Kafka是一个分布式的流平台。
一个流平台有三个重要的功能:
- 和消息队列、企业消息系统相似,可以发布和订阅数据流。
- 用可以容错、持久的方式去存储数据流。
- 实时的处理流。
kafka一般应用于两种类型:
- 构建在系统或者应用之间可靠的获取数据的实时流的数据通道。
- 构建可以转换或者接收流数据的实时流应用程序。
为了弄清楚kafka是如何做到上述这些的,让我们开始从下往上的研究kafka的功能。
概念:
- kafka是运行在一个或者多个服务器上、跨越多个数据中心的集群。
- kafka集群用一个叫“topic”的存储数据流。
- 每一条记录或者一个消息都由key、value和timestamp构成。
四个核心的API:
- The Producer API允许一个应用发布一个数据流到到一个或者多个topic上面。
- The Consumer API允许一个应用订阅一个或者多个topic并且处理发送给他们的数据流。
- The Streams API 允许一个应用扮演一个从一个或者多个topic里面消费输入流并且输出到一个或者多个topic里面的输出流的加工者,高效的把输入流转换成输出流。
- The Connector API 可以构建和运行可重复使用、把Kafka topics和已有的应用或者数据系统链接的生产者或消费者。例如,一个关系型数据库的connector可以捕获表的每一个变化。
在kafka里面,client和servers的交流用的是TCP协议,这种协议保持向后兼容老的版本,提供了Java版本的client,也可以用其他语言版本的client。
让我们首先研究kafka提供的数据流的核心抽象---topic
topic是消息将要发布到的地方,topic总是会有很多个订阅者,也就意味着一个topic可以对应0、1或者更多的订阅数据的消费者。
对于每一个topic而言,kafka维持着一个分区的日志,如下图:
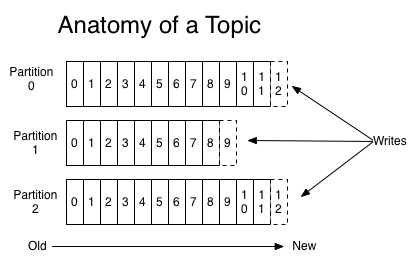
每一个分区都是有序的,不可变的被连续追加的消息序列,也就是一个有结构的提交日志。在分区里面的每一条消息,都被分配了一个连续的、叫做offset的id,可以在当前分区唯一的标识当前消息。kafka的性能实际上是不变的,从数据量的大小来说,所以长时间的存储数据是没问题的。
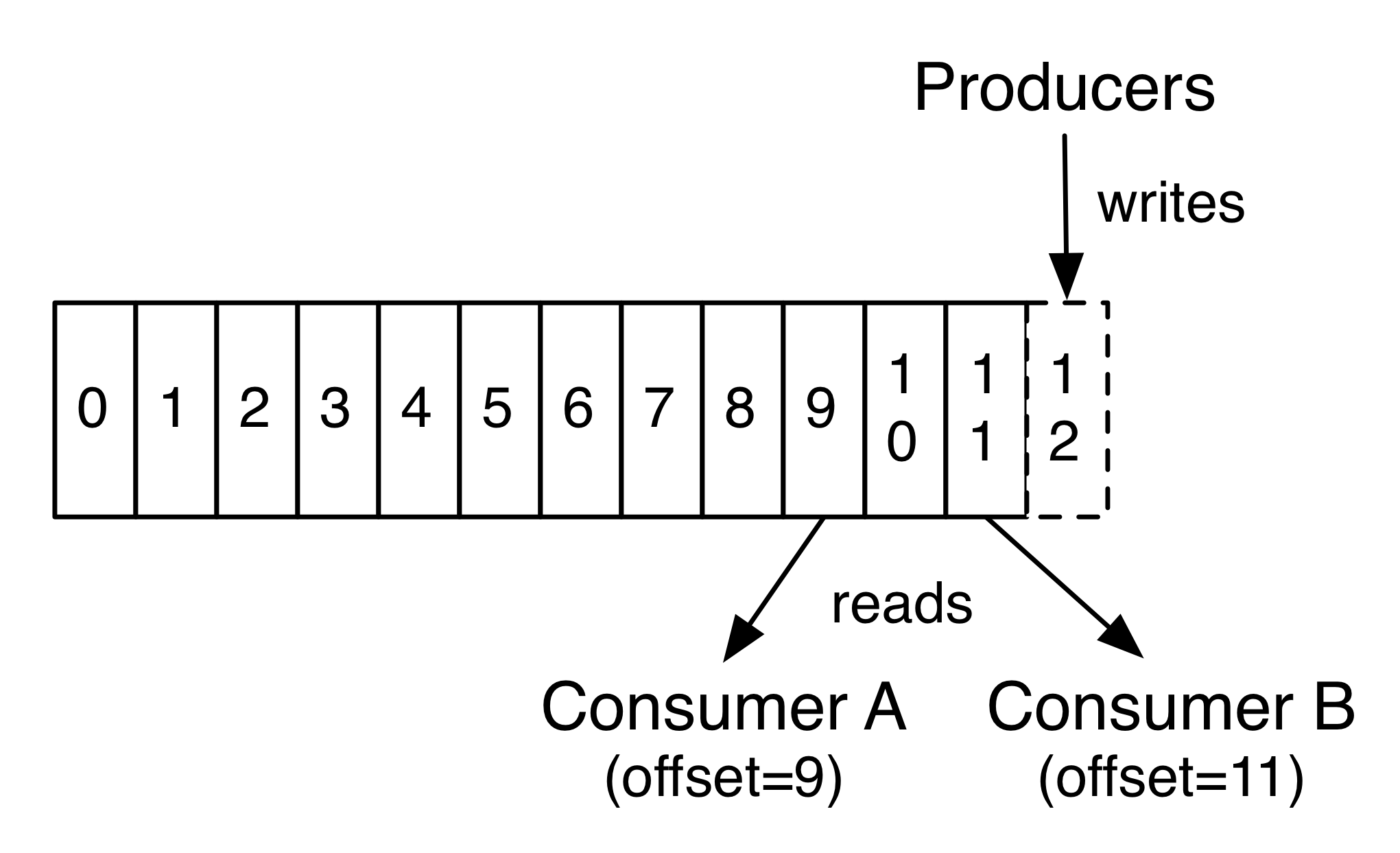
事实上,在每一个消费者上保留的元数据信息是offset或者是consumer在log里面的位置,consumer控制着offset。正常情况下,consumer会按照线性增长的offset来读取消息,但是,事实上,由于consumer控制着offset,所以,它可以以任何顺序来消费消息。例如,consumer可以重新设置一个older的offset来重新处理对应的数据,或者跳跃到最近的记录,从现在开始消费。
消费者的这几个特点意味着它是很轻量级的,他可以来去自如,对集群和其他consumer都没有影响。例如,你可以用命令行工具去tail任何一个topic的内容,从而无需改变任何consumer消费的内容。
在日志里面的分区有几个目的:首先,他们允许日志的大小去适应单个的server,每一个分区必须适合拥有它的server,同时一个个topic可以有很多个分区,所以它可以处理任意数量的数据,第二点:他们扮演着并行的单位。
