1.明确要爬取的对象是什么
(1)找到json文件

百度图片采用的是ajax+json机制,单独一次访问返回的html只是一个空壳,需要的图片信息并不在其中,真真的图片信息被打包放在json文件当中,所以我们真正要解读的是json文件,而不是html
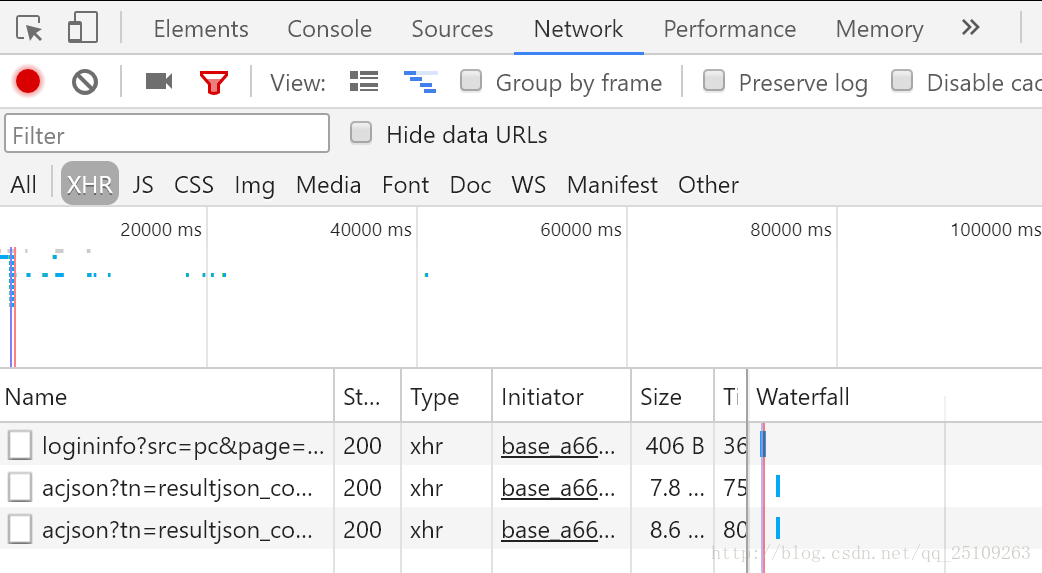
当你打开百度图片,并输入哈士奇关键字,然后用chrome的开发者工具,在Network下选中XHR类型,然后尝试用鼠标下滑网页,以刷出更多的图片,那么就可以看到服务器发过来的json文件,一下有两个以acjson?开头的json文件就是我们要解读的
(2)如何解读json文件
