紧接着上期话题,我在这里为大家详细解释一下BeautifulSoup的用法
soup=BeautifulSoup(res.text,'html.parser')当我们获取了soup内容后该如何随心所欲的抓取自己想要的内容呢?
我在这里给大家介绍几个方法:
1.soup.select(‘.class’):
这个方法可以返回特定div class下的内容
import requests
from bs4 import BeautifulSoup
def getInfo(url):
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
results=soup.select('.intim')
for result in results:
print(result.text)
if __name__ == '__main__':
url='http://jwc.tyut.edu.cn/'
getInfo(url)这样写我可以返回 div class叫intim下的所有内容,部分结果如下:
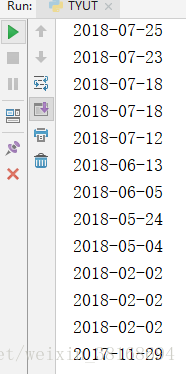
2.soup.select(‘#id’):
这个方法可以返回特定div id下的内容
results=soup.select('#select')部分结果如下:

3.那么我想进一步获取特定div 特定标签下的内容呢?
BeautifulSoup支持嵌套结构
比如我想获得intmc class下的a标签的title内容:
results=soup.select('.intmc a')
for result in results:
print(result['title'])结果部分如下:
