文章目录
NameNode检查点异常
安装flink之前,观察到一个NameNode检查点异常:
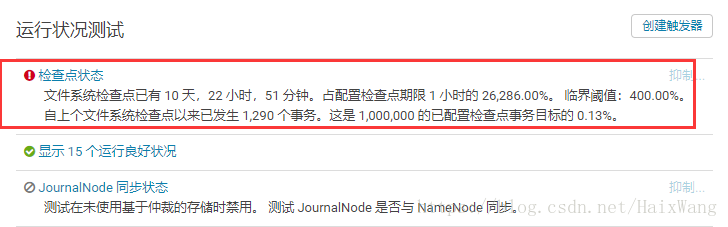
没去找官方解释,按照此文的第4点解决了问题:
namenode的Cluster ID 与 secondnamenode的Cluster ID 不一致,对比/dfs/nn/current/VERSION 和/dfs/snn/current/VERSION中的Cluster ID 来确认,如果不一致改成一致后重启应该可以解决
- 备份/dfs/snn/current/VERSION
- 修改/dfs/snn/current/VERSION中的Cluster ID与/dfs/nn/current/VERSION中的一致
- 重启namenode
- 删除备份
但是随后发现,该方式治标不治本。
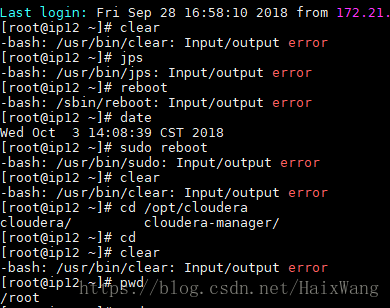
还有一个节点今天发现了Input/output error错误,linux-like相关erros解决中的第二个问题,暂时没有解决,也没有去机房重启(估计重启后问题更多)。
希望有经验的前辈可以指点一二。
Flink1.6.1安装
要求: Java 8.x
【补充:运行Flink程序,使用Flink的话,Hadoop并不是必须的,hadoop版本需要低于等于2.8】
【我这是jdk1.8.0_131+hadoop2.6.0+cdh5.13.2+2687,所以我下载的是】
linux上安装:
- 从下载页面下载二进制文件。
如果您计划将Apache Flink与Apache Hadoop一起使用(在YARN上运行Flink,连接到HDFS,连接到HBase,或使用一些基于Hadoop的文件系统连接器),确保选择与您的Hadoop版本匹配的Flink包。
wget -c http://mirrors.shu.edu.cn/apache/flink/flink-1.6.1/flink-1.6.1-bin-hadoop26-scala_2.11.tgz
- 解压
tar -zxf flink-1.6.1-bin-hadoop26-scala_2.11.tgz
可以看出,进入18年,Flink社区特别活跃:
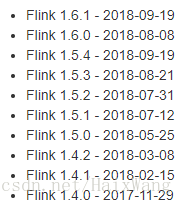
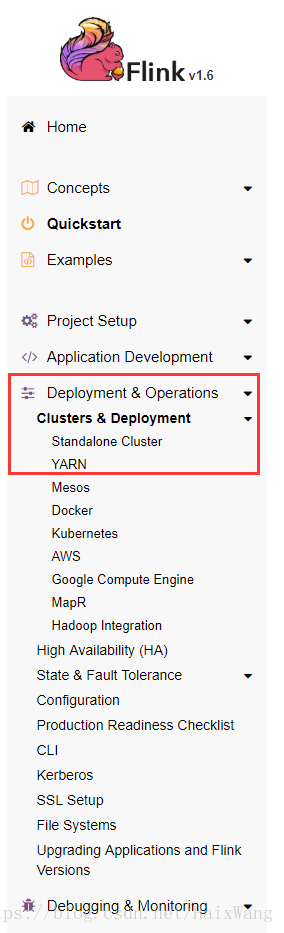
“quickstart” 页面的后续操作不建议执行了,是本地模式,接下来看看集群模式安装。
- standalone cluster
doc地址,因为最近有一两个NodeManager不稳定,所以就先试试standalone cluster。YARN cluster会麻烦一些。
前提
- jdk 1.8+
- 每台机器已经设置JAVA_HOME
- ssh免密登录
配置Flink
配置文件位于conf/下:
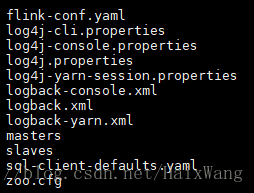
配置master节点
- 选择一个节点作为master节点(JobManager),在conf/flink-conf.yaml中设置jobmanager.rpc.address 配置项为该节点的IP或者主机名。
- 确保所有节点有有一样的jobmanager.rpc.address 配置。
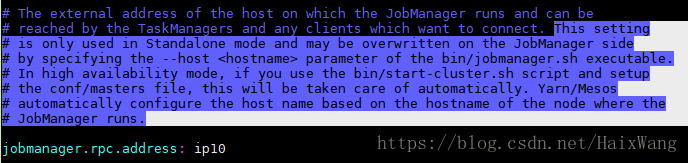
注意!
