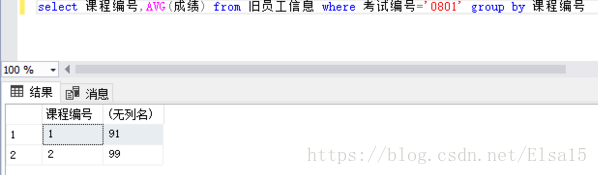
那以上代码查询出来的是什么内容呢?
考试编号为0801中的1/2课程总的平均成绩。换言之,把编号为0801的列,按照课程编号进行分组,并求值,可求平均值,总和等。类似于Excel中的分类汇总。
3、在以上代码的group by 后面加上cube 会是什么样的效果?
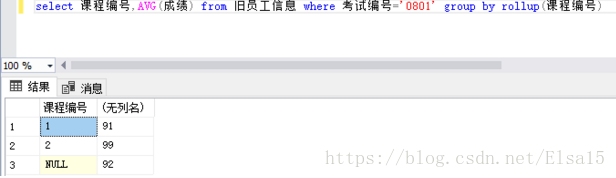
92是什么?是以上编号为1/2课程的又一平均值
4、在以上代码的group by 后面加上rollup 会是什么样的效果?
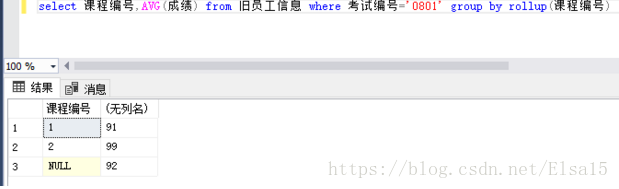
结果是一样的,也是对编号为1/2课程进行的再次平均
5、cube和rollup 有什么区别?
cube
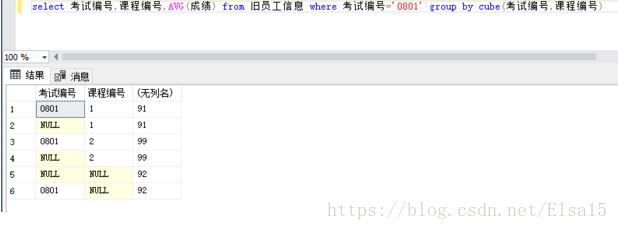
rollup
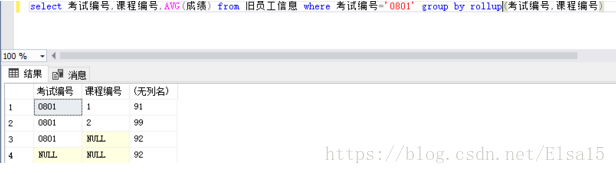
通过以上图片对比可看出
cube ,课程编号平均,考试编号平均,考试编号、课程编号平均
rollup ,考试编号平均,考试编号、课程编号平均
二、函数
对所查询的数据进行数学函数的计算,比如最高分
1、首先查出数据
2、如何查出这门课的最高分?使用MAx函数
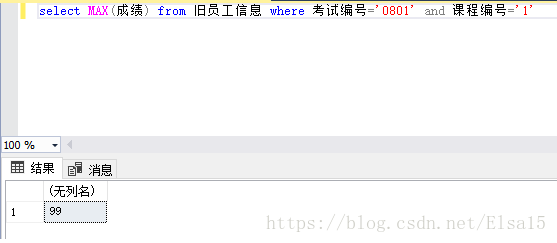
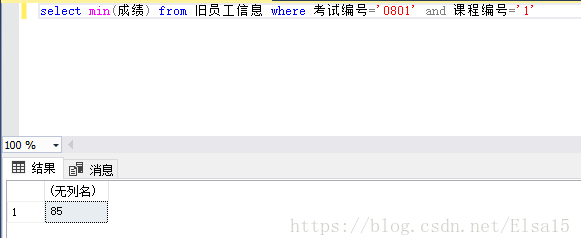
3、那么相应的最低分,平均值,分数求和都可以
MIN (),AVG(),sum()
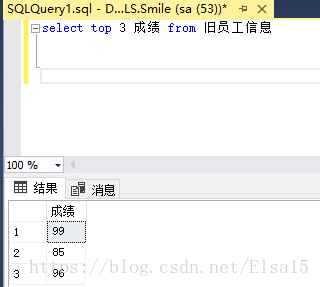
4、如何查出前三名?top函数
5、对前三名进行排序,降序或升序
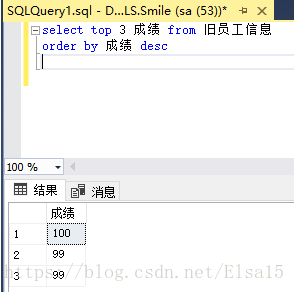
6、什么按照降序排完后数据不是之前的那top3当中的数据呢?
因为代码中的top3函数代表的只是对表格中的前三个,并未进行成绩的排序。

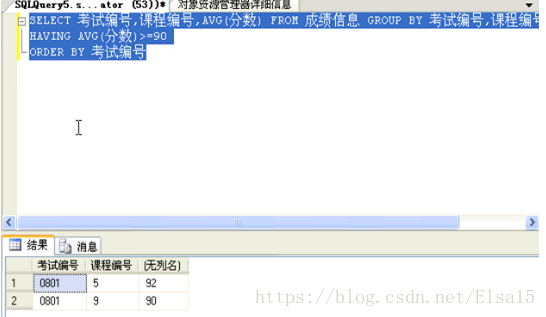
三、HAVING子句
HAVING子句的运行前提是有GROUP BY 语句,即此句是在GROUP BY语句的基础上运行的。
是对分组后数据的进一步筛选,比如从已分组的数据中筛选平均值大于90的数据,如下:
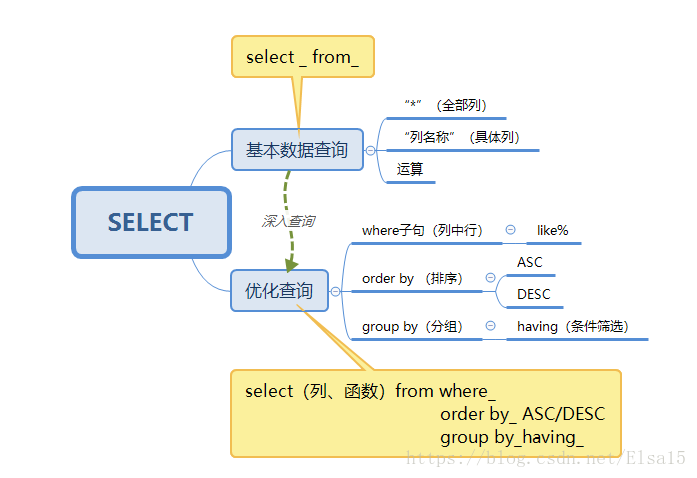
四、思维导图(在上篇博客内容的基础上拓展)
以上是对SQL语句中的GROUP BY 语句,函数,HAVING语句进行的简要梳理,如有错误之处,还望各位大神给予指导^_^