Hadoop 3个核心组件:
分布式文件系统:Hdfs——实现将文件分布式存储在很多的服务器上(hdfs是一个基于Linux本地文件系统上的文件系统)
分布式运算编程框架:Mapreduce——实现在很多机器上分布式并行运算
分布式资源调度平台:Yarn——帮用户调度大量的mapreduce程序,并合理分配运算资源
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
HDFS的关键元素:
1、Block:将一个文件进行分块,通常是64M。
2、NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一 一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在 Hadoop2.* 开始支持 activity-standy 模式----如果主 NameNode 失效,启动备用主机运行 NameNode。
3、DataNode:分布在廉价的计算机上,用于存储Block块文件。
如果你想了解大数据的学习路线,想学习大数据知识以及需要免费的学习资料可以加群:784789432.欢迎你的加入。每天下午三点开直播分享基础知识,晚上20:00都会开直播给大家分享大数据项目实战。
一、HDFS运行原理
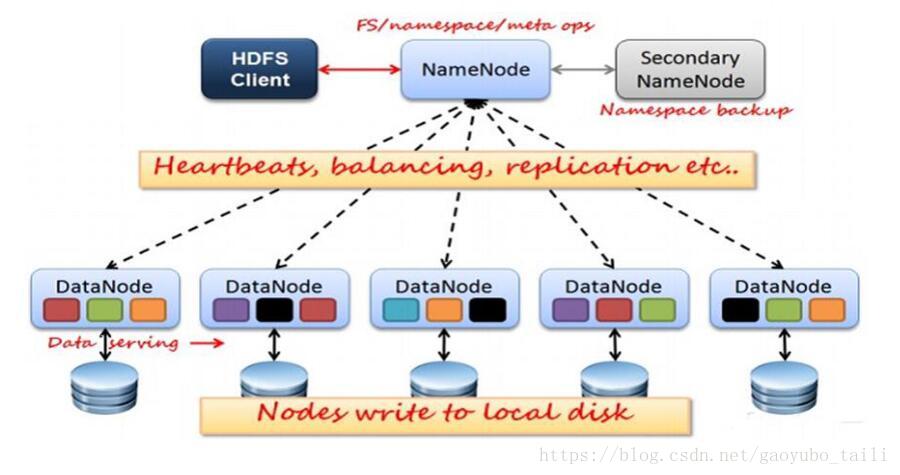
1、NameNode和DataNode节点初始化完成后,采用RPC进行信息交换,采用的机制是心跳机制,即DataNode节点定时向NameNode反馈状态信息,反馈信息如:是否正常、磁盘空间大小、资源消耗情况等信息,以确保NameNode知道DataNode的情况;
2、NameNode会将子节点的相关元数据信息缓存在内存中,对于文件与Block块的信息会通过fsImage和edits文件方式持久化在磁盘上,以确保NameNode知道文件各个块的相关信息;
