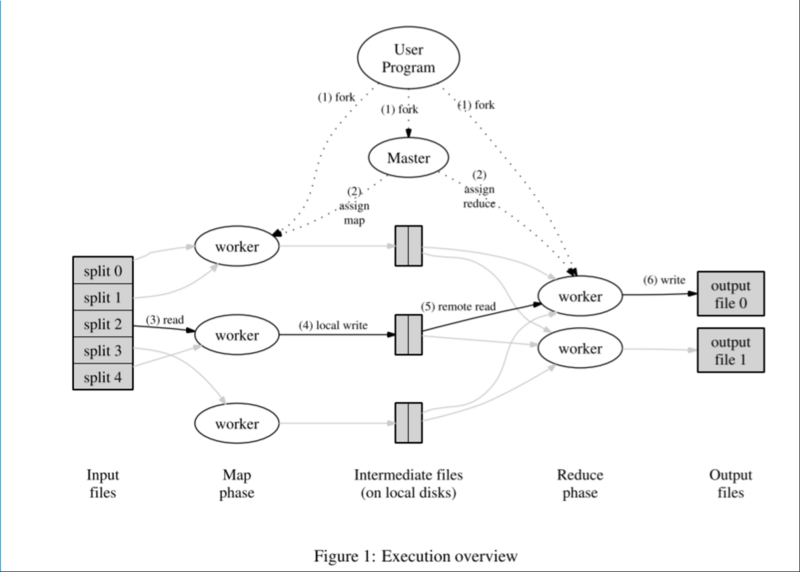
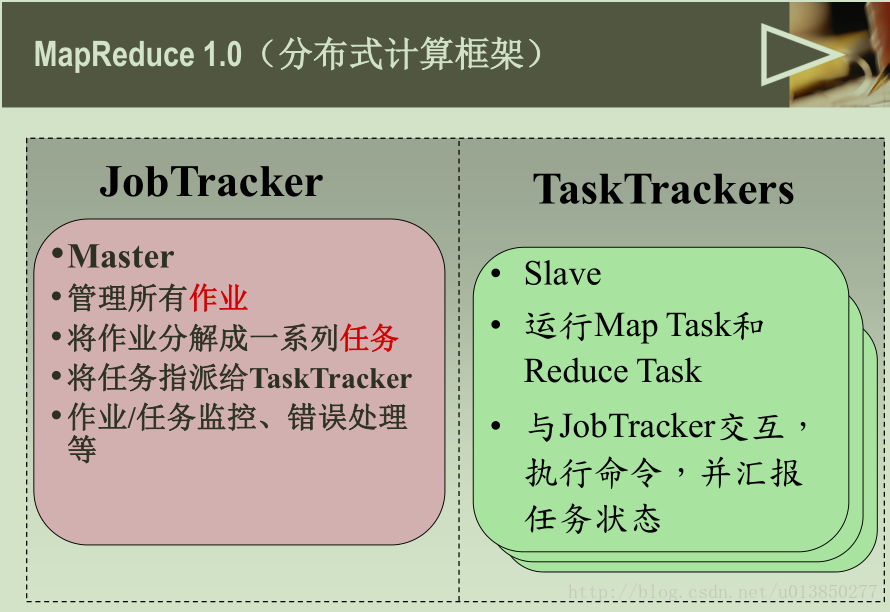
框架中有两类节点(也可以说是进程),Master和Worker,当用户提交一个计算作业(Job)的时候,会启动Job唯一对应的Master进程,Master进程负责整个Job的调度,包括分配worker的角色(map或者reduce)、worker计算的数据,以及向用户返回结果等等。而Worker负责的具体计算称之为task,在MapReduce框架下,worker按照计算的阶段又分为map worker和reduce worker,worker在master获取计算任务,然后在文件系统读取数据进行运算,并将结果写入到临时文件或者持久化文件系统。
一个Job的流程是这样的
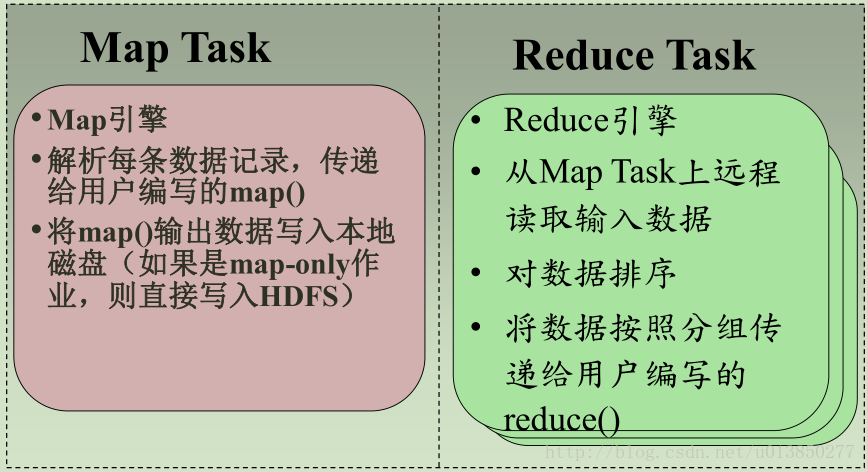
- MapReduce将待运算的数据分为M份,每一份的大小为16M或者64M(这个跟默认使用的分布式文件系统GFS有关),每一份数据称之为一个split
- 启动M个map worker,读取相应的split,然后调用用户的Map function,对数据进行运算
- map worker周期性将计算结果(称之为中间结果)写入到R份本地文件中的其中一份,R是reduce worker的数量,具体写入哪一个临时文件 规则由Partitioning function指定
- 当一个map worker计算任务完成的时候,将R份中间结果的位置通知master,master通知对应的reduce worker
- reduce worker根据中间结果的位置,通过rpc从map worker上获取与自己对应的中间结果,进行计算,并将计算结果写入到持久化分布式文件系统,
- 当所有map reduce worker的计算任务结束之后,通知用户计算结果
当然,一个mapreduce的结果并不一定直接给用户,很有可能是一个链式(chain)计算,即将一个mapreduce的输出当做另一个mapreduce的输入
