企业级大数据环境搭建
虚拟机仿真,与物理机设置完全相同
一:系统准备
1,在虚拟机中最小安装CENT OS7系统视自己电脑内存大小而定:
虚拟机内存设置1G~2G
CPU 1~4核心
硬盘20G~60G
2,设置虚拟机网络
查看虚拟机网络设置,记录网段和网关
禁用IPV6
编辑 /etc/defulat/grub
在第6行添加
ipv6.disable=1
保存
重新加载配置
grub2-mkconfig -o /boot/grub2/grub.cfg
重启
reboot
分配静态IP地址,编辑 /etc/sysconfig/network-scripts/ifcfg-网卡名
修改
BOOTPROTO=static
IPADDR=网段内静态IP
NETMASK=255.255.255.0
GATEWAY=记录的网关地址
DNS1=114.114.114.114
ONBOOT=yes
修改/etc/resolv.conf
添加
nameserver 114.114.114.114
systemctl restart network #重启网络服务
3,实现主机与虚拟机互访
4,添加用户,设置密码
adduser bda
passwd bda
之后reboot用bda登录
5,创建目录/opt下:software, modules, data, tools
更改所有权
sudo chown -R bda:bda /opt/*
6,如果有,卸载自带的Open-JDK
rpm -qa|grep java
rpm -e --nodeps 各 个 名 字
安装官方JDK
版本根据hadoop版本要求确定,此处用7u67
下载该版本JDK压缩包到 /opt/software
修改权限u+x
sudo chmod u+x 文件名
解压缩到/opt/moduls
tar -zxf 文件名 -C /opt/modules
配置JAVA_HOME
/etc/profile
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
二,集群准备
1,复制多份虚拟机分别设置静态IP
/etc/sysconfig/network-scripts/ifcfg-网卡名
机器名
/etc/hostname
彼此添加机器名和IP地址映射
/etc/hosts
实现虚拟机互访
2,实现SSH工具连接
配置sudo免密码
/etc/sudoers
bda ALL=(root)NOPASSWD:ALL
3,关闭防火墙
1, /etc/sysconfig/selinux
SELINUX=disabled
2,systemctl stop firewalld.service #停止firewall
3.systemctl disable firewalld.service #禁止firewall开机启动
4.firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running
三,安装HADOOP
1.2 修改host文件
我们希望三个主机之间都能够使用主机名称的方式相互访问而不是IP,我们需要在hosts中配置其他主机的host。因此我们在主机的/etc/hosts下均进行如下配置:

[root@node21 ~]# vi /etc/hosts 配置主机host 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.100.21 node21 192.168.100.22 node22 192.168.100.23 node23 将配置发送到其他主机(同时在其他主机上配置) [root@node21 ~]# scp -r /etc/hosts root@node22:/etc/ [root@node21 ~]# scp -r /etc/hosts root@node23:/etc/ 测试 [root@node21 ~]# ping node21 [root@node21 ~]# ping node22 [root@node21 ~]# ping node23
1.3 添加用户账号
在所有的主机下均建立一个账号admin用来运行hadoop ,并将其添加至sudoers中 [root@node21 ~]# useradd admin 添加用户通过手动输入修改密码 [root@node21 ~]# passwd admin 更改用户 admin 的密码 123456 passwd: 所有的身份验证令牌已经成功更新。 设置admin用户具有root权限 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示: [root@node21 ~]# visudo ## Allow root to run any commands anywhere root ALL=(ALL) ALL admin ALL=(ALL) ALL 修改完毕 :wq! 保存退出,现在可以用admin帐号登录,然后用命令 su - ,切换用户即可获得root权限进行操作。
1.4 /opt目录下创建文件夹
1)在root用户下创建module、software文件夹 [root@node21 opt]# mkdir module [root@node21 opt]# mkdir software 2)修改module、software文件夹的所有者 [root@node21 opt]# chown admin:admin module [root@node21 opt]# chown admin:admin software 3)查看module、software文件夹的所有者 [root@node21 opt]# ll total 0 drwxr-xr-x. 5 admin admin 64 May 27 00:24 module drwxr-xr-x. 2 admin admin 267 May 26 11:56 software
2 安装配置jdk1.8
