- 分页插件
列表查询功能大多都需要实现分页查询,还记得以前被手写分页查询所支配的恐惧吗,对于每一个实体,都需要添加pageNum、pageSize属性,每一个列表查询都要单独写一段分页查询SQL,耗时耗力耗神,所以分页查询插件必不可少,直接用Mybatis最常用的开源PageHelper插件,pom.xml添加依赖
<properties>
<pagehelper.spring.boot.version>1.2.5</pagehelper.spring.boot.version>
</properties>
<dependencies>
<!--分页-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>${pagehelper.spring.boot.version}</version>
</dependency>
</dependencies>使用分页插件时,如果没有特殊的需要,其实完全不需要加入其他配置项的,因为SpringBoot理念是习惯大于配置,所以默认的配置足以满足基本的需求
使用方法不再赘述,如果有不懂的小伙伴可以查看官方介绍的第3部分——如何在代码中使用,https://pagehelper.github.io/docs/howtouse/,一般最常用的就是startPage(pageNum,pageSize)这种方式
- 数据库连接池
企业级应用会有大量的数据库读写任务,而每一次读写都会建立和关闭数据库连接,频繁的建立、关闭连接,会极大的减低系统的性能,主流的几种数据库连接池的横向对比就不介绍了,感兴趣可以百度一下,我们用Druid即可
在pom文件中添加依赖
<properties>
<druid.spring.boot.version>1.1.10</druid.spring.boot.version>
</properties>
<dependencies>
<!--数据库连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.spring.boot.version}</version>
</dependency>
<dependencies>修改application.yml中的数据源配置为
spring:
datasource:
############ JDBC 配置 ###################
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password:
############# Druid 连接池配置 #################
# 初始连接数 #
initial-size: 5
# 最大的活跃连接数 #
max-active: 20
# 指定必须保持连接的最小值 #
min-idle: 3
# 测试SQL #
validation-query: SELECT 'x' FROM DUAL
# 超时等待时间 #
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 #
time-between-eviction-runs-millis: 60000
# 指定一个空闲连接最少空闲多久后可被清除,单位是毫秒 #
min-evictable-idle-time-millis: 300000
# 当连接空闲时,是否执行连接测试 #
test-while-idle: true
# 当从连接池借用连接时,是否测试该连接 #
test-on-borrow: false
# 在连接归还到连接池时是否测试该连接 #
test-on-return: false
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,wall用于防火墙 #
# 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall #
filters: stat,wall,log4j
# 以下是监控的配置 ##########
web-stat-filter:
enabled: true
url-pattern: /*
# 排除统计干扰 #
exclusions: /druid/*,*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico
session-stat-enable: true
session-stat-max-count: 10
stat-view-servlet:
# 白名单 #
allow: 127.0.0.1
# 黑名单,与白名单同时存在时优先黑名单 #
deny:
enabled: true
url-pattern: /druid/*
# 是否能够重置数据 #
reset-enable: true
login-username: druid
login-password: druid启动应用,访问localhost:9090/druid/index.html会被拦截到下图页面,登录后即可查看当前数据源监控信息,登录名和密码即为配置文件中的login-username和login-password
- 多数据源
很多时候单个应用需要连接多个数据库来完成功能,所以多数据源的配置也是企业级开发必备。我们使用分包的方式来配置多数据源
1、数据库准备
我们已经有一个名为demo的数据库,还需要新建一个数据库demo_2,然后初始化一个demo_info表进去,并给这个表初始化一条数据
CREATE TABLE `demo_info` (
`id` varchar(32) NOT NULL COMMENT 'id',
`name` varchar(32) DEFAULT NULL COMMENT '名字',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `demo_2`.`demo_info` (`id`, `name`) VALUES ('2', '小白');2、生成实体
根据我的上一篇使用SpringBoot搭建企业级应用开发框架(二)数据库及Mybatis集成中的描述,我们可以新建一个mybatis-generator-confing.xml来管理新的数据源的代码自动生成,过程不再赘述,由于我们使用分包的方式,所以两个数据库的Mapper要放在不同的目录下,例如我这样设计此demo的文件目录结构(只画出main目录下与多数据源有关的)
main
| java
com/example/demo
| entity
| mapping
| masterDb
| secondDb
mapper
| masterDb
| secondDb
| resources
| generator
| mybatis-generator-config-master.xml
| mybatis-generator-config-second.xml