MapTask执行的Timeline
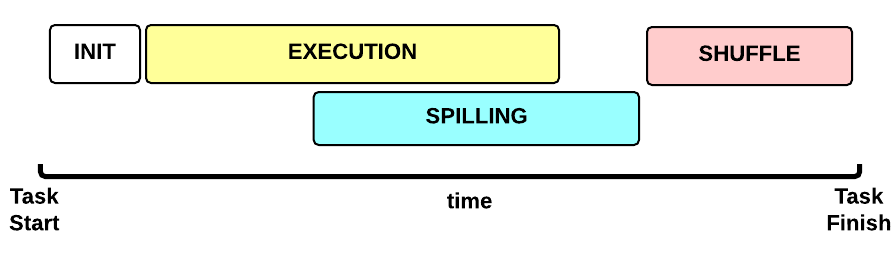
这是Map Task任务执行时间线:
- 初始化(INIT)阶段:初始化Map Task(默认是什么都没有。。)
- 执行(EXECUTION)阶段: 对于每个 (key, value)执行map()函数
- 排序(SPILLING)阶段:map输出会暂存到内存当中排序,当缓存达到一定程度时会写到磁盘上,并删除内存里的数据
- SHUFFLE 阶段:排序结束后,会合并所有map输出,并分区传输给reduce。

Shuffle阶段
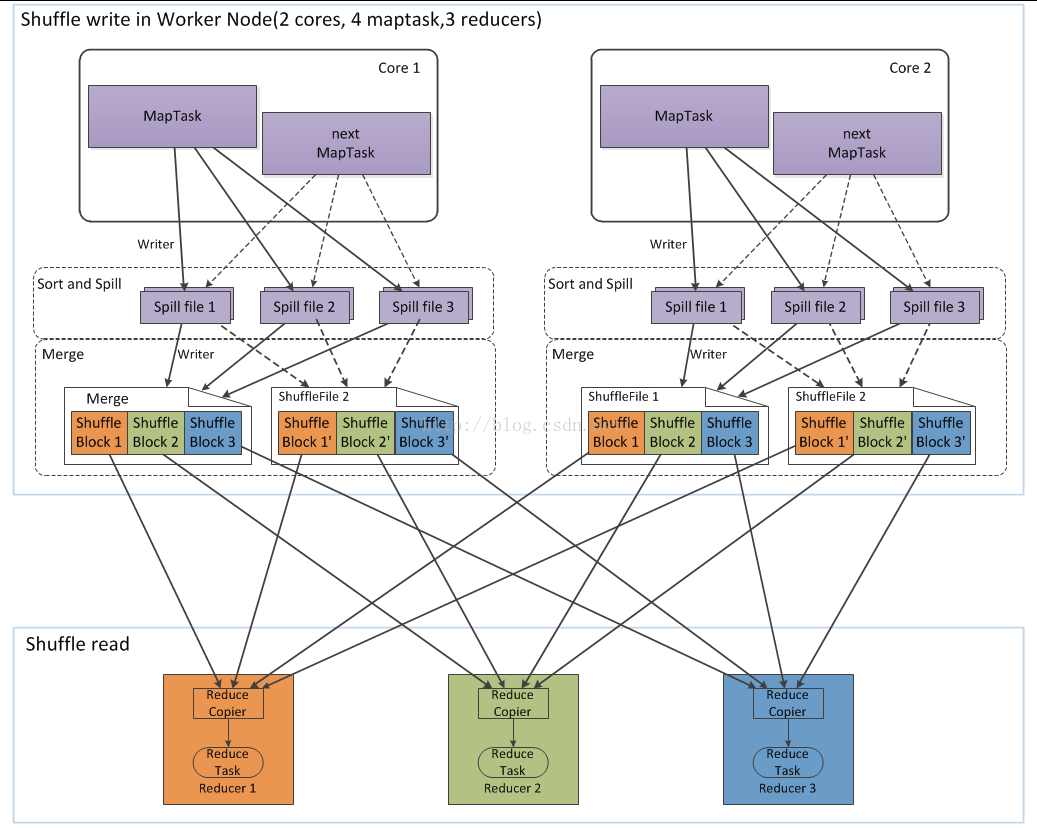
shuffle阶段主要是做数据的排序和合并操作,然后把数据存到本地文件系统上,等待Reduce来获取数据。等到所有的MapTask产出的数据传输都Reduce机器上,并对数据进行排序以后才能算是Shuffle过程的结束。也就说从Map函数出来之后到Reduce函数之前的所有数据操作都叫Shuffle操作,包括排序、合并、分区、传输等。
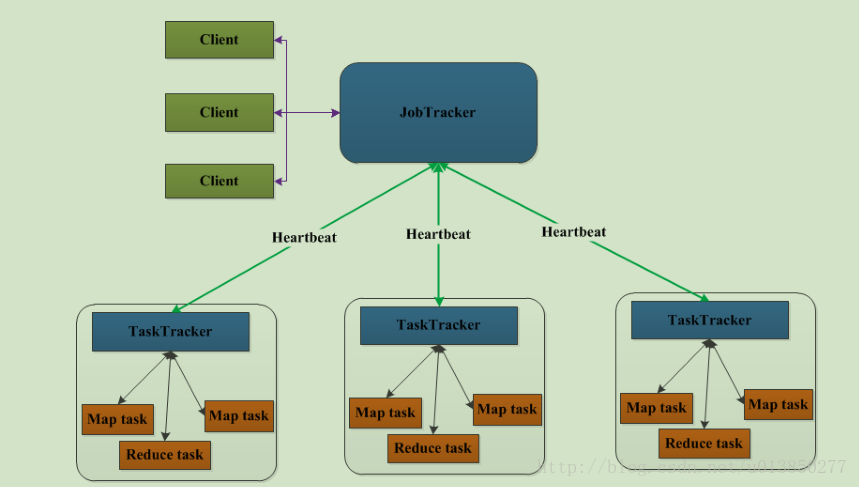
很好的设计值得学习借鉴。
data locality,即计算离需要的数据存储越近越好,以尽量避免网络传输
fault tolerance,分布式系统中,节点故障是常态,运行环境需要对用户透明地监控、处理故障。由于mapreduce编程模型的线性无状态特性,对于某一个worker的故障,只需将计算任务给其他worker负责就行
backup task,按照木桶定律,即一只水桶能装多少水取决于它最短的那块木板,在mapreduce中,运行最为缓慢的worker会成为整个Job的短板。运行环境需要监控到异常缓慢的worker,主动将其上的task重新调度到其他worker上,以便在合理的时间结束整个Job,提高系统的吞吐。
