这篇文章算是本人学完python之后的复习回顾吧,做个小总结。自己在学习使用python的过程中,遇到不是很明白的东西,都是去查阅廖雪峰老师的教程,写的还是非常好并且非常容易理解的。之前刚开始学python的时候,也转载过一些博客,里面很多其实也都讲的非常好,这里主要讲一些面试时可能会问到的或者平常容易记混的知识点好了,咳咳,划重点咯
0.简单介绍下python
Python是解释型语言。这意味着不像C和其他语言,Python运行前不需要编译。
1.Python是动态类型的,这意味着你不需要在声明变量时指定类型。你可以先定义x=111,然后 x=”I’m a string”。
2.Python是面向对象语言,所有允许定义类并且可以继承和组合。Python没有访问标识如在C++中的public, private,
3.在Python中,函数是一等公民。这就意味着它们可以被赋值,从其他函数返回值,并且传递函数对象。类不是一等公民。
4.写Python代码很快,但是跑起来会比编译型语言慢。幸运的是,Python允许使用C扩展写程序,所以瓶颈可以得到处理。Numpy库就是一个很好例子,因为很多代码不是Python直接写的,所以运行很快。
5.Python使用场景很多 – web应用开发、大数据应用、数据科学、人工智能等等。它也经常被看做“胶水”语言,使得不同语言间可以衔接上。
6.Python能够简化工作 ,使得程序员能够关心如何重写代码而不是详细看一遍底层实现。
1.迭代器和生成器
廖雪峰 生成器
生成器:
(1)要创建一个generator,只要把一个列表生成式的 [] 换成 ()
(2)带有yield的函数不再是一个普通函数,而是一个生成器。函数调用时,返回一个generator对象,用next()函数进行调用。在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
廖雪峰 迭代器
迭代器:
是访问集合元素的一种方式,从集合的第一个元素开始访问,直到所有元素被访问结束。
其优点是不需要事先准备好整个迭代过程中的所有元素,仅在迭代到某个元素时才开始计算该元素。
适合遍历比较巨大的集合。
iter():方法返回迭代器本身,
next():方法用于返回容器中下一个元素或数据。
'''迭代器'''
print('for x in iter([1, 2, 3, 4, 5]):')
for x in iter([1, 2, 3, 4, 5]):
print(x)
'''生成器'''
def myyield(n):
while n>0:
print("开始生成...:")
yield n
print("完成一次...:")
n -= 1
for i in myyield(4):
print("遍历得到的值:",i)输出:
for x in iter([1, 2, 3, 4, 5]):
1
2
3
4
5
开始生成...:
遍历得到的值: 4
完成一次...:
开始生成...:
遍历得到的值: 3
完成一次...:
开始生成...:
遍历得到的值: 2
完成一次...:
开始生成...:
遍历得到的值: 1
完成一次...:2.装饰器(Decorator)
廖雪峰 装饰器
在代码运行期间动态增加功能的方式,称之为“装饰器”
装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景。比如:插入日志、性能测试、事务处理、缓存、权限校验等。有了装饰器我们就可以抽离出大量的与函数功能无关的雷同代码进行重用。
#定义一个能够打印日志的装饰器
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
# log是一个decrator,接受一个函数作为参数,并返回一个函数。借助 @ 语法,把decorator置于函数的定义处
@log
def now():
print('2015-3-25')
# 把@log放到now()函数的定义处,相当于执行了语句:now = log(now)
# 调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
now()输出:
call now():
2015-3-253、*args 和 **kwargs
这两个是Python中的可变参数,用于接受参数的传递。*args表示任何多个无名参数,它是一个元组,**kwargs表示关键字参数,它是一个字典。同时使用*args和**kwargs时,必须*args在**kwargs之前。
如果我们不确定往一个函数中传入多少参数,或者我们希望以元组(tuple)或者列表(list)的形式传参数的时候,我们可以使用*args(单星号)。如果我们不知道往函数中传递多少个关键词参数或者想传入字典的值作为关键词参数的时候我们可以使用**kwargs(双星号),args、kwargs两个标识符是约定俗成的用法。
另一种答法:当函数的参数前面有一个星号号的时候表示这是一个可变的位置参数,两个星号表示这个是一个可变的关键词参数。星号把序列或者集合解包(unpack)成位置参数,两个星号把字典解包成关键词参数。
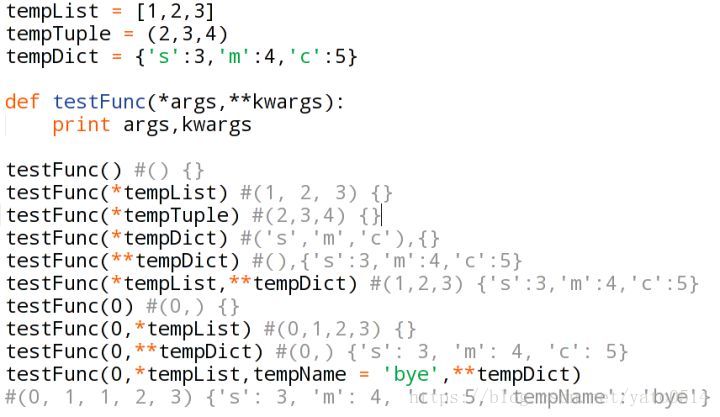
4.@staticmethod 和 @classmethod
