1. 节点准备
192.168.137.129 spslave2
192.168.137.130 spmaster
192.168.137.131 spslave12. 修改主机名

3. 配置免密码登录
- 首先到用户主目录(cd ~),ls -a查看文件,其中一个为“.ssh”,该文件价是存放密钥的。待会我们生成的密钥都会放到这个文件夹中。
- 现在执行命令生成密钥:
ssh-keygen -t rsa -P ""(使用rsa加密方式生成密钥)回车后,会提示三次输入信息,我们直接回车即可。 - 进入文件夹cd .ssh (进入文件夹后可以执行ls -a 查看文件)
- 将生成的公钥id_rsa.pub 内容追加到authorized_keys,执行命令:
cat id_rsa.pub >> authorized_keys - 把各个节点的authorized_keys的内容互相拷贝加入到对方的此文件中,然后就可以免密码彼此ssh连入

4. 安装配置JDK
所有节点安装JDK1.7,安装完成后,设置环境变量:
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5. 安装配置scala
所有节点安装scala2.10.6版本:http://www.scala-lang.org/download/2.10.6.html
安装完成后,配置环境变量:
export SCALA_HOME=/usr/scala-2.10.6/
export PATH=$PATH:$SCALA_HOME/bin:$SCALA_HOME/bin6. 安装配置spark
6.1. 下载spark1.6.1
Apache spark官网下载地址: http://spark.apache.org/downloads.html

6.2. 配置spark环境变量
export SPARK_HOME=/usr/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/bin6.3. 配置$SPARK_HOME/conf/slaves
首先将slaves.template拷贝一份,重新命名为slave2,并编译slave2内容:

6.4. 配置$SPARK_HOME/conf/spark-evn.sh
同样将spark-env.sh.template拷贝一份,命名为spark-evn.sh,追加内容:
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera/
export SPARK_MASTER_IP=spmaster
export SPARK_WORKER_MEMORY=1G
export SCALA_HOME=/usr/scala-2.10.6/7. 启动spark
- 方式一
启动master
./sbin/start-master.sh
启动workers
./sbin/start-slave.sh <master-spark-URL>
master-spark-URL: spark://spmaster:7077- 方式一
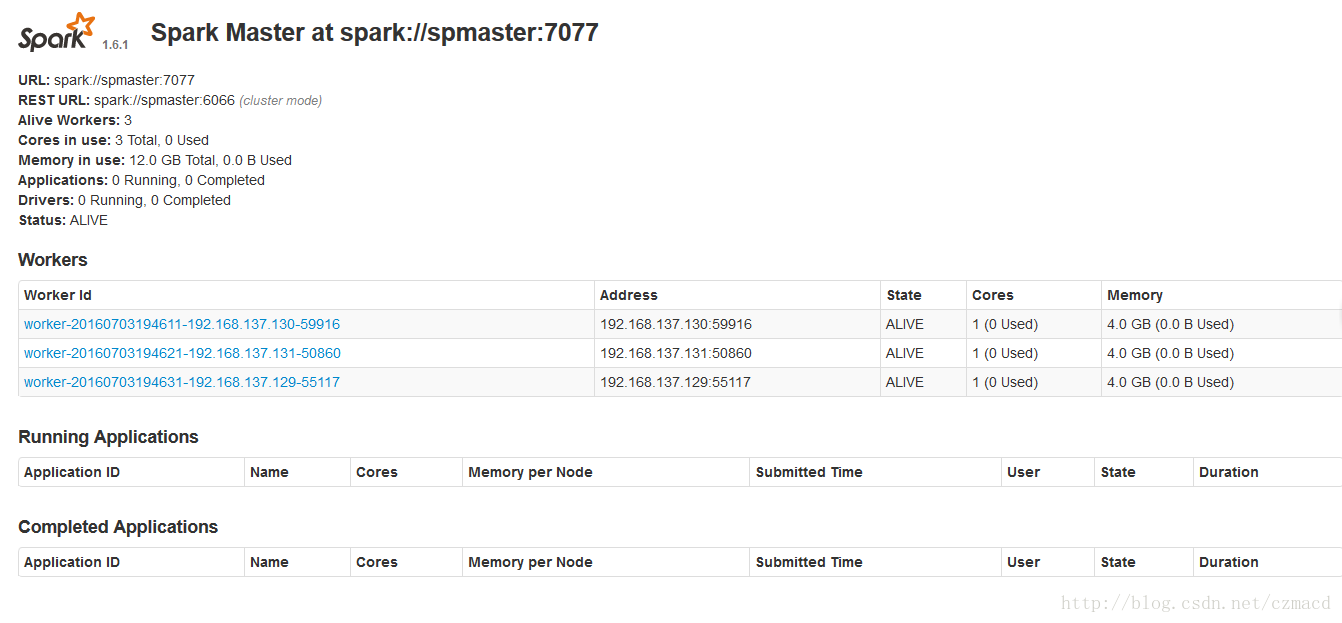
./sbin/start-all.sh 通过浏览器访问:http://spmaster:8080/
参考:
http://spark.apache.org/docs/latest/spark-standalone.html