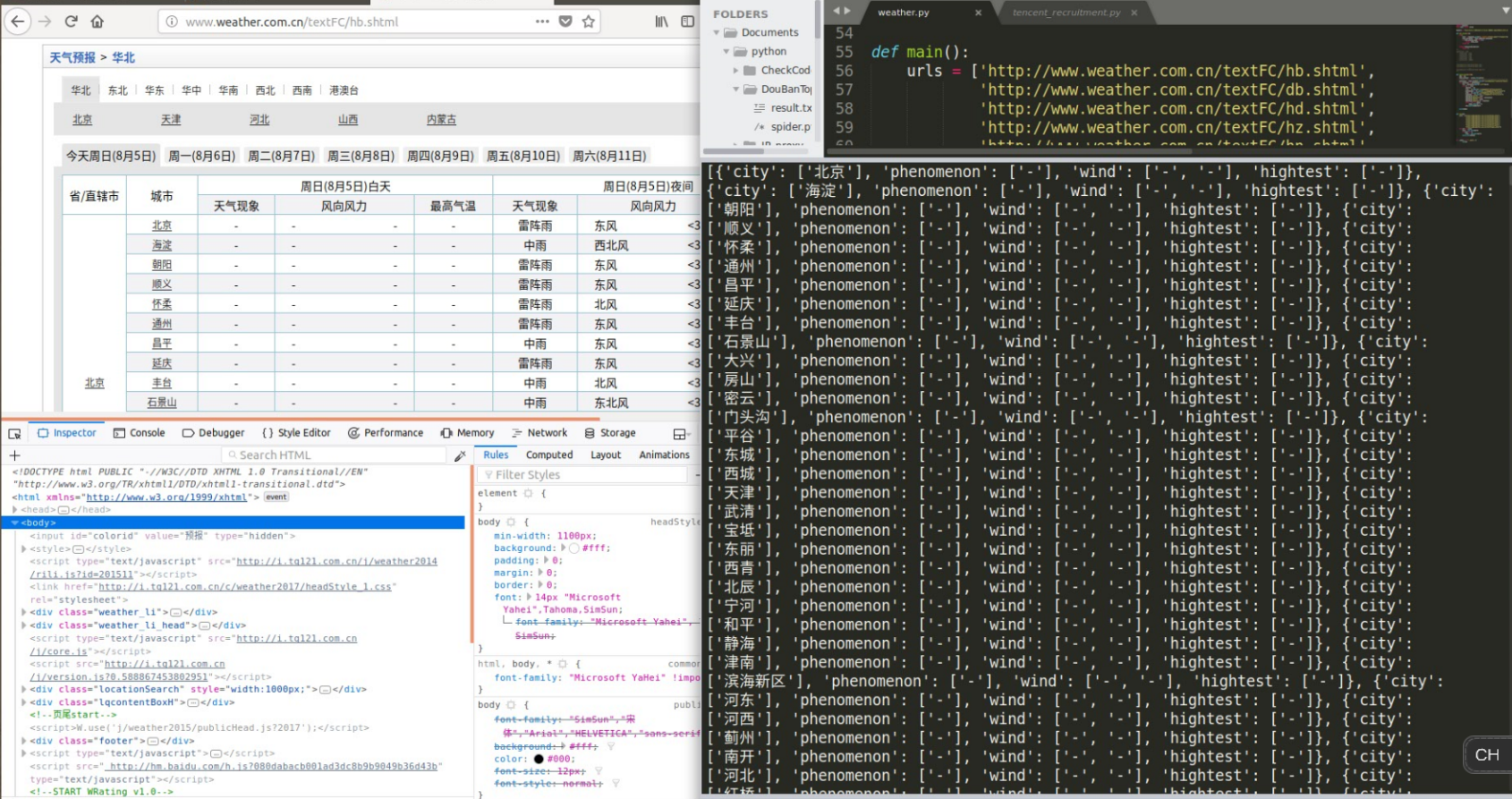
1 import requests 2 from lxml import etree 3 4 headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' 5 6 def get_html(url): 7 try: 8 html = requests.get(url, headers={'User-Agent':'headers'}) 9 html.encoding = html.apparent_encoding 10 if html.status_code == 200: 11 return html.text 12 return 0 13 14 except RequestsException: 15 return 0 16 ''' 17 conMintab: 华北 18 conMintab2 北京 19 conMintab2 天津 20 conMintab2 河北 21 conMintab2 山西 22 conMintab2 内蒙古 23 24 25 //div[@class="conMidtab"][1] 今天 26 //div[@class="conMidtab"][2] 明天 27 ... 28 //div[@class="conMidtab"][7] 最后一天 29 ''' 30 31 def parse_html(html): 32 wea = [] 33 html_element = etree.HTML(html) 34 # !!!!! trs = html_element.xpath('//div[@class="conMidtab"][1]//tr')[2:] 35 provinces = html_element.xpath('//div[@class="conMidtab"][1]//div[@class="conMidtab2"]') 36 for province in provinces: 37 trs = province.xpath('.//tr')[2:] 38 for tr in trs: 39 weather = {} 40 city = tr.xpath('.//td[@width="83"]/a/text()') 41 phenomenon = tr.xpath('.//td[@width="89"]/text()') 42 wind = tr.xpath('.//td[@width="162"]//text()') 43 hightest = tr.xpath('.//td[@width="92"]/text()') 44 weather['city'] = city 45 weather['phenomenon'] = phenomenon 46 weather['wind'] = wind 47 weather['hightest'] = hightest 48 while '\n' in wind: 49 wind.remove('\n') 50 wea.append(weather) 51 52 print(wea) 53 54 55 def main(): 56 urls = ['http://www.weather.com.cn/textFC/hb.shtml', 57 'http://www.weather.com.cn/textFC/db.shtml', 58 'http://www.weather.com.cn/textFC/hd.shtml', 59 'http://www.weather.com.cn/textFC/hz.shtml', 60 'http://www.weather.com.cn/textFC/hn.shtml', 61 'http://www.weather.com.cn/textFC/xb.shtml', 62 'http://www.weather.com.cn/textFC/xn.shtml', 63 'http://www.weather.com.cn/textFC/gat.shtml'] 64 for url in urls: 65 html = get_html(url) 66 if html == 0: 67 html = get_html(url) 68 parse_html(html) 69 70 71 if __name__ == '__main__': 72 main()
。。港澳台的格式不太一样,暂时不想管他们了
。。运行结果的话,我爬取得是当日白天的天气,现在晚上了,数据都没有了(一开始还以为是代码改错了,还一直撤销)