- 正交化(orthogonlization)
每个算法、技巧只解决一个问题,而不要对很多方面都产生影响。
早停(early stopping)既影响对训练集的训练,又对验证集有提高。
- 单一数字评估指标(single number evaluation metric)
以一个指标作为最终优化的指标。 满意指标与优化指标(satisficing and optimizing metric)
选择一个指标作为优化指标,其他指标只要达到一定阈值就算满意。以手机唤醒词为例,优化指标为准确率,而假阳性情况(即不是说唤醒词是手机被唤醒)只要低于一天一次的频率就是可以的。保持验证集与测试集分布的一致性
可以将验证集与指标比喻成靶子与靶心,而把分布不一致的测试集当作另一个靶子,通过训练训练集可以使模型对验证集的靶心越来越准,但测试集上的效果却不一定很好。数据集分割(splitting data)
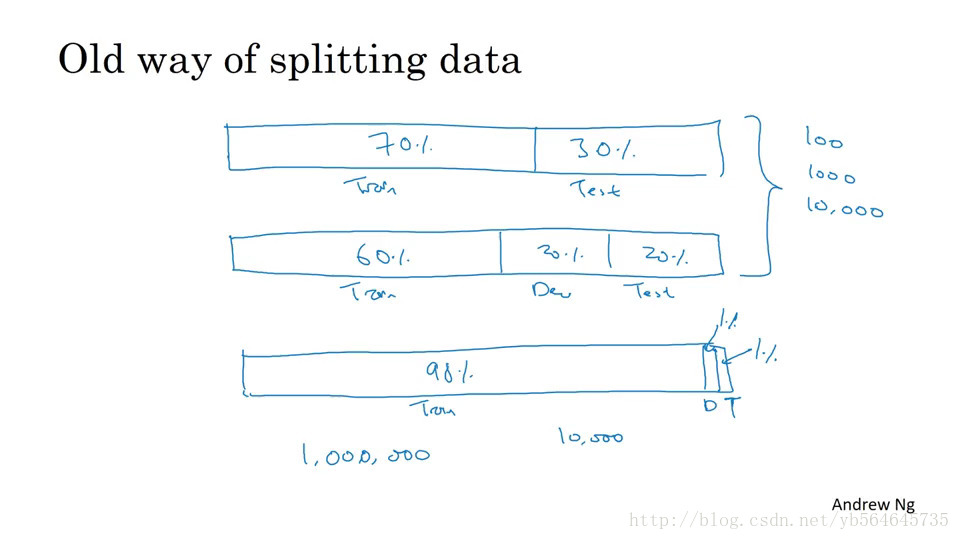
小数据集时可以采用类似60/20/20的分割方式,但当数据很多时应将大部分都分如训练集。没有测试集也是可以的,但不推荐。
评价指标可能需要改变,在给用户推送猫照片时,将准确率作为评估指标是不合适的,因为用户难以容忍出现黄图,因此此时需要改变评估指标。
bayes optimal error(理论最高准确率) and human level performance
natural data -图像、语音
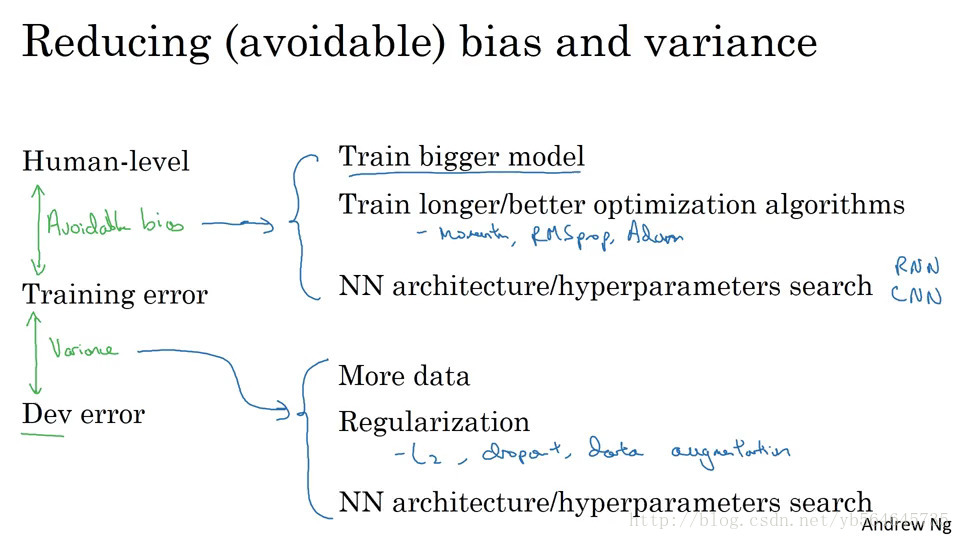
对改进bias还是variance的选择
- 错误问题记录
第 14 个问题
You’ve handily beaten your competitor, and your system is now deployed in Peacetopia and is protecting the citizens from birds! But over the last few months, a new species of bird has been slowly migrating into the area, so the performance of your system slowly degrades because your data is being tested on a new type of data.
使用已有的数据定义考虑新品种鸟的评估指标。
coursera deep learning course3 week1



猜你喜欢
转载自blog.csdn.net/yb564645735/article/details/78820535
今日推荐
周排行