Distribution
日志分区被分配到kafka的集群上面的server里,每一个server都会处理一部分分区的数据和请求。为了容错,每一个分区都会通过一个可配置的number被复制。
每一个分区都会有一个leader和0到多个follower,leader处理所有的读和写请求,同时follower被动的去复制leader。如果leader宕机了,其中的一个follower会自动变成leader。每一个server即是leader,又是follower,所以在集群里面,对应的负载均衡控制的很好。
Geo-Replication
kafka的镜像同步可以为你的集群提供异地备份,通过镜像同步,消息可以通过很多个数据中心和云区域来复制。你可以用主动或者被动的场景来备份和恢复。或者支持数据本地化的需求。
Producers
producer发布数据到他们选择的topic,在一个topic范围内,producer负责决定一条消息被分配到哪一个分区;为了实现负载均衡,可以用round-robin的方式,也可以用partition这个方法,自己写接口实现。
Consumers
consumers用group name来标注他们自己,每一个被发布到一个topic上的消息都只能被一个订阅的消费者组的其中一个消费者来消费。consumer实例可以在不同的进程中或者不同的机器上面。
如果所有的cosumer实例在同一个组里面,消息会被很好的负责均衡。
如果所有的consumer实例都在不同的组里面,每一条消息都会被广播给每一个consumer进程。
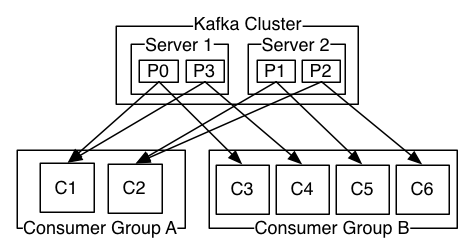
更普遍的是,我们发现了一部分topic,拥有一小部分消费者组,每一个消费者组都是一个逻辑的订阅者。每一个组都有很多个consumer实例组成,来保证可扩展性和容错能力。这不过是一个发布订阅的场景,只不过订阅者是consumer集群而不是单独的进程。
在kafka里面,通过在日志文件里面分割分区来实现消费, 每一个实例都是独有的消费分区,kafka的协议动态的维持着这种关系。如果有新的cousumer实例加入到组里面,他们会从其他成员哪里接管一部分分区;如果一个consumer实例宕机了,它负责的分区将会被分配给其余的实例。
在一个topic里面,kafka仅仅保证在同一个分区里面消息的消费顺序,如果是不同的分区,就不能保证了。对于大多数应用程序来说,每一个分区的排序加上通过key来分配数据到哪个分区,已经能够满足了。然而,如果你需要保证所有消息的顺序,你可以指定一个topic仅包含一个分区,这意味着只能被一个分组中的一个consumer来消费。
Multi-tenancy
kafka可以作为多租户的解决方案,可以通过配置哪些topic可以生产或者消费数据来生效。
Guarantees
kafka可以提供一下保证:
- 通过producer发送到指定topic分区的消息,将会按照他们发送的顺序追加到log文件里面。例如,如果一个producer发送了两条消息M1、M2,M1第一个被发送,那么M1的offset会小于M2的,并且在log文件里出现的地方也要早于M2.