Python中有三种方法,实例方法、类方法(@classmethod)、静态方法(@staticmethod)。
类方法的第一个参数是cls,表示该类的一个实例,静态方法基本上和一个全局函数相同
class A(object):
def foo(self, x):
print("executing foo(%s,%s)" % (self, x))
print('self:', self)
@classmethod
def class_foo(cls, x):
print("executing class_foo(%s,%s)" % (cls, x))
print('cls:', cls)
@staticmethod
def static_foo(x):
print("executing static_foo(%s)" % x)
a = A()
print(a.foo(1))
print(a.class_foo(1))
print(a.static_foo(1))输出:
executing foo(<__main__.A object at 0x00000000011684E0>,1)
self: <__main__.A object at 0x00000000011684E0>
None
executing class_foo(<class '__main__.A'>,1)
cls: <class '__main__.A'>
None
executing static_foo(1)
None5.简要描述Python的垃圾回收机制(garbage collection)
Python中的垃圾回收是以引用计数为主,标记-清除和分代收集为辅。
引用计数:当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1,当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
标记-清除:1. 寻找跟对象(root object)的集合作为垃圾检测动作的起点,跟对象也就是一些全局引用和函数栈中的引用,这些引用所指向的对象是不可被删除的;2. 从root object集合出发,沿着root object集合中的每一个引用,如果能够到达某个对象,则说明这个对象是可达的,那么就不会被删除,这个过程就是垃圾检测阶段;3. 当检测阶段结束以后,所有的对象就分成可达和不可达两部分,所有的可达对象都进行保留,其它的不可达对象所占用的内存将会被回收,这就是垃圾回收阶段。(底层采用的是链表将这些集合的对象连接在一起)
分代收集:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,Python默认定义了三代对象集合,垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。
6.闭包
闭包可以实现先将一个参数传递给一个函数,而并不立即执行,以达到延迟求值的目的。满足以下三个条件:必须有一个内嵌函数;内嵌函数必须引用外部函数中变量;外部函数返回值必须是内嵌函数。
def delay_fun(x, y):
def caculator():
return x+y
return caculator
print('返回一个求和的函数,并不求和')
msum = delay_fun(3,4)
print('调用并求和:')
print(msum())输出:
返回一个求和的函数,并不求和
调用并求和:
77.lambda表达式
lambda表达式通常是当你需要使用一个函数,但是又不想费脑袋去命名一个函数的时候使用,也就是通常所说的匿名函数。
lambda表达式一般的形式是:关键词lambda后面紧接一个或多个参数,紧接一个冒号“:”,紧接一个表达式。lambda表达式是一个表达式不是一个语句。
#!/usr/bin/python3
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))8.map/reduce
廖雪峰 map/reduce
map()函数
接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
['1', '2', '3', '4', '5', '6', '7', '8', '9']reduce()
把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)把序列[1, 3, 5, 7, 9]变换成整数13579:
>>> from functools import reduce
>>> def fn(x, y):
... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
135799.filter()和sorted
廖雪峰 filter
filter()函数用于过滤序列。
filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
#在一个list中,删掉偶数,只保留奇数
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]廖雪峰 sorted
