一.正则表达式
正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成,当然如果你是python
爬虫工作者每天跟字符串打交道,正则表达式更是不可或缺的技能,正则表达式在不同的语言中使用方式可能不太一样,不过只要
学会一门语言的正则表达式用法,其他也就只是换个函数的名称而已。下面列举正则中的一些符号的作用。
\d 表示:任意以为数字
\d\d 表示:任意的两位数字
\w 表示:任意的一个数字和字母
\s 表示:空格
. 表示:任意的内容
a. 表示:在a的后面匹配任意的内容
* 表示:前面的一个内容出现0到多次
a.* 表示:a后面的内容出现0到多次
+ 表示:前面的一个内容这个内容出现0到一次
? 表示:前面的一个内......容和内容出现0到一次
^ 表示:以.....开头
$ 表示:以....结尾
{n} 表示:内容重复n次
\d{3} 表示:数字d重复3次
{n,m} 表示:最少重复n次,最多重复m次
\d{3,5} 表示:数字d最少重复3次,最多重复5次
{n,} 表示:最少重复n次
{,m} 表示:最多重复m次
。。。。。。。。。。。。。。。。。。。。。。。
2.上面只是一些正则的一些符号的含义及作用,下面来举一些例子:
#使用正则首先要引入正则要用的模块 在python中正则表达式的模式是可以同时使用多个的,
#在python 里面使用按位或运算符 ,| ,这个符号| 可以同时添加多个模式
#例如:re .compile('',re.I|re.M|re.S)
*****************************************************
#match:匹配的内容是开始部分等同于startswitch
*****************************************************
improt re
#pattern:模式 compile:编译 match:匹配
pattern = re.compile('(\d+)')
content = '123asdfnmsfi'
#后面写的是正则表达式的内容()代表从目标字符串当中获取的子串
result= re.match(pattern,content)
if result:
#返回的是一个匹配的对象
print(result)
print('**************')
#返回的是所有符合要求的全部内容
print(result.group(0))
print(result.group(1))
else:
print('不符合')
运行结果如下:

pattern = re.compile('my')
result = re.match(pattern,'myself')#括号内对象和内容
print(result.group(0))

pattern =re.compile('lalala')
result = re.match(pattern,'halalalaha')
print(result)
pattern = re.compile('my')
result = pattern.match('myself')
print(result)
*****************************************************
#match:匹配的内容是开始部分等同于startswitch
*****************************************************
3.贪婪模式与非贪婪模式
正则表达式默认为贪婪模式即便找到所有的符合要求的内容
.* :称之为贪婪模式
content = "aabbabab11v222"
pattern = re.compile('(a.*b)')
result =pattern.match(content)
print(result)
.*? :称之为非贪婪模式
content = "aabbabab11v222"
pattern= re.compile('(a.*?b)')
result = pattern.match(content)
print(result)
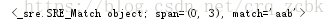
匹配以任意字符开头后面找到一个以b开头以b结尾的内容
content = "aabbabab11v222"
pattern = re.compile('.*?(b.*?b)')
result = pattern.match(content)
print(result)
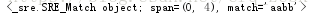
*+ :同为贪婪模式
content = "aabbabab11v222"
pattern = re.compile('(a.+b)')
result =pattern.match(content)
print(result)
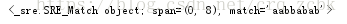
4.search:查找 找到字符串当中第一个符合正则的内容,只找到一个
pattern = re.compile(r'http')
result=pattern.search('www.jd.com,http://www.taobao.com')
print(result)
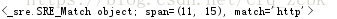
pattern = re.compile(r'you')
result=pattern.search('l love you ,l like you')
print(result)
findall:找到所有符合的内容
content= '12345,上山打老虎,老虎没打着,打只小松鼠,556895555'
pattern = re.compile(r'\d{5}')
result = pattern.findall(content)
print(result)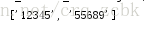
sub:替换子串
content = '杨过对战金轮法王,郭靖观战'
pattern = re.compile(r'杨过')
result = pattern.sub('吕布',content)
print(result)
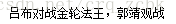
pattern = re.compile(r'^((13[0-9])|(14[67])|(15[0-3])|(15[5-9])|(18[0|5-9]))\d{8}$')
result=pattern.match('15786421053')
print(result)