3、NameNode负责存储fsImage和edits元数据信息,但fsImage和edits元数据文件需要定期进行合并,这时则由SecondNameNode进程对fsImage和edits文件进行定期合并,合并好的文件再交给NameNode存储。
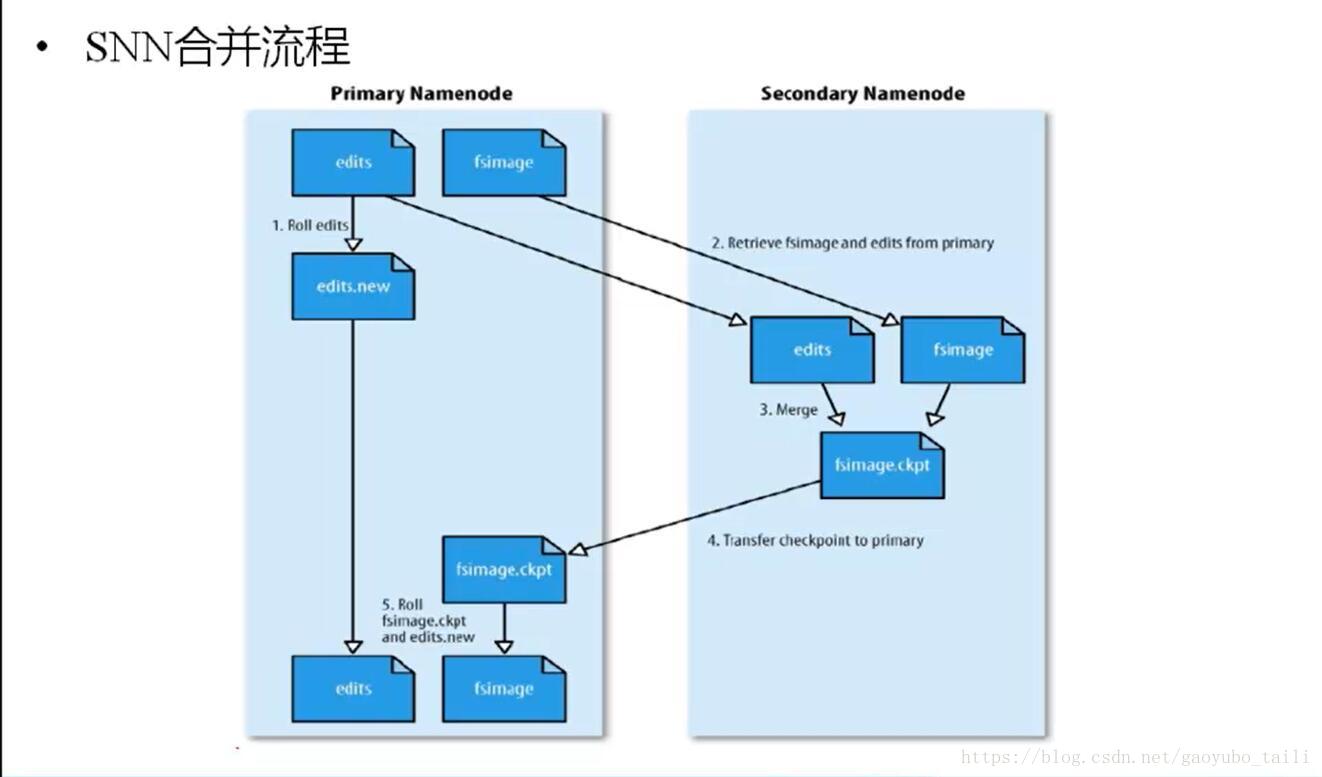
二、HDFS数据合并原理
1、NameNode初始化时会产生一个edits文件和一个fsimage文件,edits文件用于记录操作日志,比如文件的删除或添加等操作信息,fsImage用于存储文件与目录对应的信息以及edits合并进来的信息,即相当于fsimage文件在这里是一个总的元数据文件,记录着所有的信息;
2、随着edits文件不断增大,当达到设定的一个阀值的时候,这时SecondaryNameNode会将edits文件和fsImage文件通过采用http的方式进行复制到SecondaryNameNode下(在这里考虑到网络传输,所以一般将NameNode和SecondaryNameNode放在相同的节点上,这样就无需走网络带宽了,以提高运行效率),同时NameNode会产生一个新的edits文件替换掉旧的edits文件,这样以保证数据不会出现冗余;
3、SecondaryNameNode拿到这两个文件后,会在内存中进行合并成一个fsImage.ckpt的文件,合并完成后,再通过http的方式将合并后的文件fsImage.ckpt复制到NameNode下,NameNode文件拿到fsImage.ckpt文件后,会将旧的fsimage文件替换掉,并且改名成fsimage文件。
通过以上几步则完成了edits和fsimage文件的合并,依此不断循环,从而到达保证元数据的正确性。
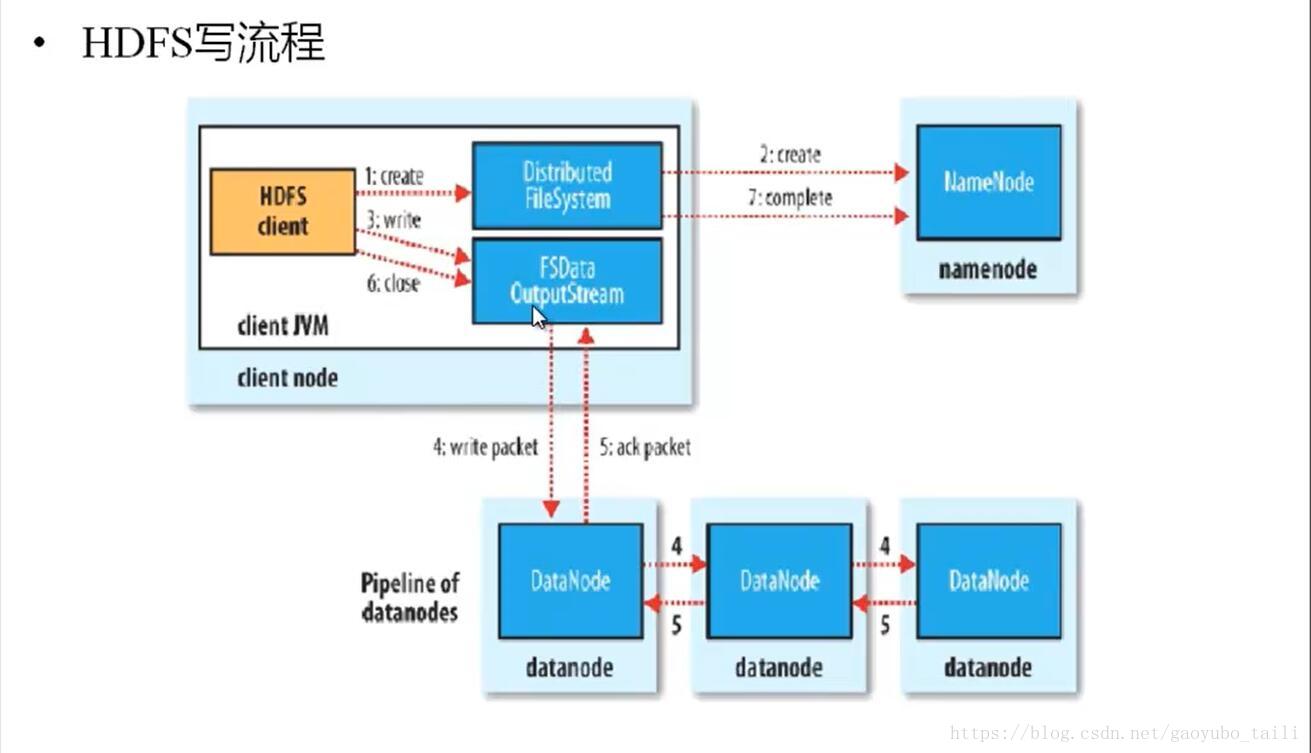
三、HDFS写原理
1、HDFS客户端提交写操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有写权限,如果有,然后进行查看,看哪几个DataNode适合存放,再给客户端返回存放数据块的节点信息,即告诉客户端可以把文件存放到相关的DataNode节点下;