| application.yml
3、配置多数据源
修改application.yml中数据源部分内容为
spring:
datasource:
############ JDBC 配置 ###################
master:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password:
second:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/demo_2?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password:
############# Druid 连接池配置 #################
druid:
# 初始连接数 #
initial-size: 5
# 最大的活跃连接数 #
max-active: 20
# 指定必须保持连接的最小值 #
min-idle: 3
# 测试SQL #
validation-query: SELECT 'x' FROM DUAL
# 超时等待时间 #
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 #
time-between-eviction-runs-millis: 60000
# 指定一个空闲连接最少空闲多久后可被清除,单位是毫秒 #
min-evictable-idle-time-millis: 300000
# 当连接空闲时,是否执行连接测试 #
test-while-idle: true
# 当从连接池借用连接时,是否测试该连接 #
test-on-borrow: false
# 在连接归还到连接池时是否测试该连接 #
test-on-return: false
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,wall用于防火墙 #
# 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall #
filters: stat,wall,log4j
# 以下是监控的配置 ##########
web-stat-filter:
enabled: true
url-pattern: /*
# 排除统计干扰 #
exclusions: /druid/*,*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico
session-stat-enable: true
session-stat-max-count: 10
stat-view-servlet:
# 白名单 #
allow: 127.0.0.1
# 黑名单,与白名单同时存在时优先黑名单 #
deny:
enabled: true
url-pattern: /druid/*
# 是否能够重置数据 #
reset-enable: true
login-username: druid
login-password: druid在com.example.demo下新建config包,创建多数据源配置类,每个数据源都要创建一个,其中最多有一个作为主数据源,主数据源和其他数据源的配置区别在于@Primary注解,这里只展示主数据源配置,其他数据源配置自行创建修改即可
@Configuration
@MapperScan(basePackages = "com.example.demo.mapper.masterDb", sqlSessionTemplateRef = "db1SqlSessionTemplate")
public class DataSource1Config {
@Bean(name = "db1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.master")
@Primary
public DataSource testDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "db1SqlSessionFactory")
@Primary
public SqlSessionFactory testSqlSessionFactory(@Qualifier("db1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("com.example.demo.mapper.masterDb.mapper.*.xml"));
return bean.getObject();
}
@Bean(name = "db1TransactionManager")
@Primary
public DataSourceTransactionManager testTransactionManager(@Qualifier("db1DataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "db1SqlSessionTemplate")
@Primary
public SqlSessionTemplate testSqlSessionTemplate(@Qualifier("db1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}此时Mapper路径的扫描已配置到各个具体的数据源中,所以SpringBoot启动类中的@MapperScan注解已经可以删掉了
配置好后,编写测试类,在刚才我们使用的测试用controller中添加以下测试方法
@RequestMapping("/doubleDb")
public String doubleDb(){
UserInfo user = userInfoMapper.selectByPrimaryKey("1");
DemoInfo demo = demoInfoMapper.selectByPrimaryKey("2");
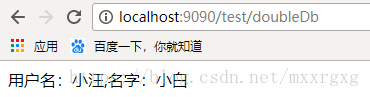
return new StringBuffer().append("用户名:").append(user.getUsername()).append(",名字:").append(demo.getName()).toString();
}启动应用,访问localhost:8080/test/doubleDb,看到以下结果:
SpringBoot2默认使用Hikari作为数据库连接池,如果你没有使用Druid作为数据库连接池,就代表使用了Hikari,配置多数据源的话,要将application.yml中的spring.datasource.*.url改为spring.datasource.*.jdbc-url,否则访问时会发生异常