[deng@node21 ~]# rpm -qa|grep java #查询是否安装java软件: [deng@node21 ~]# rpm -e –nodeps 软件包 #如果安装的版本低于1.7,卸载该jdk 在线安装 wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-linux-x64.tar.gz 这里使用本地下载然后 xftp上传到 /opt/software/ 下 [root@node21 software]# tar zxvf jdk-8u171-linux-x64.tar.gz -C /opt/module/ [root@node21 module]# mv jdk1.8.0_171 jdk1.8 设置JAVA_HOME vi /etc/profile export JAVA_HOME=/opt/module/jdk1.8 export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/sbin source /etc/profile 向其他节点复制jdk [root@node21 ~]# scp -r /opt/module/jdk1.8 root@node22:`pwd` [root@node21 ~]# scp -r /opt/module/jdk1.8 root@node23:`pwd` 配置各个主机下jdk的环境变量,由于我的电脑上linux都是新安装的,环境变量相同,因此直接复制到了其他主机上。如果不同的主机的环境变量不同,请手动设置 [root@node21 ~]# scp /etc/profile root@node22:/etc/ [root@node21 ~]# scp /etc/profile root@node23:/etc/ 在每个主机上都重新编译一下/etc/profile [root@node21]# source /etc/profile 测试 java -version
3 设置SSH免密钥
关于ssh免密码的设置,要求每两台主机之间设置免密码,自己的主机与自己的主机之间也要求设置免密码。 这项操作可以在admin用户下执行,执行完毕公钥在/home/admin/.ssh/id_rsa.pub
[admin@node21 ~]# ssh-keygen -t rsa [admin@node21 ~]# ssh-copy-id node21 [admin@node21 ~]# ssh-copy-id node22 [admin@node21 ~]# ssh-copy-id node23
node1与node2为namenode节点要相互免秘钥 HDFS的HA
[admin@node22 ~]# ssh-keygen -t rsa [admin@node22 ~]# ssh-copy-id node22 [admin@node22 ~]# ssh-copy-id node21 [admin@node22 ~]# ssh-copy-id node23
node2与node3为yarn节点要相互免秘钥 YARN的HA
[admin@node23 ~]# ssh-keygen -t rsa [admin@node23 ~]# ssh-copy-id node23 [admin@node23 ~]# ssh-copy-id node21 [admin@node23 ~]# ssh-copy-id node22
4 安装hadoop集群
4.1 解压安装hadoop
[admin@node21 software]# tar zxvf hadoop-2.7.6.tar.gz -C /opt/module/
4.2 hadoop集群部署规划
| 节点名称 | NN1 | NN2 | DN | RM | NM |
| node21 | NameNode | DataNode | NodeManager | ||
| node22 | SecondaryNameNode | DataNode | ResourceManager | NodeManager | |
| node23 | DataNode | NodeManager |
5 配置hadoop集群
注意:配置文件在hadoop2.7.6/etc/hadoop/下
5.1 修改core-site.xml
[admin@node21 hadoop]$ vi core-site.xml <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://node21:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.6/data/full/tmp</value> </property> </configuration>
5.2 修改hadoop-env.sh
[admin@node21 hadoop]$ vi hadoop-env.sh 修改 export JAVA_HOME=/opt/module/jdk1.8
5.3 修改hdfs-site.xml
[admin@node21 hadoop]$ vi hdfs-site.xml <configuration> <!-- 设置dfs副本数,不设置默认是3个 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 设置secondname的端口 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node22:50090</value> </property> </configuration>
5.4 修改slaves
[admin@node21 hadoop]$ vi slaves
node21
node22
node23
5.5 修改mapred-env.sh
