1、正则表达式
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import re
'''
par="yue"
string="http://yum.iqianyue.com"
rst1=re.search(par,string)#从string中匹配字符串"yue"
print(rst1)
'''
# pat2="\n"
# string3='''jkdjkasdjfak
# dfadjkafhda'''#使用'''可以直接使用换行
# rst2=re.search(pat2,string3)#匹配换行符
# print(rst2)
'''
原子符
\w能匹配任意一个字母、数字或下划线
\d能匹配任意一个十进制数
\s能匹配任意一个空白字符
\W能匹配任意一个非字母、数字或下划线的字符(与\w互补)
\D能匹配任意一个除了十进制数的任意字符(与\D互补)
\S能匹配一个除了空白字符外的任意字符(与\s互补)
[jsz] jsz三个原子平等,可以是j 也可以是s或z
[^j] 匹配除了j以外的任意字符
'''
'''
pat4="\w\dpython\w"
string="hagsda7pythonkkl"
rst4=re.search(pat4,string)
print(rst4)#结果:'a7pythonk'
'''
'''
#[jsz] jsz三个原子平等,可以是j 也可以是s或z
pat5="pyth[jsz]n"
string="pythjnkhsd"
rst5=re.search(pat5,string)#结果:'pythjn'
print(rst5)
'''
'''
元字符
. 匹配除了换行符以外的任意一个字符
^ 匹配字符串开始位置一个字符
$ 匹配字符串结束位置一个字符
* 匹配前面重复零、一或多次同一字符 s表示重复0次 ss表示重复一次
? 匹配前面重复零或一次同一字符
+ 匹配前面重复一次或多次同一字符
{n} n是具体数字,比如n为3,表示前面字符恰好出现了3次,连在一起的,相当于重复了3次
{n,} n是具体数字,比如n为6,表示前面字符至少出现了6次,即至少重复了6次
{n,m} n,m都是具体数字,比如n为3,m为6,表示前面字符至少出现了3次,至多出现了6次
| 或运算,比如:t|s 表示为字符为t或者s
'''
'''
pat6=".python..."
string="shjdhjfkapythonjkda"
print(re.search(pat6,string))
'''
'''
模式修正符
I 匹配时忽略大小写
M 进行多行匹配
L 本地化识别匹配
U 根据Unicode编码解析字符
S 让.的匹配也包括换行符
'''
'''
pat6="python"
pat7="python"
string="dafjkafPythonjkdsaf"
print(re.search(pat6,string))#没有采用模式修正符 结果:None
print(re.search(pat7,string,re.I))#采用了模式修正符 结果:Python(大写的Python)
'''
'''
贪婪模式和懒惰模式
pat8="p.*y"#贪婪模式
pat9="p.*?y"#懒惰模式
string="dasfjapythondfaky"
print(re.search(pat8,string))#贪婪模式 结果:pythondfaky
print(re.search(pat9,string))#懒惰模式 结果:py
'''
pat8="p.*y"#贪婪模式
pat9="p.*?y"#懒惰模式
string="dasfjapythondfaky"
string1="dasfpdjfayjkdjafpdjakfy"
print(re.match(pat8,string))#match从头开始匹配,结果:None 因为"dasfjapythondfaky"不是以p开头的
print(re.search(pat9,string1))#search匹配到一个就结束,不进行多个匹配并且返回第一个匹配成功的 结果:pdjfay
print(re.compile(pat9).findall(string1))#进行全局搜索,能匹配多个 结果:['pdjfay', 'pdjakfy']2、urllib的使用

#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import urllib.request
import re
pat='<span class="title">(.*?)</span>'
data=urllib.request.urlopen("https://edu.csdn.net/courses/o280_k%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80").read()
result=re.compile(pat).findall(str(data.decode("utf-8")))#注意:汉字需要进行解码,这个要以网站编码的字符集为准,一般都为utf-8
#将爬取到的内容写入到文件中
file=open("J:\\Program\\Python\\Python爬虫\\文本爬取页面信息1.txt","w")
for i in range(0,len(result)):
file.write(result[i]+"\n")
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import urllib.request
import re
#将指定url爬取存储在本地的1.html下
# urllib.request.urlretrieve("http://www.ctgu.edu.cn/zzjg/xysz.htm",filename="J:\\Program\\Python\\Python爬虫\\文本\\1.html")
# urllib.request.urlcleanup()#将urllib.request.urlretrieve产生的缓存清理掉
'''
file=urllib.request.urlopen("http://www.ctgu.edu.cn/zzjg/xysz.htm")
#print(file.info())#获取一些http的信息
print(file.getcode())#获取连接的状态码,200是正常,403、404等是异常
print(file.geturl())#获取当前爬取的网址名称
'''
file=urllib.request.urlopen("http://www.ctgu.edu.cn/zzjg/xysz.htm",timeout=1)#timeout是设置超时时间,如果超过所设置的时间还没有对方服务器还没有返回信息则判定失败并抛出异常
print(file)3、异常处理