partitioning function & combiner function,这是用户可以提供的另外两个算子,实时上也是非常有用的。map worker的中间结果,通过partitioning function分发到R(R为reducer的数目)位本地文件,默认为“hash(key) mod R”。而Combiner function是对每一个map worker的结果先进行一次合并(partial merge),然后再写入本地文件,以减少数据传输,较少reduce worker的计算任务。
不足或者没有考虑到的点
第一:master是单点,故障恢复依赖于周期性的checkpoint,不保证可靠性,因此发生故障的时候会通知用户,用户自行决定是否重新计算。
第二:没有提到作业(Job)的调度策略,运行时环境肯定是有大量的Job并发的,因此多样且高效的调度策略是非常重要的,比如按优先级、按群组
第三:并没有提到资源(CPU、内存、网络)的调度,或者说并不区分作业调度与资源调度。
第四:没有提到资源隔离与安全性,大量Job并发的时候,如何保证单个Job不占用过多的资源,如何保证用户的程序对系统而言是安全的,在论文中并没有提及
第五:计算数据来源于文件系统,效率不是很高,不过本来就是用于离线任务,这个也不是什么大问题
Yarn与MapReduce交互(MapReduce2.0)的架构如下:
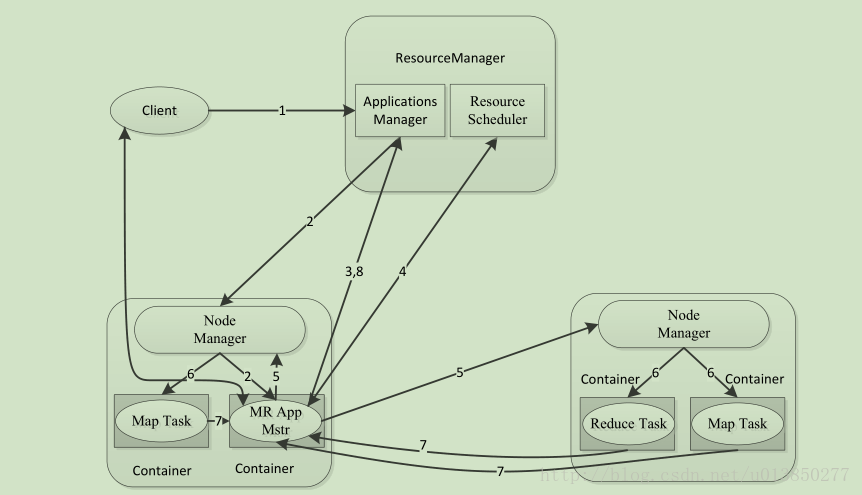
在Yarn中,有以下组件
ResourceManager:资源管理器,接收用户的请求,负载应用(application)的调度管理,启动应用对应的ApplicationMaseter,并为每一个应用分配所需的资源
NodeManager:每台机器上的框架代理(framework agent),在每一个计算机节点上都有一个,用于本机上的Container,监控机器的资源使用情况,并向ResourceManager汇报
ApplicationMaseter(图中所有为App Mstr),每一个应用都有自己唯一的ApplicationMaseter,用于管理应用的生命周期,向ResourceMananger申请资源,监控任务对应的container