我们直接用的python的json库,很方便地就可以解析json了,我们用浏览器是为了得到,请求服务器返回json文件的url,我们request这个url,服务器就会返回一个json
那么这个json的url在哪里呢?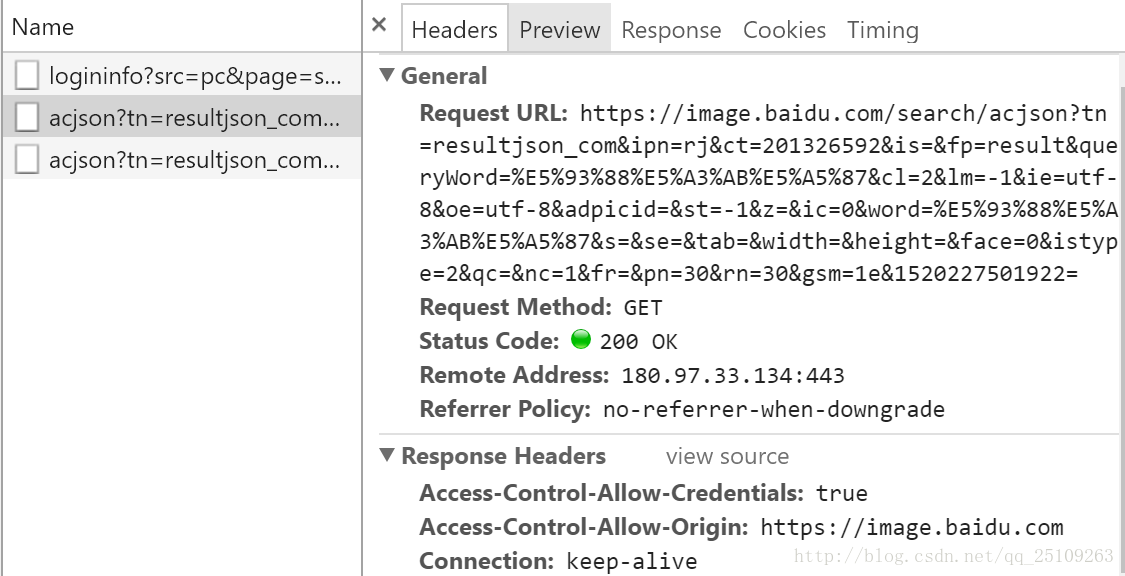
2.创建scrapy工程,创建爬虫
scrapystartproject baidupic
cdbaidupic
scrapygenspider baidu_pic_get image.baidu.com
这样工程就创建完了
3.配置爬虫
(1)编辑Items
只定义了一个URL

(2)编辑spider文件
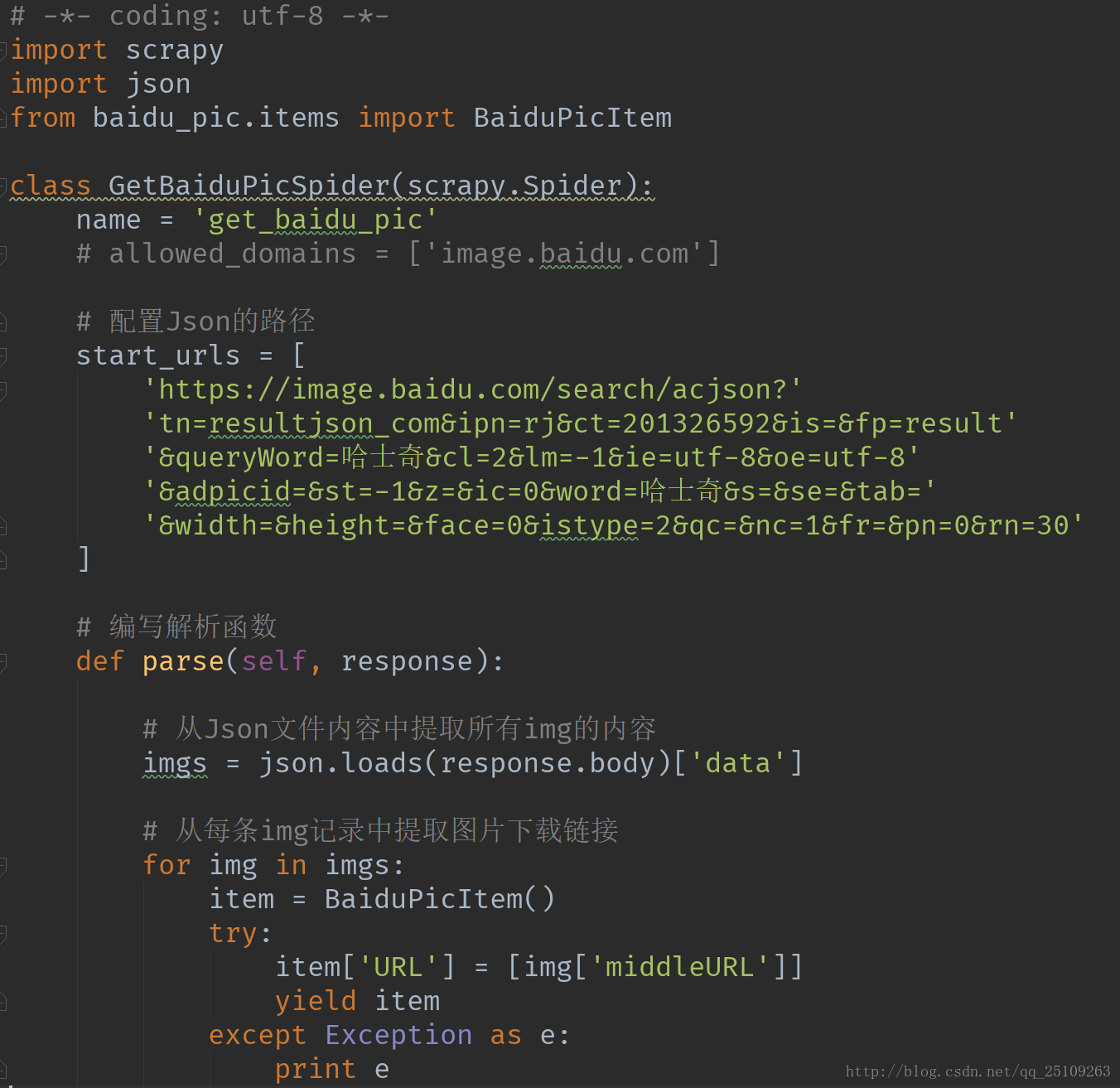