[admin@node21 hadoop]$ vi mapred-env.sh 修改 export JAVA_HOME=/opt/module/jdk1.8
5.6 修改mapred-site.xml
[admin@node21 hadoop]# mv mapred-site.xml.template mapred-site.xml [admin@node21 hadoop]$ vi mapred-site.xml <configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.7 修改yarn-env.sh
[admin@node21 hadoop]$ vi yarn-env.sh 修改 export JAVA_HOME=/opt/module/jdk1.8
5.8 修改yarn-site.xml
[admin@node21 hadoop]$ vi yarn-site.xml
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node22</value>
</property>
</configuration>
5.9 分发hadoop到节点
[admin@node21 module]# scp -r hadoop-2.7.6/ admin@node22:`pwd` [admin@node21 module]# scp -r hadoop-2.7.6/ admin@node23:`pwd`
5.10 配置环境变量
[admin@node21 ~]$ sudo vi /etc/profile 末尾追加 export HADOOP_HOME=/opt/module/hadoop-2.7.6 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 编译生效 source /etc/profile
6 启动验证集群
6.1 启动集群
如果集群是第一次启动,需要格式化namenode
[admin@node21 hadoop-2.7.6]$ hdfs namenode -format

启动Hdfs:
[admin@node21 ~]# start-dfs.sh Starting namenodes on [node21] node21: starting namenode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-root-namenode-node21.out node21: starting datanode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-root-datanode-node21.out node22: starting datanode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-root-datanode-node22.out node23: starting datanode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-root-datanode-node23.out Starting secondary namenodes [node22] node22: starting secondarynamenode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-root-secondarynamenode-node22.out
启动Yarn: 注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
[admin@node22 ~]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.7.6/logs/yarn-root-resourcemanager-node22.out node21: starting nodemanager, logging to /opt/module/hadoop-2.7.6/logs/yarn-root-nodemanager-node21.out node23: starting nodemanager, logging to /opt/module/hadoop-2.7.6/logs/yarn-root-nodemanager-node23.out node22: starting nodemanager, logging to /opt/module/hadoop-2.7.6/logs/yarn-root-nodemanager-node22.out
jps查看进程
[admin@node21 ~]# jps 1440 NameNode 1537 DataNode 1811 NodeManager 1912 Jps [admin@node22 ~]# jps 1730 Jps 1339 ResourceManager 1148 DataNode 1198 SecondaryNameNode 1439 NodeManager [admin@node23 ~]# jps 1362 Jps 1149 DataNode 1262 NodeManager
web页面访问
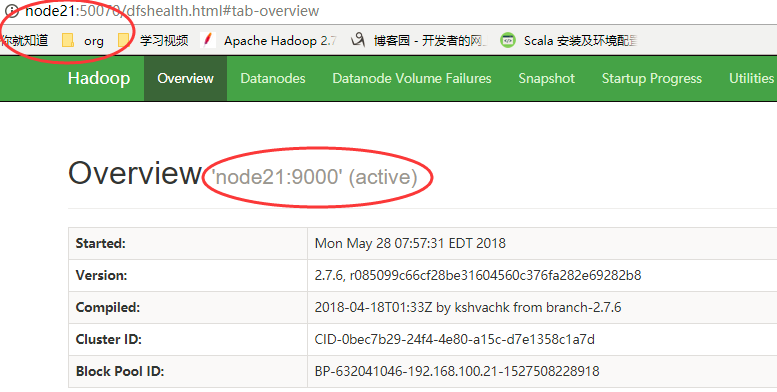
6.2 Hadoop启动停止方式
1)各个服务组件逐一启动 分别启动hdfs组件: hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode 启动yarn:yarn-daemon.sh start|stop resourcemanager|nodemanager 2)各个模块分开启动(配置ssh是前提)常用 start|stop-dfs.sh start|stop-yarn.sh 3)全部启动(不建议使用) start|stop-all.sh