Containner:具体任务task的计算单元,是一组资源的抽象,可用于以后实现资源的隔离。它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。目前为止,YARN仅支持CPU和内存两种资源,且使用了轻量级资源隔离机制Cgroups进行资源隔离。
功能: 对task环境的抽象、描述一系列信息、任务运行资源的集合(cpu、内存、io等)、任务运行环境
其中,ResourceManager包含两个重要的组件,scheduler和ApplicationManager。scheduler负责为各种应用分配资源,支持各种调度算法,如 CapacityScheduler、 FairScheduler。ApplicationManager负责接收用于的请求,启动应用对应的ApplicationMaseter。
YARN:应用程序启动
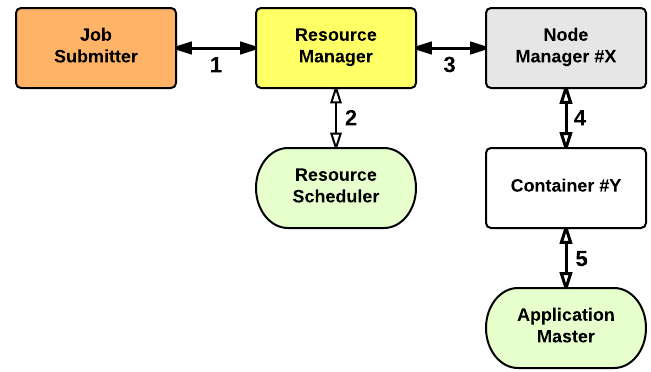
在YARN,至少有三个演员:
- 将任务提交(客户端)
- 所述资源管理器(主设备)
- 所述节点管理器(从设备)
应用程序启动过程如下:
- 客户端将应用程序提交给资源管理器
- 资源管理器分配容器
- 资源管理器联系相关的节点管理器
- 节点管理器启动容器
- Container执行Application Master
ResourceSchedule调度器的选择
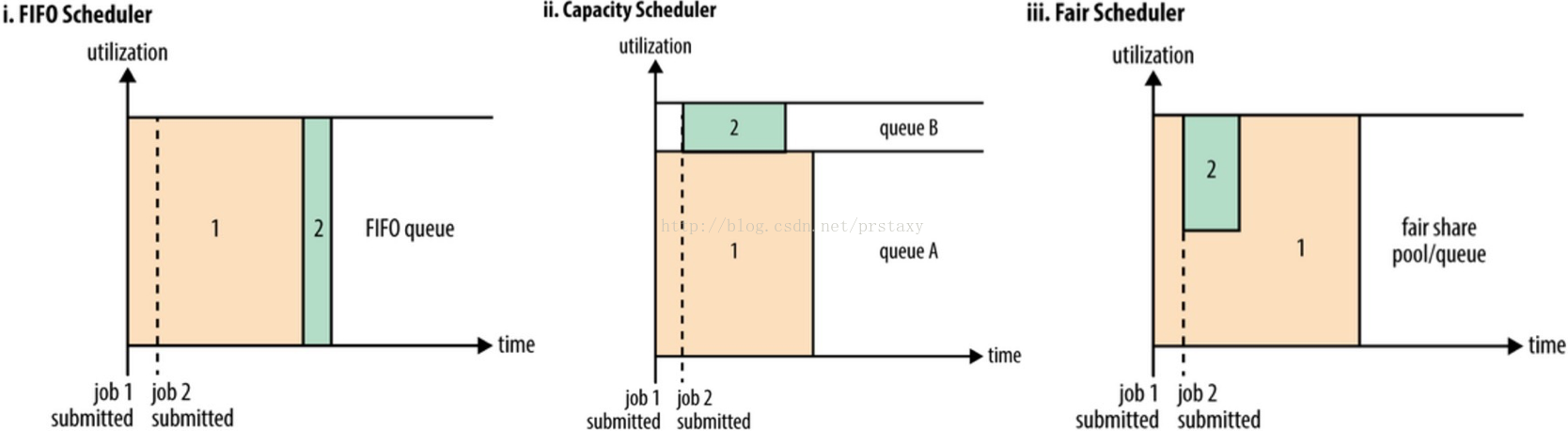
在YARN中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
FIFO Scheduler把应用按提交的顺序排成一个队列,是一个先进先出队列,在进行资源分配的时候,先给队列中最头部的应用进行分配资源,待最头部的应用需求满足后再给下一个分配,以此类推。FIFO Scheduler是最简单也是最容易理解的调度器,它不需要任何配置,但不适用于共享集群中。大的应用可能会占用所有集群资源,从而导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