sorted()函数就可以对list进行排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
#给sorted传入key函数,即可实现忽略大小写的排序。要进行反向排序,不必改动key函数
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']10.深拷贝和浅拷贝
Python中对象之间的赋值是按引用传递的,如果要拷贝对象需要使用标准模板中的copy
copy.copy:浅拷贝,只拷贝父对象,不拷贝父对象的子对象。
copy.deepcop:深拷贝,拷贝父对象和子对象。
import copy
tempList = [0,1,2,[3,4]]
testList = tempList
testCopyList = copy.copy(tempList)
testDeepCopyList = copy.deepcopy(testList)
tempList.append('sign')
print(testList,testCopyList,testDeepCopyList)
testList[3].append('sign')
print(testList,testCopyList,testDeepCopyList)输出:
[0, 1, 2, [3, 4], 'sign'] [0, 1, 2, [3, 4]] [0, 1, 2, [3, 4]]
[0, 1, 2, [3, 4, 'sign'], 'sign'] [0, 1, 2, [3, 4, 'sign']] [0, 1, 2, [3, 4]]11.@property 和 @setter
@property负责把一个方法变成属性调用。在对实例操作时,不暴露接口,而是通过getter和setter方法实现。
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an intager')
if value<0 or value>100:
raise ValueError('score must between 0~100!')
self._score = value
s = Student()
s.score = 60
print(s.score)
s.score = 999
print(s.score)输出:
60
Traceback (most recent call last):
File "0.py", line 17, in <module>
s.score = 999
File "0.py", line 11, in score
raise ValueError('score must between 0~100!')
ValueError: score must between 0~100!12.、_new_和_init_
_ _ init _ 为初始化方法, _ new_ _ 方法是真正的构造函数。
_ _ new_ _是实例创建之前被调用,它的任务是创建并返回该实例,是静态方法
_ _ init_ _是实例创建之后被调用的,然后设置对象属性的一些初始值。
总结:_ _ new _ 方法在 _ init_ _ 方法之前被调用,并且_ _ new_ _ 方法的返回值将传递给init方法作为第一个参数,最后_ _ init_ _ 给这个实例设置一些参数。
13、多进程和多线程
进程:是资源分配的最小单位,创建和销毁开销较大;
线程:是CPU调度的最小单位,开销小,切换速度快;
操作系统将CPU时间片分配给多个线程,每个线程在指定放到时间片内完成。操作系统不断从一个线程切换到另一个线程执行,宏观上看就好像是多个线程一起执行。
Python中由于全局锁 (GIL) 的存在导致,同一时间只有一个获得GIL的线程在跑,其他线程则处于等待状态,这导致了多线程只是在做分时切换,并不能利用多核。
多线程与多进程的区别:(1)多进程中同一个变量各自有一份拷贝在每个进程中,互不影响;(2)多线程中,所有变量都由所有线程共享,任何一个变量都可被任何一个线程修改。线程之间共享数据的最大危险在于多个线程同时更改一个变量,把内容改乱。
from multiprocessing import Pool #多进程
from multiprocessing.dummpy import Pool #多线程
14.Python自省
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型。简单一句话就是运行时能够获得对象的类型。比如:type()、dir()、getattr()、hasattr()、isinstance()
15.random模块
随机整数:
random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:
random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
16.Python是如何进行内存管理的?
从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
17.回文
“回文”的意思是:首尾依次相等。比如:abcdedcba