中间那么一大片就是json的url地址,爬虫第一个request不是去访问百度图片,而是直接去发送这个json的request,然后直接对返回的json文件进行解读即可
注意,这个url中queryWord,word内容配置成要查询的关键字,pn为查询第几页的意思(3)编写pipline.py(其实不用改)

其实这就是项目生成时的pipline,不用做修改,因为这个pipline是filepipline,但是我们要处理并下载图片用的scrapy的imagepipline,所以在setting中直接启用scrapy框架中默认的Imagepipline,而并没有启用用户定义的这个filepipline
(4)配置setting.py
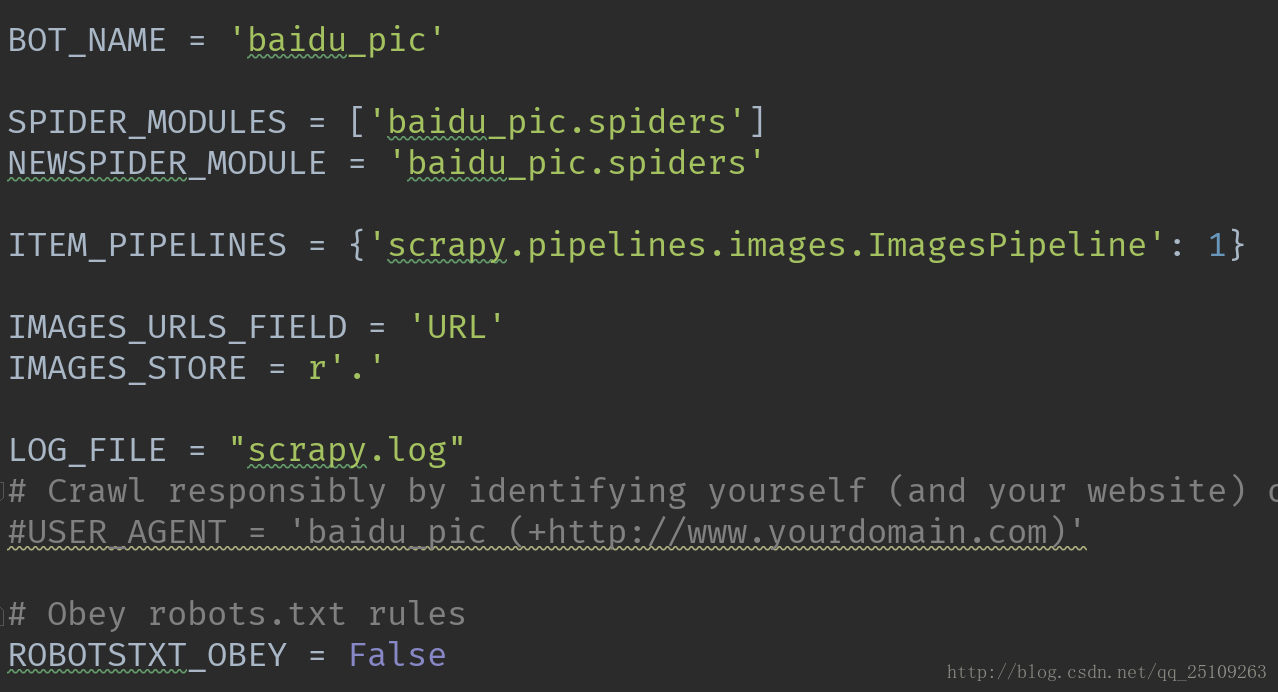
前面三行都是自动生成的,我们要做的是
添加第四行,启用ImagesPipline