下面“YARN调度器对比图”展示了这几个调度器的区别,从图中可以看出,在FIFO调度器中,小任务会被大任务阻塞。而对于Capacity调度器,设置了一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。在Fair调度器中,不需要预先保留一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
Yarn调度器对比图:
YARN的资源管理
1、资源调度和隔离是yarn作为一个资源管理系统,最重要且最基础的两个功能。资源调度由resourcemanager完成,而资源隔离由各个nodemanager实现。
2、Resourcemanager将某个nodemanager上资源分配给任务(这就是所谓的“资源调度”)后,nodemanager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础和保证,这就是所谓的资源隔离。
3、当谈及到资源时,我们通常指内存、cpu、io三种资源。Hadoop yarn目前为止仅支持cpu和内存两种资源管理和调度。
4、内存资源多少决定任务的生死,如果内存不够,任务可能运行失败;相比之下,cpu资源则不同,它只会决定任务的快慢,不会对任务的生死产生影响。
Yarn的内存管理:
yarn允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上内存会被若干个服务贡享,比如一部分给了yarn,一部分给了hdfs,一部分给了hbase等,yarn配置的只是自己可用的,配置参数如下:
yarn.nodemanager.resource.memory-mb
表示该节点上yarn可以使用的物理内存总量,默认是8192m,注意,如果你的节点内存资源不够8g,则需要调减这个值,yarn不会智能的探测节点物理内存总量。
yarn.nodemanager.vmem-pmem-ratio
