1、tensorflow里的四种交叉熵的实现跟计算:
注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出它适用于每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象output不是一个数,而是一个batch中每个样本的loss,并且其属于一个多分类的应用,例如验证码图的识别,其是输出多个类别的。所以一般配合tf.reduce_mea(loss)使用计算公式:
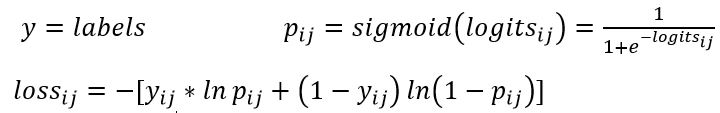
相应的测试代码:
import tensorflow as tf
import numpy as np
def sigmoid(x):
return 1.0/(1+np.exp(-x))
y=np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]])
logits=np.array([[12,3,2],[3,10,1],[1,2,5],[4,6,1.2],[3,6,1]])
y_pred=sigmoid(logits)
E1=-y*np.log(y_pred)-(1-y)*np.log(1-y_pred)
print(E1)
sess=tf.Session()
#astype是把y转换为float64的数据类型
y=np.array(y).astype(np.float64)
#这个交叉熵,其一般返回的是一个tensor,其包括每个输入样本的loss,则其维度跟输入的batchsize大小一样
#所以其是跟tf.reduce_mean(loss)函数配合使用。输出是平均loss
E2=sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
MeanE2=tf.reduce_mean(E2)
print(E2)
print("MeanLoss:",sess.run(MeanE2));
def softmax(x):
sum_raw=np.sum(np.exp(x),axis=-1)
x1=np.ones(np.shape(x))
for i in range(np.shape(x)[0]):
x1[i]=np.exp(x[i])/sum_raw[i]
return x1
#这里相当于五个batchsize
y=np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])
logits=np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1],[3,6,1]])
y_pred=softmax(logits)
E1=-np.sum(y*np.log(y_pred),-1)
print(E1)
sess=tf.Session()
y=np.array(y).astype(np.float64)
E2=tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=y)
print(sess.run(E2))上面代码的输出情况:
[[6.14419348e-06 3.04858735e+00 2.12692801e+00]
[3.04858735e+00 4.53988992e-05 1.31326169e+00]
[1.31326169e+00 2.12692801e+00 6.71534849e-03]
[1.81499279e-02 2.47568514e-03 1.46328247e+00]
[3.04858735e+00 2.47568514e-03 1.31326169e+00]]
[[6.14419348e-06 3.04858735e+00 2.12692801e+00]
[3.04858735e+00 4.53988992e-05 1.31326169e+00]
[1.31326169e+00 2.12692801e+00 6.71534849e-03]
[1.81499279e-02 2.47568514e-03 1.46328247e+00]
[3.04858735e+00 2.47568514e-03 1.31326169e+00]]
MeanLoss: 1.2555035864316637
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58265938e+00
5.49852354e-02]
[1.68795487e-04 1.03475622e-03 6.58839038e-02 2.58265938e+00
5.49852354e-02]注释:其中两次的E1、E2都输出结果都相同。
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,即单分类的。而不能同时包含一条狗和一只大象output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用计算公式:
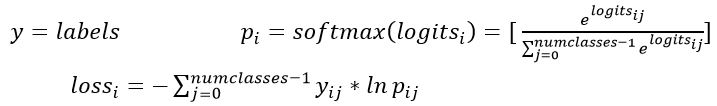
2、使用tf.gradients()实现对函数求导。
在tensorflow中,tf.gradients()的参数如下:
tf.gradients(ys, xs,
grad_ys=None,
name='gradients',
colocate_gradients_with_ops=False,
gate_gradients=False,
aggregation_method=None,
stop_gradients=None)更进一步,tf.gradients()接受求导值ys和xs不仅可以是tensor,还可以是list,形如[tensor1, tensor2, …, tensorn]。当ys和xs都是list时,它们的求导关系为:
gradients()adds ops to the graph to output the derivatives ofyswith respect toxs. It returns a list ofTensorof lengthlen(xs)where each tensor is thesum(dy/dx)for y inys.

基础实践
以线性回归为例,实践tf.gradients()的基础功能。线性回归:y=3*x+2 :
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Prepare train data
train_X = np.linspace(-1, 1, 200)
train_Y = 2 * train_X + 10
# Define the model
#这些定义的变量可以在多个batch时进行并行运算
X = tf.placeholder("float")
Y = tf.placeholder("float")
w = tf.Variable(0.0, name="weight")
b = tf.Variable(0.0, name="bias")
y_pred=X*w-b
#这里的loss要计算所有的batch的loss的平均值
loss = tf.reduce_mean(tf.square(Y - y_pred))
#为了观察输入数据的
lossnumber=tf.square(Y-X*w-b)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
#计算输出相对于输入的梯度,其返回的shape跟X的一样维度
gradient=tf.gradients(y_pred,[X])
# Create session to run
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
epoch = 1
batchx = []
batchy = []
for i in range(100):
#这个会zip会返回这两个数据的一个数据组合
for (x,y)in zip(train_X,train_Y):
#这里相当于batchsize,其会不断变多,也可以每次feed当前(x,y)
if False:
batchx.append(x)
batchy.append(y)
else :
#实际要用一两个训练数据的就够的,因为batchsize不能太大。上面的每次训练数据会不断增大
batchx=x
batchy=y
_,w_value,lossvalue,b_value,lossnumbervalue,gradientvalue=sess.run([train_op, w,loss, b,lossnumber,gradient],feed_dict={X: batchx,Y: batchy})
print("Epoch: {}, w: {}, loss:{} b: {}, gradient:{}, lossnumbervalue:{} ".format(epoch, w_value,lossvalue, b_value,gradientvalue, lossnumbervalue))
epoch += 2
#draw
plt.plot(train_X,train_Y,"+")
plt.plot(train_X,train_X.dot(w_value)+b_value)
plt.show()