一 HDFS简介(Hadoop Distributed File System)
1简介:
是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS体系结构中有两类节点,一类是NameNode,又叫"元数据节点";另一类是DataNode,又叫"数据节点"。这两类节点分别承担Master和Worker具体任务的执行节点。总的设计思想:分而治之——将大文件、大批量文件,分布式存放在大量独立的服务器上,以便于采取分而治之的方式对海量数据进行运算分析。
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
HDFS一般是用来“一次写入,多次读取”,不适合做实时交互性很强的事情,不适合存储大量小文件(当然,如果你偏要存大量小文件的话本文末尾会有解决方案).
2 hdfs优缺点
HDFS优点:
· 高容错性:数据自动保存多个副本,副本丢失后,自动恢复
· 适合批处理:移动计算而飞数据。数据位置暴露给计算框架
· 适合大数据处理:GB,TB,设置PB级数据。百万规模以上文件数量。10K+节点规模。
· 流式文件访问:一次性写入,多次读取。保证数据一致性。
· 可构建在廉价机器上:通过多副本提高可靠性。提供容错和恢复机制。
HDFS缺点:
· 不适合低延迟数据访问场景:比如毫秒级,低延迟与高吞吐率
· 不适合小文件存取场景:占用NameNode大量内存。寻道时间超过读取时间。
· 不适合并发写入,文件随机修改场景:一个文件只能有一个写者。仅支持append
二 hdfs工作原理
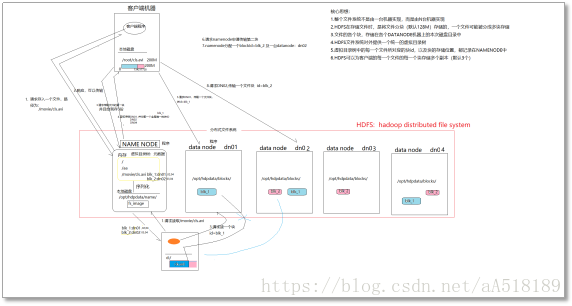
HDFS是一个分布式系统,客户端首先找到namenode,告诉namenode文件被分割的块大小,文件的副本个数等信息,然后namenode会告诉客户端需要把文件上传到那几台机器上,也就是安装datanode的机器上去。
并且给每个文件生产唯一的id号,然后客户端就会把切好的文件块传到这几台机器上去。其他机器读取文件时,也是首先找namenode,然后namenode在告诉客户去那几台机器上找所需要的文件快。每一个文件的每一个切块,在hdfs集群中都可以保存多个备份(默认3份),在hdfs-site.xml中,dfs.replication的value的数量就是备份的数量.hdfs中有一个关键进程服务进程:namenode,它维护了一个hdfs的目录树及hdfs目录结构与文件真实存储位置的映射关系(元数据).而datanode服务进程专门负责接收和管理"文件块"-block.默认大小为128M(可配置),(dfs.blocksize).(老版本的hadoop的默认block是64M的)上述只是一个大致的流程,真实过程是比较复杂的。
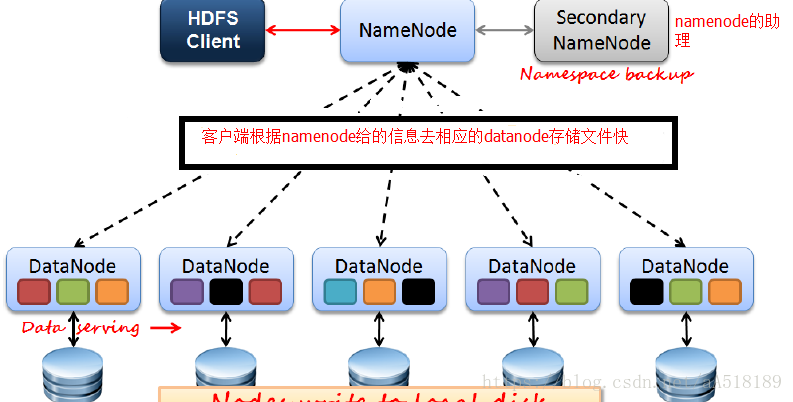
HDFS中的核心角色:
NAME NODE:负责记录文件系统的元数据(文件系统的目录树,每个文件的块信息<块id、块位置>);
DATA NODE:负责管理文件块;
NameNode:就是 master,它是一个主管、管理者。
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
NameNode:Master节点:只有一个,管理HDFS的名称空间和数据块映射信息;配置副本策略;处理客户端请求。
DataNode:Slave节点:存储实际的数据;执行数据块的读写;汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
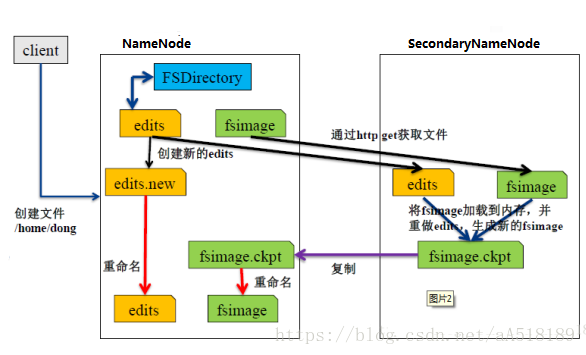
fsimage和fsedits
NameNode中两个很重要的文件
fsimage是元数据镜像文件(保存文件系统的目录树)。
edits是元数据操作日志(记录每次保存fsimage之后到下次保存之间的所有hdfs操作)。
内存中保存了最新的元数据信息(fsimage和edits)。
edits过大会导致NameNode重启速度慢,Secondary NameNode负责定期合并它们
客户端程序Client:封装存、取文件的过程(这是一个复杂的过程,要与namenode、datanode做各种各样的交互)。
hdfs工作原理图如下
hdfs结构图
HDFS可靠性机制
常见错误情况:文件损坏;网络或者机器失效;NameNode挂掉;
文件的完整性:通过CRC32校验,如果有损坏,用其他副本替代损坏文件;
Heartbeat:DataNode定期向NameNode发送eartbeat;
元数据信息:FsImage、Editlog进行多份备份,当NameNode宕机后,可手动还原。
HDFS中的文件存储形式:
每个文件会被分成若干个块(由客户端决定:参宿)来存储;
这些块都存储在DATANODE服务器的磁盘目录中;
每个块在整个HDFS文件系统中,都可以存储多个副本(由客户端:参数决定,可配置);
三 hdfs安装过程
安装步骤