2、客户端拿到数据存放节点位置信息后,会和对应的DataNode节点进行直接交互,进行数据写入,由于数据块具有副本replication,在数据写入时采用的方式是先写第一个副本,写完后再从第一个副本的节点将数据拷贝到其它节点,依次类推,直到所有副本都写完了,才算数据成功写入到HDFS上,副本写入采用的是串行,每个副本写的过程中都会逐级向上反馈写进度,以保证实时知道副本的写入情况;
3、随着所有副本写完后,客户端会收到数据节点反馈回来的一个成功状态,成功结束后,关闭与数据节点交互的通道,并反馈状态给NameNode,告诉NameNode文件已成功写入到对应的DataNode。
代码实现
-
/*
-
* 测试HDFS写入数据
-
*/
-
-
public void Test1() throws IOException {
-
// 加载配置文件
-
Configuration conf = new Configuration();
-
FileSystem fs = FileSystem.get(conf);
-
Path path = new Path("/gyb/student.txt");
-
// 产生IO流
-
FSDataOutputStream fsio = fs.create(path);
-
// 包装输出IO流
-
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fsio));
-
// 包装输入IO流
-
BufferedReader br = new BufferedReader(
-
new InputStreamReader(new FileInputStream("student.txt")));
-
String line = null;
-
while ((line = br.readLine()) != null) {
-
bw.write(line);
-
bw.newLine();
-
bw.flush();
-
}
-
bw.close();
-
br.close();
