笔者近段时间学完 Python,写了几个爬虫练练手,就找百度图片入手了
目标
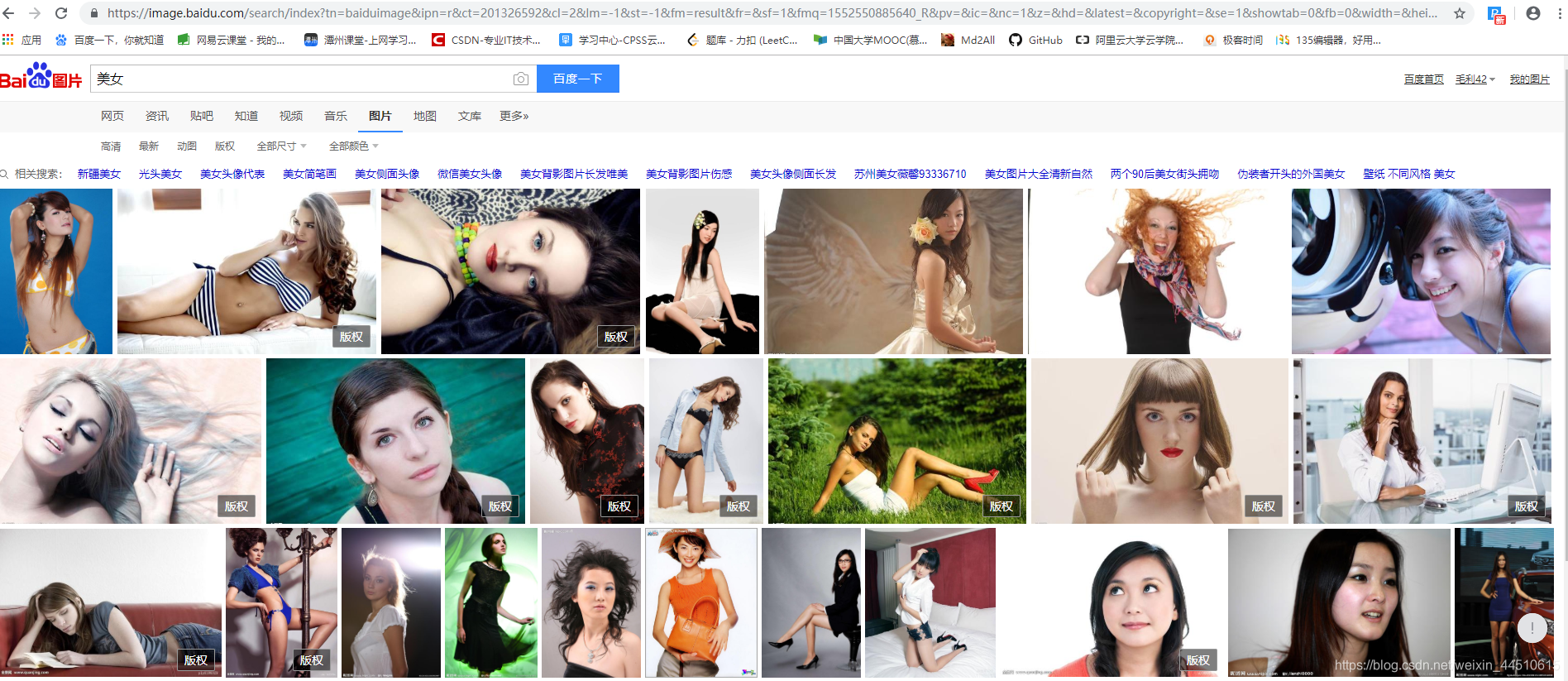
爬取 百度图库的美女的图片
环境介绍
- pycharm
- ubuntu
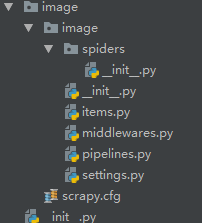
创建项目
scrapy startproject image
scrapy genspider meinv 'www.baidu.com'
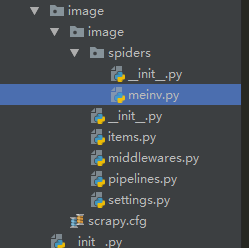
注意点
- 要将settings中的robot改为false

分析逻辑
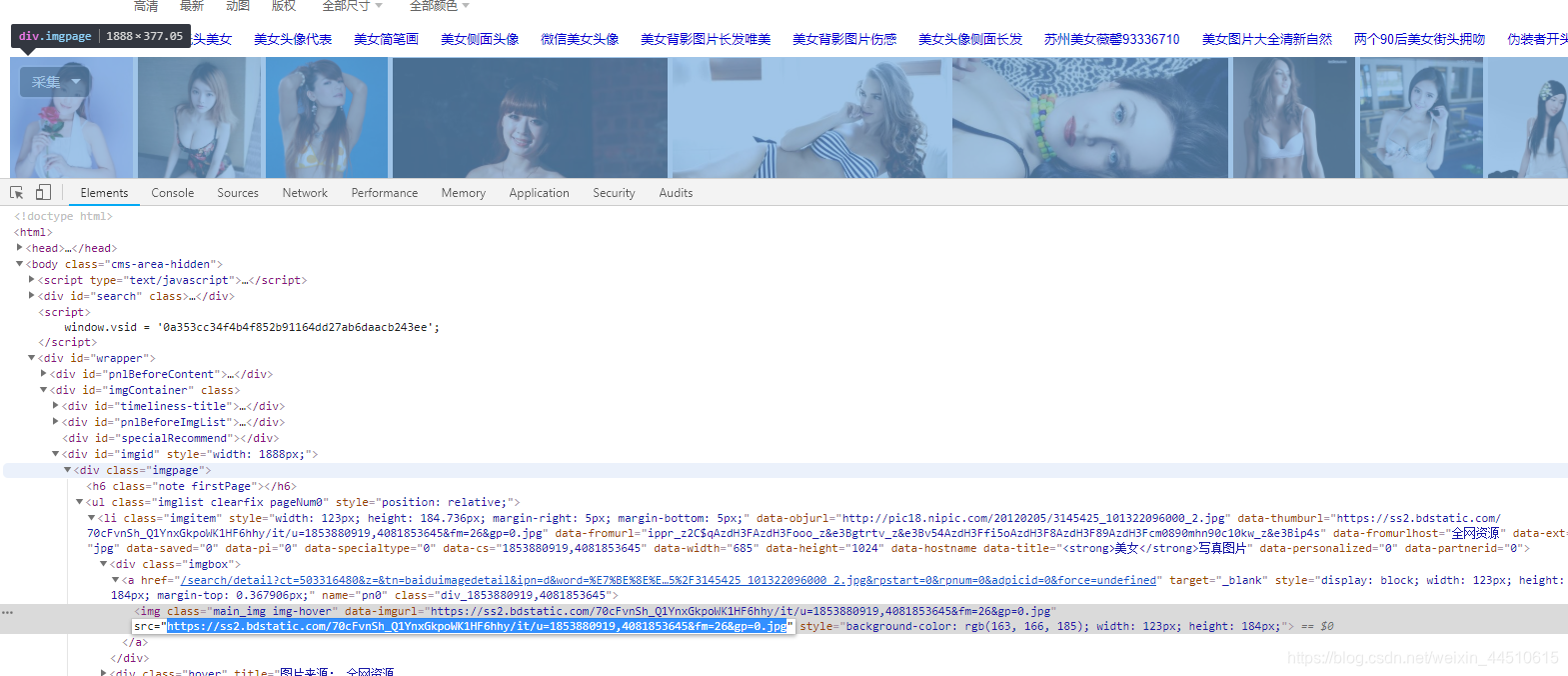

在源代码中可以看到图片的url是放在js中的,只能用re进行匹配,同时将meimv.p
y中的allowed_urls 注释
代码
import scrapy
import re
from ..items import ImageItem
class BaiduSpider(scrapy.Spider):
name = 'meinv'
# allowed_domains = ['baidu.com']
start_urls = ['https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1552550885640_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%BE%8E%E5%A5%B3']