import re
content = """
today is hot , I
want sleep , I
want go home
"""
pattern = re.compile(r'.*? I(.*?)sleep')
result = pattern.search(content)
print(result)
# re.S 忽视换行符号
pattern = re.compile(r'.*? I(.*?)sleep',re.S)
result = pattern.search(content)
print(result)
二:爬虫
什么是爬虫?
如果把互联网比喻成一张蜘蛛网,我们抓取互联网信息的程序就像是游走在蜘蛛网上的蜘蛛,称之为爬虫
爬虫有什么作用呢?
①:获取信息,填充数据到自己的服务器
②:爬取关键信息,进行商业分析市场评估
③:浏览器
爬虫的分类:
①通用爬虫:全部获取
②聚焦爬虫:只获取自己想要的
爬虫准备:
①:Firefox,google
②Charles
③\了解http通信协议以及数据请求过程
互联网之http协议
http
HTTPS
http://www.baidu.com
http后面的是域名,而域名的实质:ip地址
举个例子:
http://www.apiopen.top/weatherApi?city=上海
协议+域名/ip+路径 以?分割 ?后面的是参数 参数又以等号分割
等号前面的是参数名 后面的是参数值
参数与参数之间又以&隔开
DNS 域名系统将ip地址和域名对应起来
ipv4 : 四组3位数字组成
ip分类:
静态ip
动态ip
ipv6
服务器分类:
1.硬件服务器:理论上任何电脑都可以当做成一个服务器
2.软件服务器:服务器代码
http请求的特点:
1.数据类型比较广泛 json/text/xml/html/data
2.请求是无状态协议的,这次的请求和上次的请求没有任何关系
请求完之后 服务器和客户端的链接会断掉
socket 保持长连接,请求以后服务器和客户端的链接不会断掉
3.http有请求报文和响应报文
请求报文:①:请求行http://www.apiopen,top/weatherApi?city=
②请求头:里面有个User-Agent:标识目标(通过什么方式来访问对象)
host :主机
connection :服务器和客户端之间的链接状态
③:请求体:参数:上海 在请求里面放参数
响应报文:
①状态行
②响应头
③响应体:请求数据就是为了得到响应体
4.http请求方法
method(post,get,delete)
post:可以对数据进行增删改查
get:可以对数据进行增删改查
get和post的区别:
1.get的参数是放到url的后面,是暴露的
post的参数是放在请求体当中,是隐藏的
2.url的长度大小不能超过1kb
get将所有想要的 发送到服务器的内容都放到url中
上传文件要使用post方法
现在就拿百度来做个例子
from urllib.request import Request,urlopen
from prettyprinter import pprint
# urlopen:不支持中英文混写
# urlopen(url) 不能直接这样写
url='http://www.baidu.com'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 替换程序的User-Agent
request=Request(url,headers=headers)
response=urlopen(request)
# decode:解码 encode:编码
print(response.read().decode())输入以上代码会得到百度的首页源码
爬虫/反爬流程
1.判断是否是python urllib (判断禁止爬虫)解决办法: 伪装成User-Agent进行爬虫
2.判断同一个User-Agent 是否多次访问 解决办法:换成不同的User-Agent进行访问
3.判断同一个ip是否多次访问 解决办法:使用不同的ip进行访问
下面就举个例子:
import random
from urllib.request import Request,urlopen,ProxyHandler,build_opener
user_agent_list=['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0']
headers = {
'User-Agent':random.choice(user_agent_list)
}
ip_list=['61.135.217.7:80',
'61.135.217.7:80',
'61.135.217.7:6666'
]
# proxies:代理
proxies={
'http:':random.choice(ip_list)
}
# 设置爬虫目标 以及用户标识
request = Request('http://www.baidu.com',headers=headers)
# 创建ip代理对象
proxy_handler=ProxyHandler(proxies)
# urlopen不支持http高级函数,cookie,验证,代理等内容
# 如果要使用这些内容的话,需要使用build_opener对象进行处理
opener = build_opener(proxy_handler)
response = opener.open(request)
print(response.read().decode())