1、HDFS分布式存储
namenode:统一管理文件的元数据信息
fsImage:存储了文件的基本信息,如文件路径,文件副本集个数,文件块的信息,文件所在的主机信息。
editslog:存了客户端对hdfs中各种写操作的日志(指令);
secondaryNamenode:协助namenode完成fsimage和editlog的合并(定期合并)。
合并周期:1、每隔1小时合并一次 2、当editlog文件大小超过64M,立刻合并
datanode:负责存储真实的数据。
block:存储数据的基本单位,默认128M。

2、yarn框架

yarn的工作流程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是启动ApplicationMaster;
第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
具体流程如下:
步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
步骤2ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
3、mapreduce中wordcount原理图
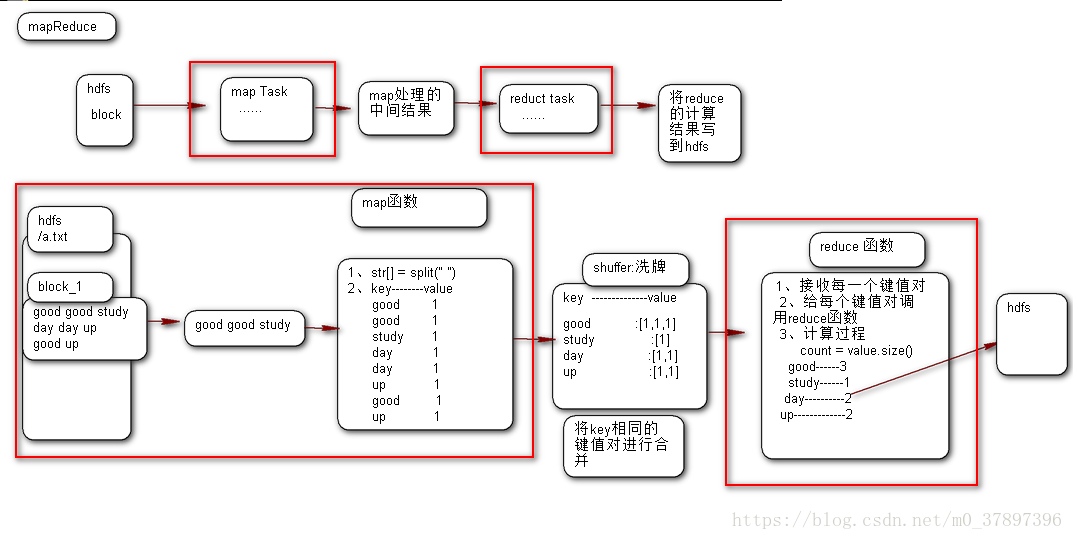
把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果
mapreduce开发主要是开发map、reduce函数。