任务使用1m物理内存最多可以使用虚拟内存量,默认是2.1
yarn.nodemanager.pmem-check-enabled
是否启用一个线程检查每个任务证使用的物理内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.nodemanager.vmem-check-enabled
是否启用一个线程检查每个任务证使用的虚拟内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.scheduler.minimum-allocation-mb
单个任务可以使用最小物理内存量,默认1024m,如果一个任务申请物理内存量少于该值,则该对应值改为这个数。
yarn.scheduler.maximum-allocation-mb
单个任务可以申请的最多的内存量,默认8192m
Yarn cpu管理:
目前cpu被划分为虚拟cpu,这里的虚拟cpu是yarn自己引入的概念,初衷是考虑到不同节点cpu性能可能不同,每个cpu具有计算能力也是不一样的,比如,某个物理cpu计算能力可能是另外一个物理cpu的2倍,这时候,你可以通过为第一个物理cpu多配置几个虚拟cpu弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟cpu个数。在yarn中,cpu相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上yarn可使用的虚拟cpu个数,默认是8个,注意,目前推荐将该值为与物理cpu核数相同。如果你的节点cpu合数不够8个,则需要调减小这个值,而yarn不会智能的探测节点物理cpu总数。
yarn.scheduler.minimum-allocation-vcores
单个任务可申请最小cpu个数,默认1,如果一个任务申请的cpu个数少于该数,则该对应值被修改为这个数
yarn.scheduler.maximum-allocation-vcores
单个任务可以申请最多虚拟cpu个数,默认是32.