大数据生态系统:
-
存储:hadoop hdfs
-
计算引擎:
-
map/reduce v1
-
map/reduce/v2(map/reduce on yarn)
-
Tez
-
spark
- Impala Pesto Drill 直接跑在hdfs上
-
pig(脚本方式)hive(SQL语言)跑在map/reduce上
-
hive on lez/sparkSQL
-
流式计算-storm
-
Kv store|
cassandra mongodb hbase -
Tensorflow Mahout
-
Zookeeper Protobuf
-
sqoop kafka flume…
虚拟机常用的软件:
- VMWare
- VirtualBox
需要5个软件(百度即可下载):
- VirtualBox(虚拟机软件)
- centos(linux系统)
- hadoop(linux版)
- jdk(linux版)
- xshell(远程登录软件附带xftp上传文件的)
- 将软件下载好后,首先将VirtualBox安装好,
- 点击新建:

-
设置内存大小,默认就可以
-
创建虚拟硬盘,默认的即可,
#选择动态分配
#文件位置和大小:默认即可,后期8G不够用,在扩就行 -
安装光驱:

- 启动:
- 启动过程中会自动检查磁盘,按Esc跳过即可 。jk
- 从windos往liunx点鼠标的时候会弹一框, 框的意思是捕获鼠标,意思就是,这个时候你鼠标的操作是在liunx中进行的,这个时候鼠标是出不来的,要出来按Ctrl键就能出来了。
- 安装界面:
- 选中文(自行决 定)
- 在安装位置图标上有一个感叹号,点进去在点完成即可。
- 有一个软件选择按钮,点进1去,在做服务器模拟的时候,最小安装时不够的,所以我们选择:基础设施服务器,点完成。
- 点开始安装:
- 安装的同时设置一下root密码(如果密码简单需要点击两次完成)
- 等待,安装完成之后需要重启机器,点击重启后就可以用了
- 重启后:
-
登录
-
为了与Windows连接起来查看liunxIP

- 我们配置一个IPv4的地址,让他和Windows通讯:
-
安装完VirtualBox之后我们的电脑上会出现:

-
点击右键属性,下拉框中找到{Internet 协议版本}点进去,看到其IP地址为192.168.56.xxx(IP可随意更改),我们根据192.168.56网段来配置
-
设置IP命令:
vim /ect/sysconfig/network-scripts/ifcfg-eth0 -
没用的删掉,写入,保存 :
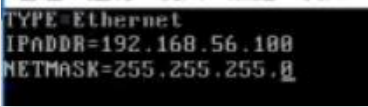
-
设置网关命令:
vim /etc/sysconfig/network -
写网关IP可上网(不加#号去掉,#号是注释):
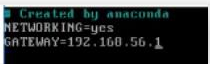
- 测试:
-
liunx:ping一下Windows机器:ping+IP地址
-
Windows:Windows ping一下liunx:ping+IP地址
- 将JDK和VirtualBox用Xshell上传到虚拟机。
- 安装命令:rpm -ivh jdk-8u91-liunx-x64.rpm
- 验证java是否装好了
-
出现了各个包的信息就是装好了

安装hadoop
- 解压:
命令:tar -xvf hadoop-2.7.3.tar.gz
- 配置hadoop
-
配置文件位置:etc->hadoop->hadoop-env.sh
命令:vim hadoop-env.sh
为了告诉hadoop,JDK在那 -
写入JDK的路径

- 将hadoop执行命令的路径加入到环境变量中
- 命令:vim /etc/profileh
在最后一行插入
export PATH = $PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
- 执行一下:source /etc/profile要不然不起作用。
-
找到虚拟机图标右键复制即可复制虚拟机(全部复制)
需要将复制出来的三台机器的IP地址更改。
-
启动hadoop。
- 在hadoop目录下有一个core-site.xml配置文件,对其进行配置是为了知道master位于那一台机器上被谁管理的

-
在最后加入,加入后就可以启动hadoop了
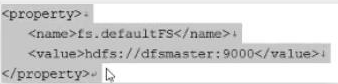
- 我们修改一下host文件,(知道每台对应的IP)
-
命令:vim /etc/host
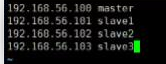
- 启动master和slave
-
master(进程中看到nameNode就是启动了):

