参考:
计算机如何区分是指令还是数据
https://zhidao.baidu.com/question/305357780899641564.html
按字寻址和按字节寻址
计算机组成原理(第二版)唐朔飞 P73
https://blog.csdn.net/lishuhuakai/article/details/8934540
https://blog.csdn.net/Xavier_97/article/details/72511186
https://blog.csdn.net/softfox/article/details/43890859
指令和数据均存放在内存中,计算机如何区分它们是指令还是数据?

通常完成一条指令可分为取指阶段、分析阶段和执行阶段。在取指阶段通过访问存储器可将指令取出;在执行阶段通过访问存储器可将操作数取出。这样,虽然指令和数据都是以0、1代码形式存在存储器中,但CPU可以判断出在取指阶段访存取出的0、1代码是指令;在执行阶段访存取出的0、1代码是数据。
计算机区分指令和数据有以下2种方法:
1. 通过不同的时间段来区分指令和数据,即在取指令阶段(或取指微程序)取出的为指令,在执行指令阶段(或相应微程序)取出的即为数据。
备注:在取指令时期,cpu通过指令流取指令,存放在指令寄存器, 然后解释并执行指令;在执行指令时期,cpu通过数据流取数据, 存放在数据寄存器。
2. 通过地址来源区分,由PC(程序计数器)提供存储单元地址的取出的是指令,由指令(指令=操作码+地址码)地址码部分提供存储单元地址的取出的是操作数。
**********************************************************************************************************
按字寻址和按字节寻址
我们先从一道简单的问题说起!
设有一个1MB容量的存储器,字长32位,问:按字节编址,字编址的寻址范围以及各自的寻址范围大小?
如果按字节编址,则
1MB = 2^20B
1字节=1B=8bit
2^20B/1B = 2^20
地址范围为0~(2^20)-1,也就是说需要二十根地址线才能完成对1MB空间的编码,所以地址寄存器为20位,寻址范围大小为2^20=1M
如果按字编址,则
1MB=2^20B
1字=32bit=4B
2^20B/4B = 2^18
地址范围为0~2^18-1,也就是说我们至少要用18根地址线才能完成对1MB空间的编码。因此按字编址的寻址范围是2^18
以上题目注意几点:
1.区分寻址空间与寻址范围两个不同的概念,寻址范围仅仅是一个数字范围,不带有单位
而寻址范围的大小很明显是一个数,指寻址区间的大小。
而寻址空间指能够寻址最大容量,单位一般用MB、B来表示;本题中寻址范围为0~(2^20)-1,寻址空间为1MB。
2.按字节寻址,指的是存储空间的最小编址单位是字节,按字编址,是指存储空间的最小编址单位是字,以上题为例,总的存储器容量是一定的,按字编址和按字节编址所需要的编码数量是不同的,按字编址由于编址单位比较大(1字=32bit=4B),从而编码较少,而按字节编址由于编码单位较小(1字节=1B=8bit),从而编码较多。
3.区别M和MB。
M为数量单位。1024=1K,1024K=1M
MB指容量大小。1024B=1KB,1024KB=1MB.
寻址就是寻找地址,当CPU请求数据的时候就会对进行读数据的请求。假设我们有一块硬盘,那么硬盘在接收到请求之后就开始查找这个CPU需求的数据具体是放在哪呢?实际上,硬盘上储存的所有数据都有一个自己的地址,在物理上实现是通过磁头在盘片上定位数据的一个过程。
主存各存储单元的空间位置由单元地址号来表示,而地址总线是用来指出存储单元地址号的,根据该地址可读出或写入一个存储字。不同的机器存储字长也不同,常用8位二进制数表示一个字节,因此存储字长都取8的倍数。
通常计算机既可按字寻址,也可按字节寻址。例如IBM370机的字长为32位,它可按字节寻址,即它的每一个存储字包含4个可独立寻址的字节。字地址是用该字高位字节的地址(高位字节所在的地址)来表示,故其字地址都是4的整数倍,正好用地址码的末两位来区分同一字的4个字节的位置。但对PDP-11机而言,其字长为16位,字地址是2的整数倍,它用低字节的地址来表示字地址。
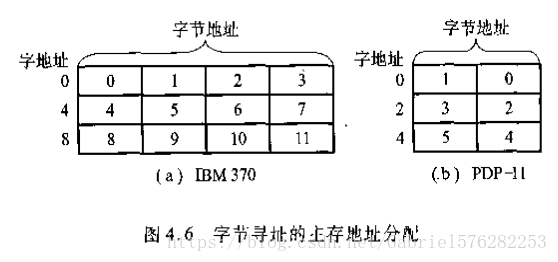
如图4.6(a)所示对24位地址线的主存而言,按字节寻址的范围是16M,按字寻址的范围为4M。由图4.6(b)所示,对24位地址线而言,按字节寻址的范围仍为16M,但按字寻址的范围为8M。
我的理解:
按字节寻址,就是每个字节都有1个地址,反过来说就是寻址范围内的每个地址(每个数字)都对应存储器中的1个字节,这里字节作为寻址的基本单位,所以寻址范围完全为地址线的宽度决定,例如24位地址线,按字节寻址的范围就是2^24=16M。
按字寻址,每个字有1个地址,这里的寻址范围除了地址线宽度以外,还跟字长有关。如果字长是32位,那么1个字就是4个字节。所以寻址范围就是“按字节寻址的寻址范围/4”,具体到地址线来说,如果地址线宽度是24位,按字寻址的寻址范围就是16M/4=4M,只需要占用地址线其中的22位,那么地址线剩余的两位用来做什么呢?正好用来区分同一字的4个字节的位置。由于1个字包含多个字节,所以字地址具体是由该字的高位字节的地址还是低位字节的地址来表示,由具体的机器自行决定。
同理,如果字长是16位,那么1个字就是2个字节。所以寻址范围就是“按字节寻址的寻址范围/2”,具体到地址线来说,如果地址线宽度是24位,按字寻址的寻址范围就是16M/2=8M,只需要占用地址线其中的23位,那么地址线剩余的一位用来做什么呢?正好用来区分同一字的2个字节的位置。
下面我们从三个例题来入手:
例1:设有一台机器有24根地址线,按字节寻址,求其寻址范围。
解:如果按照字节寻址,就是一个地址线表示的数(即状态)对应一个字节的地址。由此可以得到地址的范围(即状态总和)就是224224,即16M。
例2:设有一台机器有24根地址线,其字长为16位,按字寻址,求其寻址范围。
解:字里面封装了字节,为了确保每个字节或者说每个数据都有自己的一个编号,那么需要牺牲一部分地址线来实现。16位字长的机器,每个字表示2个字节,用1位地址线就能区分出来,这边可以类比成“每个袋子装了两个包子,而我现在只给袋子编号,那么你想要找到袋子里面的包子到底是第一个还是第二个就必须在拿出一位的0和1来表示第一个还是第二个包子”。由此表示字地址的数据线位数就只剩下了24-1=23位了。所以寻址的范围就变成了2^23,即4M了。
例3:设有一台机器有24根地址线,其字长为32位,按字寻址,求其寻址范围。
解:16M/4=4M