- 此设置适用于standalone模式
- 该值可能会被JobManager节点的可执行文件bin/jobmanager.sh指定的- -host <hostname>参数覆盖
- 在高可用性模式下,如果你使用bin/start-cluster.sh脚本(来启动),并且在conf/masters文件设置了(多个节点),(那么,使用哪个节点作为Jobmanager)是自动处理的。
JVM内存
- jobmanager.heap.size
- taskmanager.heap.size
(如果是YARN,这两个值自动配置为TaskManager的YARN容器的大小,减去一定的容差值) - 以MB为单位
slaves
- 与HDFS配置类似,编辑文件conf/slaves并输入每个工作节点的IP/主机名。每个工作节点稍后将运行TaskManager。
- master负担重的话,依然可以选择master不作为TaskManager节点(去掉localhost)。
下面是以三个节点为例的配置示意图:

taskmanager.numberOfTaskSlots
- 如果此值大于1,TaskManager可以使用多个CPU内核,单个TaskManager会将获取函数或运算符并行运行。但同时,可用内存是公用的。此值通常与TaskManager的计算机具有的物理CPU核心数成比例(例如,等于核心数,或核心数的一半)。
- 这里,我设置为4
jobstore.cache
- 作业的缓存大小,默认52428800(以字节为单位),也就是50M
- 我这里,机器内存48G,我设置为300M:314527800
- 默认配置文件里面没有,需要自己添加
临时I/O目录
- 内存不够用时,写入到taskmanager.tmp.dirs指定的目录中
- 如果未显式指定参数,Flink会将临时数据写入操作系统的临时目录,例如Linux系统中的/ tmp
暂时先处理这些配置,以后用到了,再补充。
更多的配置信息见配置页面
启动集群
注意!
启动脚本前,还需要配置HADOOP_CONF_DIR
否则:
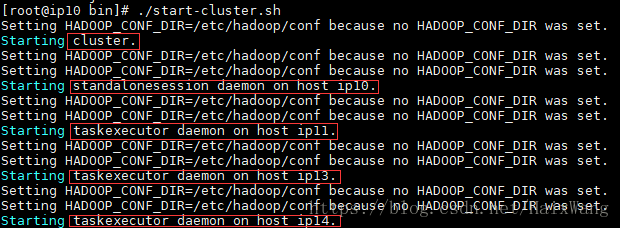
vim /etc/profile
export HADOOP_CONF_DIR=/etc/hadoop/conf
source /etc/profile
bin/start-cluster.sh
- 在master节点上运行该脚本启动JobManager,它会并通过SSH连接到从slaves文件中列出的所有工作节点,以在相应节点上启动TaskManager。
- JobManager进程通过配置好的RPC端口(默认6123)来接收Job的提交的作业。
- 停止Flink:
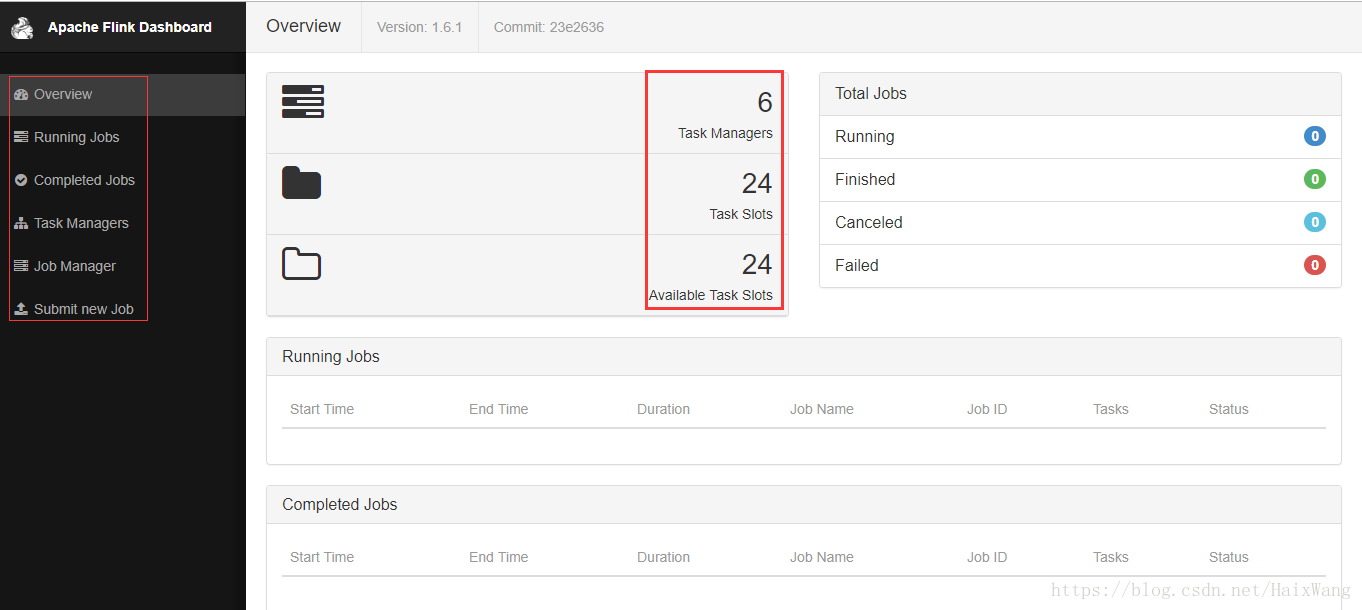
bin/stop-cluster.sh - web dashboard(jobmanager:8081)
目前dashboard看得出来功能不多,但是简洁明了;
但是,这几个数字怎么算的?
将JobManager / TaskManager实例添加到群集
我的理解是,这些脚本的应用场景是:
- JobManager 或者TaskManager(HA)因为某些原因退出了集群,我们需要单独启动
- 单独stop某一节点上的进程
添加JobManager
bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all
添加TaskManager
bin/taskmanager.sh start|start-foreground|stop|stop-all
bin下面的脚本:
Maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.1</version>
</dependency>
下篇文章写两个demo提交到集群进行测试。
参考
[1.] NameNode检查点异常——mllhxn:cdh问题
[2.] standalone cluser setup doc
[3.] 更多配置参数