-
slace(进程中看到dateNode就是启动了):

-
逻辑关系:

HDFS初识
- 用来存文件的,有一台坏了的话,不会妨碍其他的对外提供服务
物理和逻辑架构

HDFS架构

启动集群
- 在master上启动hadoop-daemon.sh start namenode
- 在slave上启动hadoop-daemon.sh start datanode
- 用jps指令观察执行结果
- 用hdfs dfsadmin -report观察集群配置情况
- hadoop fs -rm/rilename
- 通过heep://192.168.56.100:50070界面观察集群运行情况
- 用hadoop-daemon.sh stop…手动关闭集群
对集群进行集中管理
- 在/usr/local/hadoop/etc/hadoop 的目录下有一个 slave文件,他里面记录着当前这台namenode管理者多少台datanode,每台datanode式位于那台机器上,我们可以更改里面的内容,有多少台datanode就添加多少台
1.修改master上/etc/hadoop/slave文件,每一个slave占一行
2. 使用start-dfs.sh启动集群,并观察结果,使用stop-dfs.sh停止集群
3. 配置免密SSH远程登录
1.cd
2.is -la
3.cd .ssh
4.ssh-keygen -t rsa(四个回车)
5.会用rsa算法生成私钥id_rsa和公钥id_rsa.pub
6.ssh-copy-id slavex
7.再次ssh slave1
8.此时应该不在需要密码
4.重新使用start-dfs.sh启动集群
5.使用hdfs dfs 或者hadoop fs 命令对文件进行增删改查
-
hadoop fs -ls/
-
hadoop fs -put file/
-
hadoop fs -mkdir /dimame
-
hadoop fs -text /filename
-
hadoop fs -rm /filename
6.hadoop文件默认的存储位置
-
但是tmp目录会不定时被系统进行清除,如果不自己指定存储位置的话,就会时而好用,时而不好用,所以真正程序需要建议更改,不然会丢失数据
cd /tmp(临时文件)
7.我们来写程序,做远程访问
-
使用HTTP协议:
public static void main(String[] args) throws Exception{ URL url = new URL("http://www.baidu.com"); InputStream in = url.openStrean(); //4096指的是他的缓冲区是多大, //true指的是读完输入流然后对他进行自动化的关闭 IOUtils.copyBytes(in,System.out,4096,true); } -
使用HDFS协议:
public static void main(String[] args) throws Exception{ //FsUrlStreamHandlerFactory(),指明了如果遇到hdfs就讲URL地址交给他处理 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); URL url = new URL("hdfs://192.168.56.100:9000/hello.txt"); InputStream in = url.openStrean(); //4096指的是他的缓冲区是多大, //true指的是读完输入流然后对他进行自动化的关闭 IOUtils.copyBytes(in,System.out,4096,true); } -
实现增删改查
public static void main(String[] args) throws Exception{ configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://192.168.56.100:9000"); fileSystem fileSystem = FileSystem.get(conf); //mkdirs创建目录(在根目录下创建一个叫msb的目录) boolean success = fileSystem.mkdirs(new Path("/msb")); System.out.println(success); //判断文件是否存在 success = fileSystem.exists(new Path("/hello.txt")); System.out.println(success); //删除目录 success = fileSystem.delete(new Path("/msb"),true); System.out.println(success); //判断文件目录是否存在 success = fileSystem.exists(new Path("/msb")); System.out.println(success); //上传数据 FSDataOutPutStream out =fileSystem.create(new Paht("/test.data"),true); FileInputStream fis = new FileInputStream("c:/test/core-site.xml"); IOUtils.copyBytes(fis,out,4096,true); }【通知】618狂欢夜(倒计时开始啦)
主讲老师:马士兵老师、前阿里大牛、前京东大牛等多位技术大牛
直播主题:
1、深度揭秘京东面试流程,薪酬体系,技术架构!
2、更有阿里(p7薪水)老师分享线程池技术!
3、分享技术架构,分享面试经验,分享人生感悟!
618技术狂欢夜,等你参加。
直播时间:2019-6-18 19:30 腾讯课堂直播间等你!
小二先提前通知您咯,提前安排好自己的工作安排哦!
私信我,回复“222”领取上课链接!

最后小编给大家准备了一些学习资料:

有需要的同学可以在评论区留言~~