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
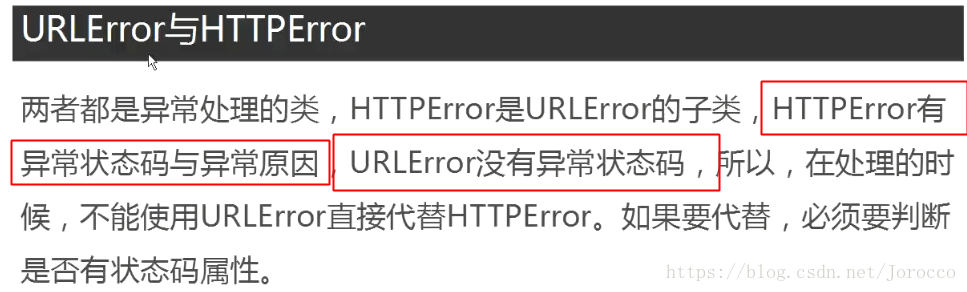
出现URLError的原因:
1、连不上服务器
2、远程的url不存在
3、本地网络不通
4、触发了HTTPError子类
'''
import urllib.error
import urllib.request
try:
data=urllib.request.urlopen("http://blog.csdn.net")
print(data)
except urllib.error.URLError as e:
if hasattr(e,"code"):#判断异常中是否有状态码,如果有则打印出来
print(e.code)
if hasattr(e,"reason"):
print(e.reason)4、几种简单的爬虫防屏蔽方法
4.1 浏览器伪装
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import urllib.request
url="http://blog.csdn.net/Jorocco/article/list/1?"
#设置报头变量
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0")
#添加报头信息
opener=urllib.request.build_opener()
opener.addheaders =[headers]
#以报头的形式打开,也就是伪装成了浏览器对网页进行相应的请求
data=opener.open(url).read()
file=open("J:\\Program\\Python\\Python爬虫\\伪装成浏览器模式访问.html","wb")
file.write(data)
file.close()爬取新浪新闻网站上所有的新闻信息
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
将新浪新闻网页上的所有新闻链接中的内容爬取并存储到磁盘上
同时进行了异常处理,即当出现异常时它并不会终止(如果不进行处理则会终止)
它只会忽略本次错误,继续进行其他的处理
'''
import urllib.request
import urllib.error
import re
data=urllib.request.urlopen("http://news.sina.com.cn/").read()
data2=data.decode("utf-8","ignore")#如果不能进行相应的编码将其忽略并继续执行编码
pat='href="(http://news.sina.com.cn/.*?)"'
allurl=re.compile(pat).findall(data2)#在爬取到的页面中匹配所有的新闻链接
for i in range(0,len(allurl)):
try:
print("第"+str(i)+"次爬取")
thisurl=allurl[i]
file="J:\\Program\\Python\\Python爬虫\\文本\\news\\"+str(i)+".html"
urllib.request.urlretrieve(thisurl,file)#爬取每条新闻并存储到磁盘
print("-----成功------")
except urllib.error.URLError as e:#遇到异常时,它会进行下面的处理,而不会因此异常中断本程序,它进行相应的处理,并继续处理其他的
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)4.2 模拟http请求
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import urllib.request
'''
以下处理的是get请求
'''
keyword="python"
'''
#当搜索关键词出现中文的时候则需要进行以下处理
key="爬虫"
key=urllib.request.quote(key)
'''
# url="https://www.baidu.com/s?wd="+keyword #此处如果直接用https则爬取不到,因为https是需要证书认证的,而我们没有进行相应的设置
url="http://www.baidu.com/s?wd="+keyword
req=urllib.request.Request(url)#模拟http请求
data=urllib.request.urlopen(req).read()#将请求打开,爬取请求对应的数据,爬取到的页面相当于在百度搜索引擎里面输入python得到的页面
file=open ("J:\\Program\\Python\\Python爬虫\\Python关键字爬取页面信息.html","wb")
file.write(data)
file.close()#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
模拟post请求登陆
'''
import urllib.request
import urllib.parse
url="http://www.iqianyue.com/mypost"
mydata=urllib.parse.urlencode({
#模拟表单登陆(具体的要看网页的源代码)
"name":"cdndj@dfasfj",
"pass":"dfajkdf"
}).encode("utf-8")#进行相应的网页编码
req=urllib.request.Request(url,mydata)#设置请求
data=urllib.request.urlopen(req)
file=open("J:\\Program\\Python\\Python爬虫\\模拟post表单登陆.html","wb")
file.write(data)
file.close()
伪装成http请求爬取csdn页面上的所有博文
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
import urllib.request
import re
url="https://blog.csdn.net/nav/cloud"
#伪装成http请求
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#将该种方式设置成全局,否则只有opener.open()方法才被伪装成了http请求
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
#设置正则表达式匹配该网址中所需要爬取的其他博客链接
pat=' <a strategy="new" href="(.*?)"'
