为什么需要消息中间件
- 异步任务处理
- 系统解构,微服务直接解耦通信的一种方式,不关心系统语言编码实现
- 流量削峰
常用的MQ技术
1. RabbitMQ
1. 1 基于Erlang语言开发。
Erlang是一种面向并发(Concurrency Oriented),面向消息(Message Oriented)的函数式(Functional)编程语言。面向并发技术关键点意味着线程切换成本要低。Erlang并没有传统意义的操作系统的进程和线程的概念,它定义一个运行实体叫Process。Process之间通信不共享任何资源,不需要任何锁机制,减少开销。仅仅依靠消息进行通信。
这样对于临界资源呢? 是不是也就是串行处理了呢?Erlang其实实现高并发关键在于Prcoess的构建,轻量级的,创建销毁快速,之间切换资源消耗低。那么我们java语言中的thread为什么创建销毁,相互切换资源消耗多呢?
Erlang语言与java在并发方面不同
为什么java不能利用这么轻量级的Process机制呢?
java是用户线程,通过一定规则映射到native thread,依赖操作系统的原生线程,之前jdk1.0曾经用过绿色线程,后来舍弃了。
所以java线程的切换,因为需要映射到navtive thread,所以导致操作系统在内核态和用户态切换,资源消耗相对绿色线程多。
erlang使用的是绿色线程。优势是绿色线程是应用级别的线程,可以在不支持线程的OS上使用。缺点是不能利用cpu的多核机制。
CPU和线程数的关系
cpu多核和线程数目什么关系?查看cpu信息,一个socket代表cpu的物理个数,cores per socket代表一个cpu有多个core,每个core一般是1个线程,如果支持超线程技术就是2个线程。所以总的线程数目就是cpus的值,也就是4.
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1Erlang语言特性
- Everything is a process.
- Processes are strongly isolated.
- Process creation and destruction is a lightweight operation.
- Message passing is the only way for processes to interact.
- Processes have unique names.
- If you know the name of a process you can send it a message.
- Processes share no resources.
- Error handling is non-local.
- Processes do what they are supposed to do or fail
1.2 架构
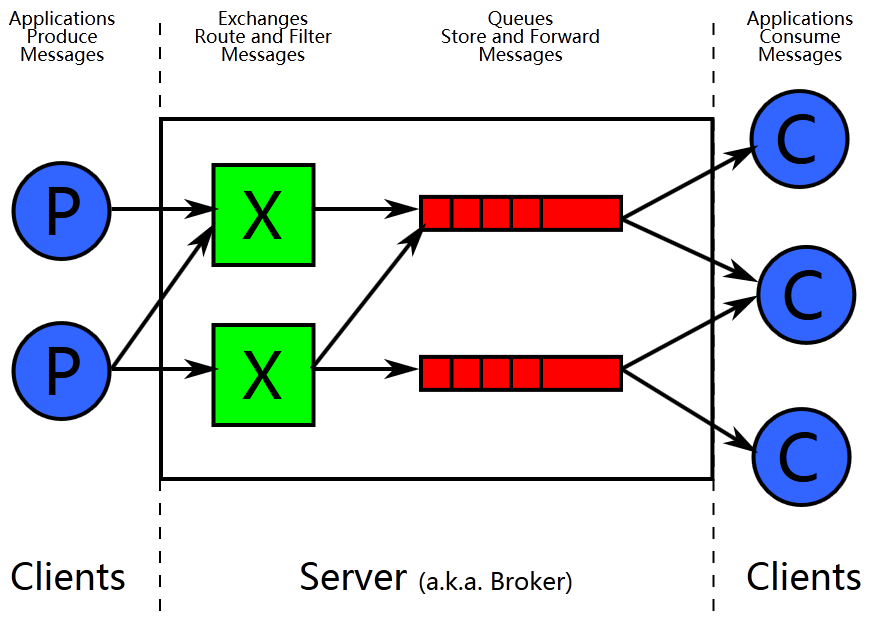
- 生产者发送消息,经过channel到达exchage分发器。exchage根据类型,比如direct,fanout,topic分到对应队列,也可能是动态队列
- Rabbitmq的架构依赖exchage进行分发,性能难免受限制。Kafka是直接分发到topic(rabbitmq叫队列)上
- 如果队列不设置持久化,消息只存在内存中,可能丢失
- 消息如果被消费掉会删除