def parse(self, response):
html = response.text
img_urls = re.findall(r'"thumbURL":"(.*?)"',html)
for index,img_url in enumerate(img_urls):
yield scrapy.Request(img_url,callback=self.parse_img_url,meta={'num': index})
def parse_img_url(self,response):
item = ImageItem()
item['index'] = response.meta['num']
item['content'] = response.body
yield item
import scrapy
class ImageItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
index = scrapy.Field()
class ImagePipeline(object):
def process_item(self, item, spider):
with open('%s.jpg' % item['index'],'wb') as f:
f.write(item['content'])
return item
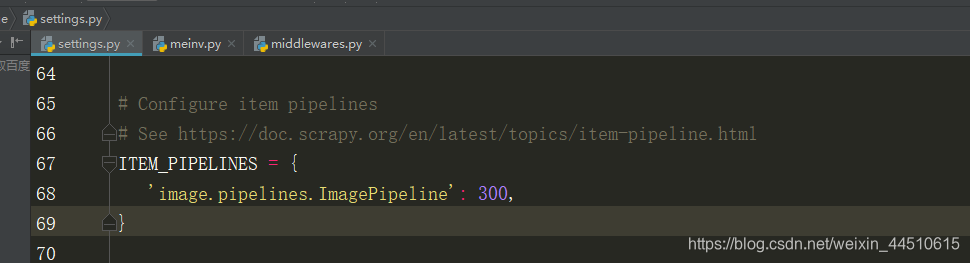
还有打开settings中的pipeline
成功