result=re.compile(pat).findall(data)
for i in range(0,len(result)):
file="J:\\Program\\Python\\Python爬虫\\文本\\博文\\"+str(i)+".html"
urllib.request.urlretrieve(result[i],filename=file)
print("第"+str(i+1)+"次爬取成功")4.3 代理服务器防屏蔽爬虫

#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
使用代理IP爬取相应的信息:
使用同一个IP大量爬取同一个网站,有可能被对方服务器给封掉
所以采用代理IP来防屏蔽
'''
import urllib.request
def use_proxy(url,proxy_addr):
proxy=urllib.request.ProxyHandler({"http":proxy_addr})#获取代理IP
#建立一个代理ip打开句柄
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
#将其设置成全局,这样使用urlopen也使用的是代理ip
urllib.request.install_opener(opener)
#爬取相应的网页
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
return data
proxy_addr="123.53.86.114:61234"#代理IP
url="http://www.baidu.com"
data=use_proxy(url,proxy_addr)
print(len(data))5、爬取淘宝图片
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
1、首先通过火狐浏览器对网址访问进行分析找到关键词(连衣裙)所在的位置
以及每页的图片数量位置所在地
2、对每高清图片网址进行分析,首先判断高清图片网址是否嵌套在搜索页面源码中
3、如果没有则采取抓包的方式获取它的网址,并找出所有的共性,通过正则表达式匹配出其高清图片所在网址
4、通过对图片网页进行爬取相对应的图片
'''
import urllib.request
import re
keyname="男士衬衫"
#对中文进行编码
key=urllib.request.quote(keyname)
#伪装成火狐的http请求
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0")
opener=urllib.request.build_opener()
opener.addhandlers=[headers]
urllib.request.install_opener(opener)
for i in range(1,3):
#设置关键词在q的后面,每页的数量为44,所以可以很容易判断第二页、第三页以及其他页的网址
url="http://s.taobao.com/search?q="+key+"&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180512&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(44*(i-1))
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
#"pic_url":"//g-search1.alicdn.com/img/bao/uploaded/i4/i2/2878066472/TB2H91OepuWBuNjSszbXXcS7FXa_!!2878066472.jpg"
#上面是嵌套在源码中的其中一张图片网址没有加http://的网址,所有可以通过正则表达式将其匹配下来,通过拼接http://则可变成每张图片的网址
#可以通过拼接的网址进行访问验证
pat='"pic_url":"//(.*?)"'