-
}
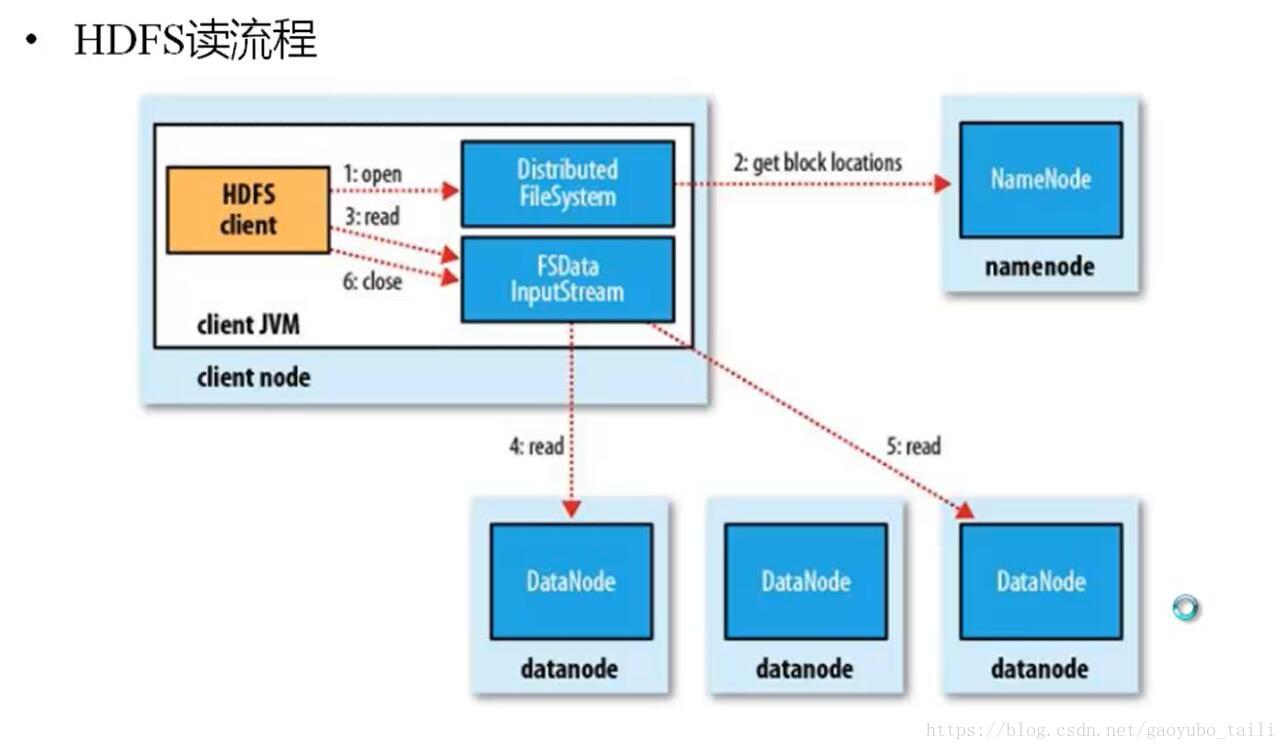
四、HDFS读原理
1、HDFS客户端提交读操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有读权限,如果有,则给客户端返回存放数据块的节点信息,即告诉客户端可以到相关的DataNode节点下去读取数据块;
2、客户端拿到块位置信息后,会去和相关的DataNode直接构建读取通道,读取数据块,当所有数据块都读取完成后关闭通道,并给NameNode返回状态信息,告诉NameNode已经读取完毕。
代码实现
-
/*
-
* 测试HDFS读出的操作
-
*/
-
-
public void Test3() throws IOException {
-
// 加载配置类
-
Configuration conf = new Configuration();
-
FileSystem fs =FileSystem.newInstance(conf);
-
Path path = new Path("/gyb/student.txt");
-
FileStatus[] fileStatus = fs.listStatus(path);
-
for (FileStatus fileStatus2 : fileStatus) {
-
if(fileStatus2 != null && fileStatus2.isFile()) {
-
//open方法只能传文件
-
FSDataInputStream fsi = fs.open(path);
-
// 包装IO流
-
BufferedReader br = new BufferedReader(new InputStreamReader(fsi));
-
while(br.ready()) {
-
System.out.println(br.readLine());
-
}
-
}
-
}
-
System.out.println( "--------over--------");
-
}