前提:
准备4台linux机器
装好jdk
配好IP地址、主机名、域名映射、关闭防火墙
补充一个命令:禁止一个服务(防火墙)开机自启: chkconfig iptables off
配好cts01 -->其他所有机器的免密登陆机制
a) 上传安装包到wangzhihua1
b) 解压
c) 删除share 里面的doc文件 hadoop放入文档文件 不需要 不删除也行
e) 修改配置文件
找到hadoop-env.sh 一下图的次序寻找 apps->hadoop-2.8.1->etc->hadoop->hadoop-env.sh
第一:配置java环境变量告诉hadoop java指令在哪里
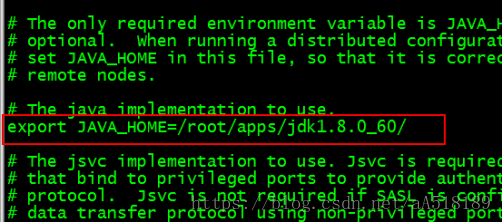
vi /root/apps/hadoop-2.8.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/root/apps/jdk1.8.0_60
第二:配置 /etc/hadoop/ hdfs-site.xml
注意配置文件时 不要直接从Word里面直接粘贴,尽量粘贴到notepad++中在复制,再粘贴
hdfs-site.xml
<configuration> <property> <name>dfs.namenode.rpc-address</name> <value>cts01:9000</value> </property>
<property> <name>dfs.namenode.secondary.http-address</name> <value>cts02:50090</value> </property>
<property> <name>dfs.namenode.name.dir</name> <value>/root/hdpdata/name/</value> </property>
<property> <name>dfs.datanode.data.dir</name> <value>/root/hdpdata/data/</value> </property>
</configuration> |
f) 复制安装包到别的机器
scp -r hadoop-2.8.1/ cts02:/root/apps/
scp -r hadoop-2.8.1/ cts03:/root/apps/
scp -r hadoop-2.8.1/ cts04:/root/apps/
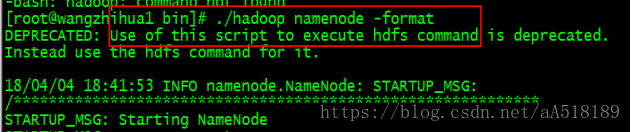
把namenode的元数据目录初始化(在cts01)bin/hadoop namenode -format
注意:在启动hadoop之前一定要先初始化元数据,手动创建也不行
如果namenode的储存元数据的目录改变了 ,datanode的文件快目录也需要改变
解决方案:把之前的datanode文件快目录删了 重新bin/hadoop datanode -format
g) 手动启动
这次可不是启动一个程序,而是启动一堆程序;
要在wangzhihua1上启动namenode软件
sbin/hadoop-daemon.sh start namenode
要在wangzhiua/2/3/4上启动datanode软件
sbin/hadoop-daemon.sh start datanode
启动完后,可以用浏览器请求namenode的50070端口
可以看到集群的信息、以及文件系统的目录
单个进程逐一启动很麻烦,可以写一个批启动脚本:
[root@cts01 ~]# vi hdfsmg.sh #!/bin/bash op=$1 echo "${op}ing namenode on cts01" ssh cts01 "/root/app/hadoop-2.8.1/sbin/hadoop-daemon.sh $op namenode"
for i in {1..4} do echo "${op}ing datanode on cts0$i" ssh cts0$i "/root/app/hadoop-2.8.1/sbin/hadoop-daemon.sh $op datanode" done |
其实,这样的脚本,hadoop安装包里面已经有了:
启动hdfs: sbin/start-dfs.sh
停止hdfs: sbin/stop-dfs.sh
住:启动hdfs失败后 要学会查看hadoop的日志文件 ,记住任何软件出错,错误信息都会打到日志文件中。
还有就是尽量把hadoop的bin目录 和sbin目录添加到环境变量中去,便于操作。
配置hdfs启动文件
内置的脚本,需要我们自己将datanode机器列入一个etc/hadoop/slaves文件
[root@cts01 hadoop]# vi slaves wangzhihua1 wangzhihua2 wangzhihua3 wangzhihua4 |
HDFS的使用
命令行客户端:
bin/hadoop fs 可以启动一个命令行客户端程序!!!