#找到每一页中所有图片没有http://头的网址
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
thisime=imagelist[j]
#拼接图片网址
thisimgurl="http://"+thisime
#设置爬取到的图片存储地
file="J:\\Program\\Python\\Python爬虫\\文本\\淘宝图片\\"+str(i)+str(j)+".jpg"
#将图片爬取下来并存储在磁盘上
urllib.request.urlretrieve(thisimgurl,filename=file)6、多线程爬虫
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
爬取糗事百科的段子:
定义两个线程进行爬取
one线程爬取奇数页
two线程爬取偶数页
'''
import urllib.request
import re
import threading
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0")
opener=urllib.request.build_opener()
opener.addhandlers=[headers]
urllib.request.install_opener(opener)
class One(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(1,36,2):
url="https://www.qiushibaike.com/8hr/page/"+str(i)
pagedata=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'
datalist=re.compile(pat,re.S).findall(pagedata)
for j in range(0,len(datalist)):
print("第"+str(i)+"页第"+str(j)+"个段子的内容是:")
print(datalist[j])
class Two(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(0,36,2):
url="https://www.qiushibaike.com/8hr/page/"+str(i)
pagedata=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'
datalist=re.compile(pat,re.S).findall(pagedata)
for j in range(0,len(datalist)):
print("第"+str(i)+"页第"+str(j)+"个段子的内容是:")
print(datalist[j])
one=One()
one.start()
two=Two()
two.start()7、通过fidder抓包分析抓取相应的网页
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
'''
需求:抓取腾讯视频的电视剧评论
1、由于在电视剧显示页面源码中看不到电视剧评论源码(隐藏在js源码中)
2、为此我们需要采取抓包的方式将其电视剧评论源码抓取出来(可以在抓包工具中先清空所有的抓到的东西,然后点击
评论页面中的查看更多即可抓取到相应的js)
3、复制其url对其分析,找到评论页面的差异点,即实现自动点击查看更多评论并将其抓取出来
4、一个关键点是找到上一个页面与查看更多页面的连接点,通过对源码分析可知它们的关键点在于id,并在上一个页面中有指出
点击查看更多后的页面的id
'''
import urllib.request
import re
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0")
opener=urllib.request.build_opener()
opener.addhandlers=[headers]
urllib.request.install_opener(opener)
#第一个页面的id 这个id就是构成下一个访问的关键点
comid="6398026902994256488"
url="http://video.coral.qq.com/varticle/2618907668/comment/v2?callback=_varticle2618907668commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+comid+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1526210499177"
for i in range(0,1):
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
#通过上一个页面找到下一个页面的id
patnext='"last":"(.*?)"'
nextid=re.compile(patnext).findall(data)[0]
#找到表示评论内容的代码,由于它是unicode编码,所以在下面需要将它解码
patcom='"content":"(.*?)",'
#匹配出所有评论
comdata=re.compile(patcom).findall(data)
try:
for j in range(0,len(comdata)):
print("----第"+str(i)+str(j)+"条评论内容是:")
#解码
print(eval(u"'"+comdata[j]+"'"))
url="http://video.coral.qq.com/varticle/2618907668/comment/v2?callback=_varticle2618907668commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+nextid+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1526210499177"
except UnicodeEncodeError:
pass爬取微信上的所有文章
#http://weixin.sogou.com/
import re
import urllib.request
import time
import urllib.error
import urllib.request
#自定义函数,功能为使用代理服务器爬一个网址
def use_proxy(proxy_addr,url):
#建立异常处理机制
try:
#伪装成浏览器
req=urllib.request.Request(url)
#添加http头
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0')
#使用代理服务器
proxy= urllib.request.ProxyHandler({'http':proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read()
return data
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#若为URLError异常,延时10秒执行
time.sleep(10)
except Exception as e:
print("exception:"+str(e))
#若为Exception异常,延时1秒执行
time.sleep(1)
#设置关键词
key="Python"
#设置代理服务器,该代理服务器有可能失效,读者需要换成新的有效代理服务器
proxy="127.0.0.1:8888"
#爬多少页
for i in range(0,10):
key=urllib.request.quote(key)
thispageurl="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(i)
#a="http://blog.csdn.net"
thispagedata=use_proxy(proxy,thispageurl)
print(len(str(thispagedata)))
#提取本页中所有文章的url
pat1='<a href="(.*?)"'
#re.S 匹配的内容也包括换行符
rs1=re.compile(pat1,re.S).findall(str(thispagedata))
if(len(rs1)==0):
print("此次("+str(i)+"页)没成功")
continue
for j in range(0,len(rs1)):
thisurl=rs1[j]
#经分析发现爬取到的url得去掉amp才能访问(微信的反爬)
thisurl=thisurl.replace("amp;","")
file="F:/天善-Python数据分析与挖掘课程/result/32/第"+str(i)+"页第"+str(j)+"篇文章.html"
thisdata=use_proxy(proxy,thisurl)
try:
fh=open(file,"wb")
fh.write(thisdata)
fh.close()
print("第"+str(i)+"页第"+str(j)+"篇文章成功")
except Exception as e:
print(e)
print("第"+str(i)+"页第"+str(j)+"篇文章失败")