添加第五行,指定下载Image的网址在Item的URL中
添加第六行,指定图片文件放在哪里,这里指定放在当前目录下
添加第七行,指定输出的log信息放在哪里
最后把ROBOTSTXT_OBEY配置成False
4.运行爬虫
scrapycrawl baidu_pic_get -o result.csv


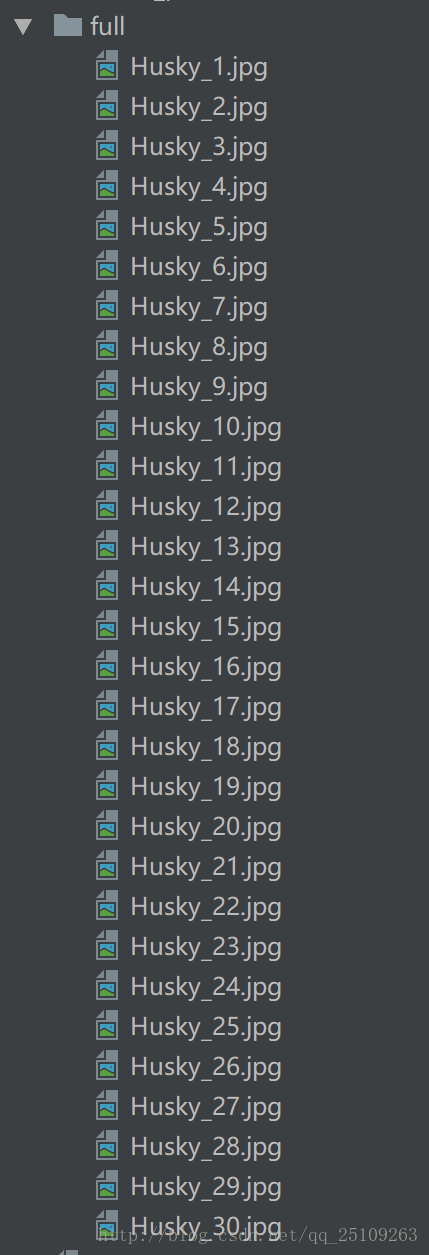
但是full里边的图片文件名都很长,不方便处理,所以我们还需要一步图片重命名的操作
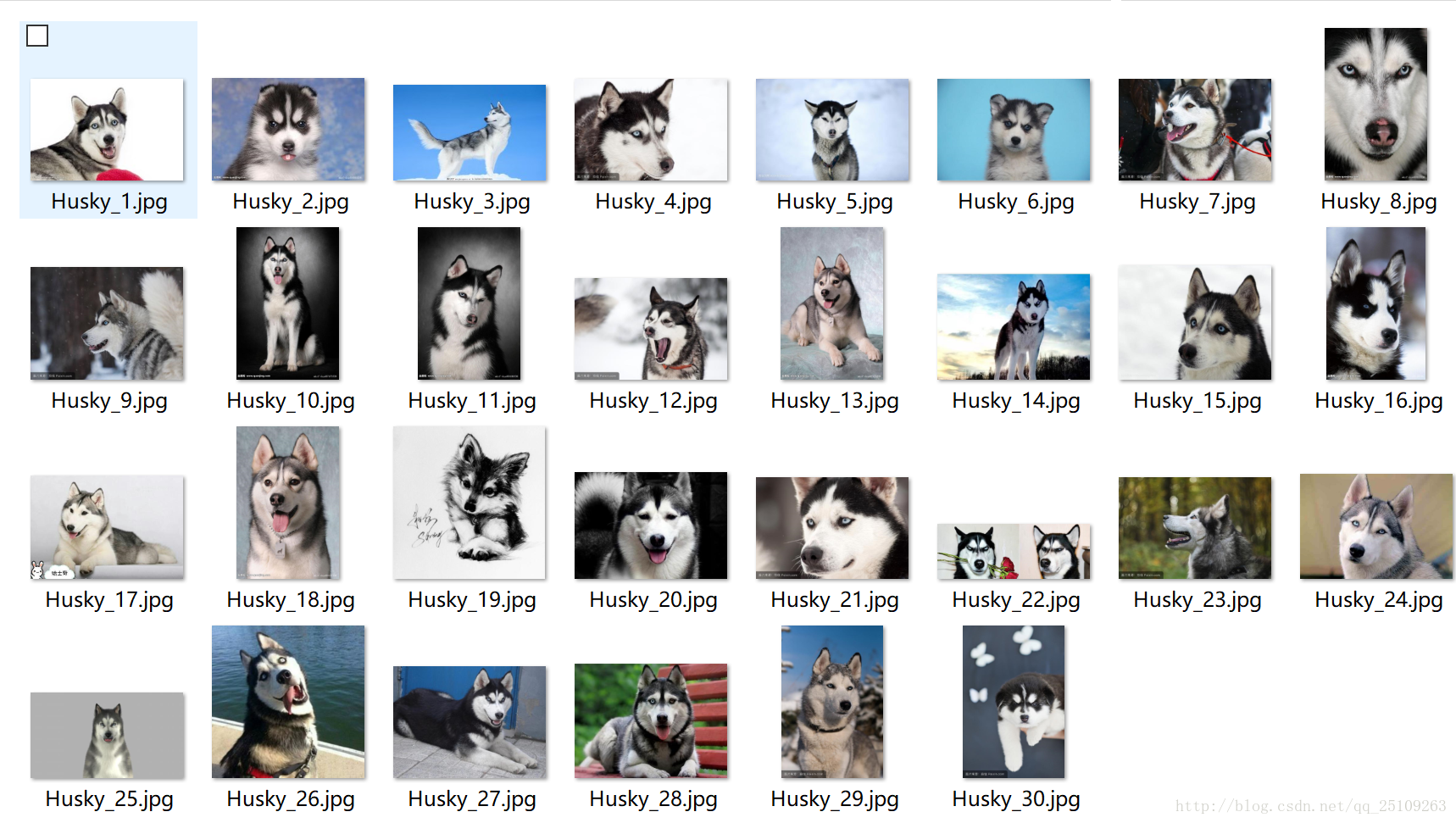
5.图片重命名
我写了一个rename_files.py

内容很简单,用了os.listdir,以及os.rename