只不过,hadoop的这个hdfs命令行客户端程序,可以查看多种类型的文件系统:
v 可以访问本地文件系统
《默认访问的就是本地文件系统》
v 可以访问hdfs文件系统
方式1:在路径上拼上完整的hdfs访问URI
bin/hadoop fs -ls hdfs://cts01:9000/ ## 查看hdfs中的一个文件夹中的信息
bin/hadoop fs -mkdir hdfs://cts01:9000/abc/
bin/hadoop fs -put ./xx.dat hdfs://cts01:9000/
每次都需要把HDFS的URI写上,很麻烦,可以在客户端配置一个参数,即可让客户端默认访问我们指定的HDFS文件系统;
核心参数2方式2:在客户端的安装包中配置如下参数:
vi /root/apps/hadoop-2.8.1/etc/hadoopcore-site.xml
fs.defaultFS=hdfs://cts01:9000/
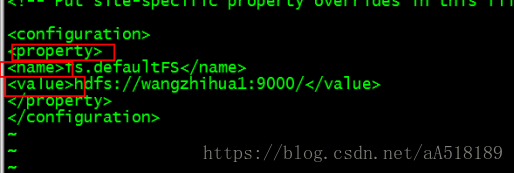
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://wangzhihua1:9000</value>
</property>
</configuration>
注意:这三个标签标示一个变量的信息 缺一不可。
核心参数2:客户端所要访问的默认文件系统
fs.defaultFS = hdfs://cts01:9000/
客户端一旦配置了这个参数,那么在访问HDFS路径时,就不需要写全URI了
核心参数3:上传文件时的切块大小配置
dfs.blocksize=128
核心参数4:上传文件时的副本数量配置
dfs.replication=3
命令行客户端常用命令:
bin/hadoop fs -ls / ## 查看hdfs中的一个文件夹中的信息
bin/hadoop fs -mkdir /abc/ ## 在hdfs文件系统中创建文件夹
bin/hadoop fs -put ./xx.dat / ## 从客户端的本地文件系统中传输一个文件到hdfs文件系统
bin/hadoop fs -get /hdfs/path ./ ##从hdfs文件系统中下载一个文件到客户端本地磁盘
bin/hadoop fs -rm /hdfs/file ## 删除
bin/hadoop fs -rm -r /adc/ ## 删除目录
bin/hadoop fs -cp /hdfs/file1 /hdfspath/file2 ## 在hdfs中复制
bin/hadoop fs -mv /hdfspath1/file1 /hdfspath2/file2 ## 在hdfs中移动
bin/hadoop fs -cat /bbb/xxoo.sh ## 显示文件的内容
bin/hadoop fs -tail /bbb/xxoo.sh ## 显示文件的尾部内容
bin/hadoop fs -appendToFile ./a.txt /bbb/xxoo.sh ##追加一个本地文件的内容到HDFS中的一个文件
补充概念:URI
统一资源定位描述
用统一的格式来描述一种资源
<< 访问协议://主机名:端口号/具体资源>>
一个网页: http://baidu.com:80/index.html
一个数据库:jdbc:mysql://cts01:3306/db1
hdfs文件系统: hdfs://cts01:9000/
本地文件系统: file:///
JAVA API客户端:
要在程序中访问HDFS,需要在我们的程序工程中引入hdfs的jar包,才能使用hdfs的客户端api
需要的引入的包有两个分类 都在hadoop的share文件夹中:一个是common的jar包以及依赖的jar包(lib目录中),和hdfs的jar包和依赖的jar包(lib目录中)
运维补充:
datanode的数据目录中有一个VERSION文件,记录着datanode自己的uuid,和集群的id
集群id是由namenode在格式化时生成的,每格式化一次,就会生成一个新的集群id
如果多个datanode的uuid重复,或者datanode上记录的集群id与namenode上记录的集群id不一致,都会出故障!