- Kafka指定消息,通过key进行hash找到分片,然后读取消息。但是Rabbitmq不是,是集中代理,然后路由分发。大部分工作依赖代理去做。
2 Kafka
2.1 生产者分析
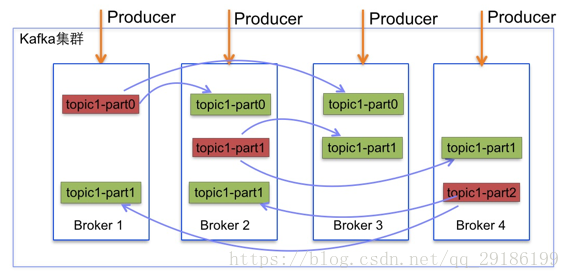
- Kafka对所有对消息进行分类,存储在topic,topic是分片存储的,之所以分片存储,主要是考虑性能问题,类似于redis的分片,大数据文件进行hash拆分,一个道理。分片之后每个数据片都有单点故障问题,所以每个分片都有多个副本,存储在其他节点。可以用副本因子指定副本个数
- 生产者发送消息,根据消息的key进行hash,然后分配到指定对分片,如果希望多个消息到同一个分片,需要相同到key
- 消息到达某个topic后,以分布式日志的形式append log存储,存储有个id,称之为offset,将来可以根据offset任意定位消息。log会分segment,也是性能考虑。kafka是依靠磁盘存储日志的,rabbitmq是依赖内存。
- kafka因为是存储到磁盘文件,所以利用的是顺序IO读取,所以性能较高,避免随机IO读取
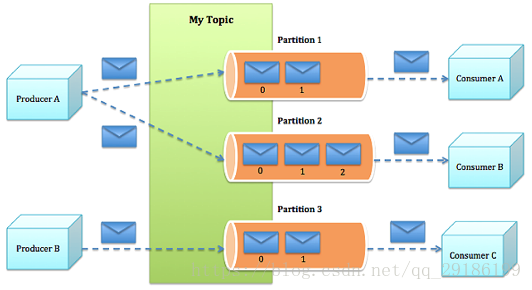
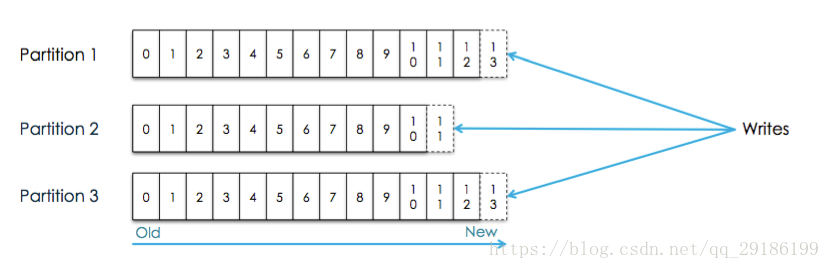
图片来自:https://blog.csdn.net/qq_29186199/article/details/80827085
2.2 消费端分析
消费消息时,有两种模型,一种是pull,消费者主动拉取消息。一种是push,消息代理推送消息给消费者。
- push:优势在于消息实时性高。劣势在于没有考虑consumer消费能力和饱和情况,容易导致producer压垮consumer。
- pull:优势在可以控制消费速度和消费数量,保证consumer不会出现饱和。劣势在于当没有数据,会出现空轮询,消耗cpu
kafka采取拉取模式,rabbitmq采用的是push模型。并采用可配置化参数保证当存在数据并且数据量达到一定量的时候,consumer端才进行pull操作,否则一直处于block状态。kakfa采用整数值consumer position来记录单个分区的消费状态,并且单个分区单个消息只能被consumer group内的一个consumer消费,维护简单开销小。消费完成,broker收到确认,position指向下次消费的offset。由于消息不会删除,在完成消费,position更新之后,consumer依然可以重置offset重新消费历史消息。
2.3 总结
- Kafka消息存储主要依赖磁盘,不是内存,内存成本高,磁盘相对廉价
- Kafka根据topic进行数据分片存储,性能高,而且可靠,通过副本因子决定副本数
- Kafka的消息在topic分片内部通过分布式日志存储,生成id,也就是offset,将来可以直接根据offset读取消息。也可以顺序读取消息 。在顺序读取消息的时候,记录当前读取的offset。下次直接根据offset读取,所以kafka的offset可以直接寻址消息,存储结构应该是数组实现的队列,不是Btree。
- 消费者通过pull方式拉取数据,速率可控,可以消费历史消息
- 消息即时被消费过,也不会删除,依赖过期时间
- 消费者分group,每个消息只能被同一个group的一个consumer消费掉。依赖zookeer进行rebalance,如果出现节点fail的情况
- kafka更加适合于消息比较多的情况,可以有效防止consumer无法及时消费消息。