训练算法:随机梯度上升
>>> np.ones(5)
array([ 1., 1., 1., 1., 1.])
>>> np.ones((5,), dtype=np.int)
array([1, 1, 1, 1, 1])
>>> np.ones((2, 1))
array([[ 1.],
[ 1.]])
>>> s = (2,2)
>>> np.ones(s)
array([[ 1., 1.],
[ 1., 1.]])随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别:第一,后者的变量和误差都是向量,而前者则全是数值;第二,前者没有矩阵的转换过程,所有的变量的数据类型都是Numpy数组
>>> import logRegres
>>> from imp import reload
>>> reload(logRegres)
<module 'logRegres' from 'E:\\Python\\logRegres.py'>
>>> dataArr,labelMat=logRegres.loadDataSet()
>>> weights = logRegres.stoGradAscent(array(dataArr),labelMat)
>>> weights = logRegres.stoGradAscent0(array(dataArr),labelMat)
>>> weights = logRegres.stocGradAscent0(array(dataArr),labelMat)
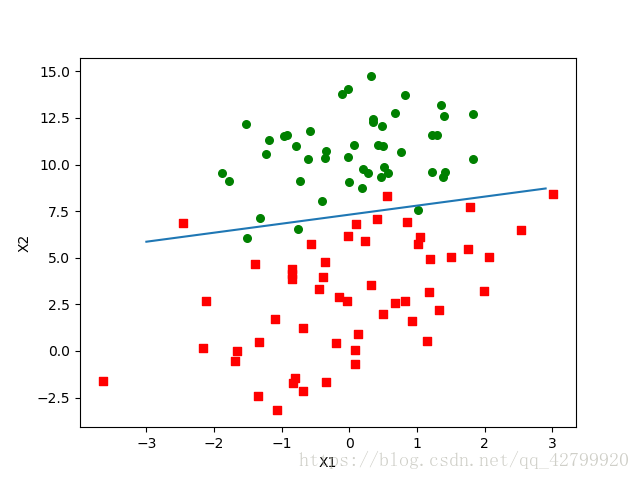
>>> logRegres.plotBestFit(weights)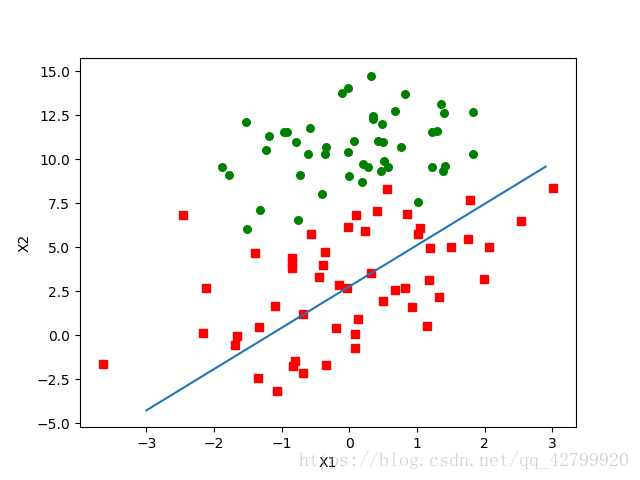
可以看到,拟合出来的直线效果还不错,但并不像之前那么完美,这里的分类器错分了三分之一的样本。
改进的随机梯度上升算法
random.uniform(x, y) 方法将随机生成一个实数,它在 [x,y] 范围内。
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01
randIndex = int(random.uniform(0,len(dataIndex)))
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights第一个改进的地方alpha = 4/(1.0+j+i)+0.01
一方面,alpha在每次迭代的时候都会调整,这回缓解数据波动或者高频波动。另外,虽然alpha会随着迭代次数不断减小,但永远不会减小到0,这是因为其中还存在一个常数项。
必须这样做的原因是为了保证在多次迭代之后新数据依然具有一定的影响。如果要处理的问题是动态变化的,那么可以适当加大上述常数项,来确保新的值获得更大的回归系数。
第二个改进的地方 randIndex = int(random.uniform(0,len(dataIndex)))
通过随机选择样本来更新回归系数,这种方法将减少周期性的波动。