- consumer访问消息的顺序和消息在log里面存储的顺序是一致的。
- 对于一个拥有N个备份的topic,如果有N-1个server宕机,我们也不会丢失任何消息。
Kafka as a Messaging System
kafka流的概念和企业消息系统的比较:
传统的消息有两种类型,queuing and publish-subscribe,在队列里面,有很多个consumer去读取消息集合,每一条消息仅会被其中一个读取到;在发布-订阅模式里,消息会被广播给所有的consumer。这两种模式都有长处和短处;queuing的长处是通过允许消息被分配给多个consumer,来实现扩展你的应用。不幸的是,queues不支持多用户读取消息,一旦一个进程读取到当前消息,它就消失了。Publish-subscribe允许你把数据广播给很多个进程,但是不能扩展程序,因为会传递到每一个subscriber。
kafka里面的消费者组的概念概括了这两个概念;作为一个queuing,consumer group允许你分分割processing 到很多个consumer。作为publish-subscribe,kafka允许你把消息广播给多个consumer groups。
Kafka's model的优势是他的topic同时拥有这两个特点。
和传统的消息系统比起来,kafka对顺序的保证做的更好。
传统的queue在服务器上面保持消息的顺序,如果有很多个consumer来消费,server会分发这些消息。然而,尽管服务器有序的分发这些数据,这些数据被异步到传递给consu,所以他们到达consumer的顺序有可能会被打乱。这实际上意味着,在消费的过程中,数据被打乱了。消息系统通常采取一个单独的consumer来从一个queue消费,当然了,这也意味着不能够并行的去消费数据。
通过使用topic里面的partition概念,kafka做的会好一点。kafka可以同时提供顺序保证和负载均衡,实现的方式是:把topic里面的partitions分配给consumer group中的consumers,每一个分区被consumer group中的一个consumer消费。通过上述做法,这个consumer是唯一一个读取对应分区的并且按照顺序消费数据。因为有很多个分区,所以可以通过分配给多个consumer来实现负载均衡。然而,在一个consumer group里面,consumer的个数不能比partition的个数多。
Kafka as a Storage System
任何允许发布消息、消费消息使指分离,实际上都在扮演着一个存储动态消息的存储系统。kafka是一个很好的存储系统。
写到kafka上的数据实际上是被写入到硬盘,并且为了容错,同时复制了这些数据。kafka允许producer等待确认,意味着写的动作直到被完全备份并且持久化,才被认为完成了写入。
kafka使用硬盘结构使用的非常好,无论要持久化数据量是50KB或者50TB,kafka的执行性能是一样的。
作为认真存储和允许client控制他们自己的read position,你可以认为kafka是一个专注于提供高效率、低延迟、可备份、传播数据的分布式文件系统。
Kafka for Stream Processing
仅仅的读、写、存储数据是不够的,还要能够实时的处理流数据。
在kafka里,流处理指的是从 input topics获取连续的流数据,然后进行处理,最后再输出这些连续的流数据到output topics。
例如,一个零售店的应用,接收销售和发货的input streams,通过技术这些数据,输出成重新排列和价格的output stream。
通过使用producer and consumer APIs可以做一些简单的处理,然而,对于更复杂的转换处理,kafka提供了一个完整的treams API,这允许你去构建不平凡的处理和做一些流聚合、或者把不同的流合并到一起。
这个特性帮助解决了很多难题:处理发生故障的数据、重新处理由代码变化引入的input、执行稳定的计算。
streams API构建在Kafka提供的很多基本的功能上面,利用producer and consumer APIs作为输入,利用kafka作为稳定的存储,同时在不同的stream processor instances,利用同样的组机制实现容错机制。
Putting the Pieces Together
messaging、storage、stream processing的组合看起来很寻常,但是,在kafka扮演的流平台角色里,他们都是必不可少的。
像HDFS这样的分布式文件系统支持批量处理静态数据,同时也允许存储和处理历史数据。
一个传统的企业消息系统允许处理即将到达的订阅的数据,用这种方式构建的应用也可以处理将来的数据。
kafka融合了这两种特性,作为一个处理流应用程序的流平台以及流数据管道,这种组合是至关重要的。
通过storage and low-latency的订阅,流应用可以用相同的方式处理过去和将来的数据。这是一个不仅仅可以处理存储的历史数据,当处理到最后一条历史数据的时候,还可以继续处理将要到来的数据。
这是一个广泛的流处理概念,包括batch processing和message-driven applications。
同样的,对于实时的时间,这种组合的流数据管道使kafka成为了低延时的管道。但是,可靠地存储数据这个特性,使得维护一些重要的数据和一些定期的需要被综合到一起的线下数据成为可能。
流处理这个特性,可以转换处理即将到来的未来数据。
更多详细信息请参考:http://kafka.apache.org/intro#kafka_mq