HDFS 系统架构图
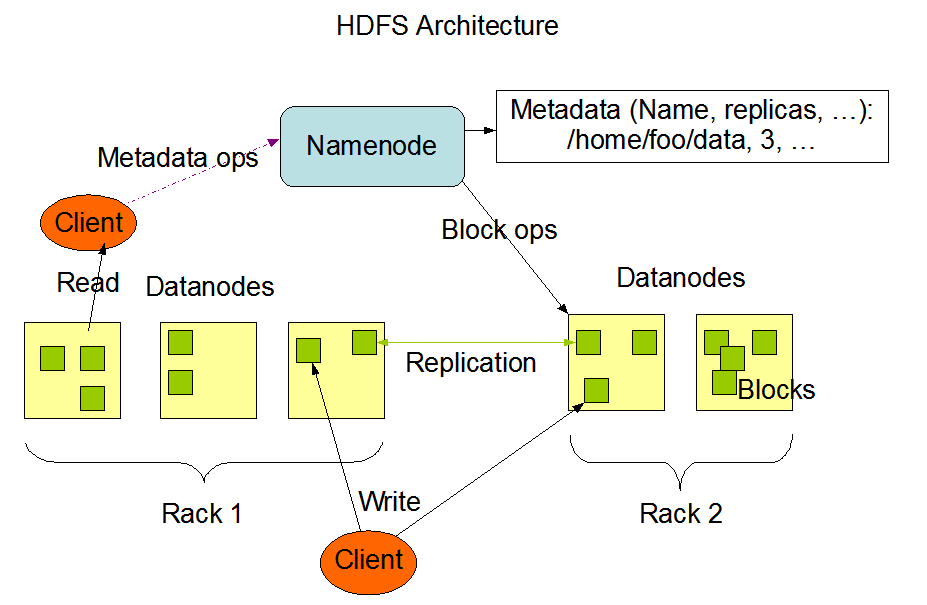
NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。NameNode将这些信息加载到内存并进行拼装,就成为了一个完整的元数据信息
DataNode在本地文件系统存储文件块数据,以及块数据的校验
Secondary NameNode(上图没有显示出来)用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
HDFS的基本存储单元(block),文件在HDFS上被分成若干个block块,, 默认的bocksize=128M , 若文件258M,则共有block=3,实际占有存储258M,最后一块只占用2M。如果设置的副本数为3的话,则整个集群上存在9个block,放置位置随机。
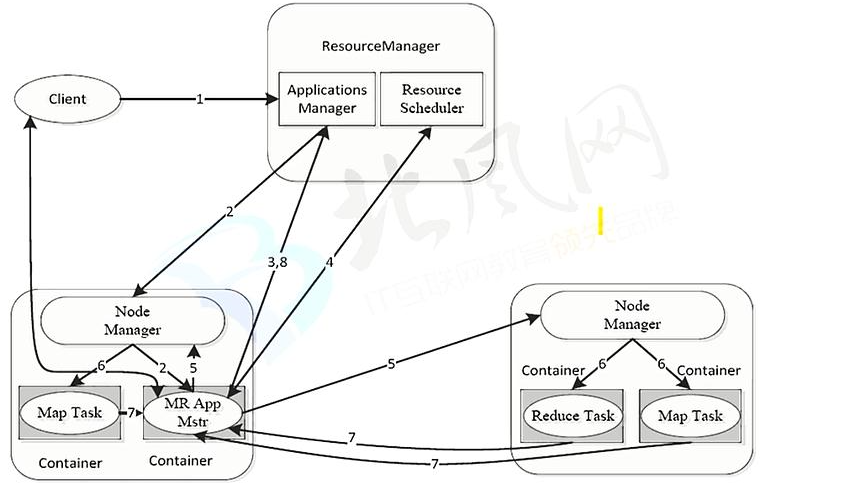
YARN 架构图
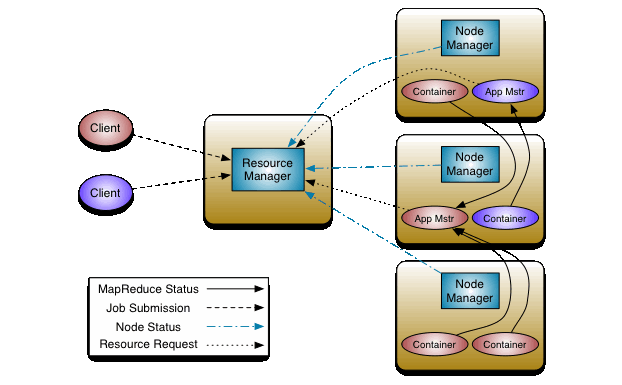
ResourceManager:
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配和调度
NodeManager:
单个节点上的资源管理n
处理来自ResouceManager 的命令
处理来自ApplicationMaster的命令
ApplicationMaster:
数据切分
为应用程序申请资源,并分配给内部任务
任务监控与容错
Container:
对任务运行环境的抽象,封装了CPU,内存等多维资源以及环境变量,启动命令等任务运行相关的信息
离线计算框架 MapReduce
将计算过程分为两个阶段,Map和Reduce
*Map 阶段并行处理输入数据
*Reduce 阶段对Map结果进行汇总
Shuffle 连接Map和Reduce 两个阶段
*Map Task 将数据写到本地磁盘
*Reduce Task从每个Map Task 上读取一份数据
仅适合离线批处理
*具有很好的容错性和扩展性
*适合简单的批处理任务
缺点明显
*启动开销大,过多使用磁盘导致效率低下等
mapReduce 运行原理参考以下博文:
https://www.cnblogs.com/sharpxiajun/p/3151395.html
MapReduce On Yarn