ZooKeeper
zoo[动物园] keeper[管理员]
动物园里各种各样的动物,类比错综复杂的分布式系统,需要一个管理员来进行治理。
ZooKeeper(简称zk)是一个开源的、用于协调分布式应用程序的服务。它提供了一组 基元(可以理解为一些原子操作),分布式系统可以在其之上构建出更高级的功能,比如数据同步、配置信息维护、分组和命名。ZooKeeper的设计是易于编程的,它在内部使用了一个类似于文件系统目录树结构的数据模型。
一、设计目标
ZooKeeper很简单。它允许分布式应用程序通过一个共享的层次化的命名空间来相互协作,这非常类似一个标准文件系统。这个命名空间由一个个称为 znode 的数据节点组成,可以理解为你电脑文件系统中的目录和文件。不同的是,通常来说文件系统是用来存储和持久化数据的,而ZooKeeper的数据是存储在 内存 中的,这意味着它具备高吞吐量和低延迟。
ZooKeeper的设计实现非常重视高性能、高可用和严格的顺序访问。性能方面它可以被用于大型的分布式系统。可用性方面避免了单点故障。严格的顺序访问机制意味着可以在客户端实现复杂的同步原语。
ZooKeeper是多副本的。和分布式应用程序一样,ZooKeeper通常被部署在多个服务器节点,形成集群。
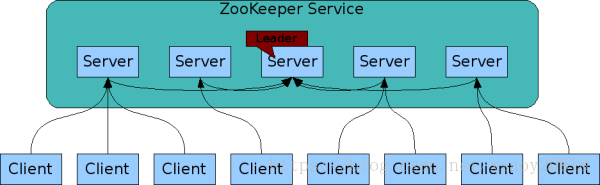
组成ZooKeeper服务的各个Server节点必须能够互相识别和通信。各个节点在内存中保存了一份状态镜像,并且会将事务日志和快照持久化存储。只要超过半数的节点是可用的,ZooKeeper服务就是可用的。
Client会连接到其中一个Server节点,并通过TCP连接来发送请求、获取响应、获取watch事件(ZooKeeper的监听机制)、发送心跳。
如果Client和Server之间的TCP连接断开了,Client将连接到另外一个Server。
ZooKeeper是有序的。ZooKeeper使用一个反映所有事务顺序的数字来标识每一个更新操作。我们可以基于这个顺序实现更高级别的抽象,例如同步原语。
ZooKeeper速度很快。尤其适合在”读多写少”的场景中。经测试,将ZooKeeper部署在上千个节点上运行,读写比率大约为10:1的情况下,性能最佳。
二、数据模型和层次命名空间
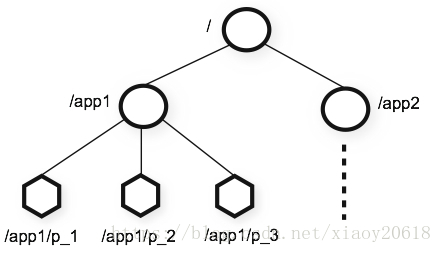
ZooKeeper提供的命名空间非常类似于一个标准的文件系统。ZooKeeper命名空间中的每一个节点由一个路径唯一标识,路径通过斜线”/”分割。
三、节点和临时节点
与标准文件系统不同的是,ZooKeeper命名空间中的每个节点都可以存储数据,并且可以有多个子节点。这就好比存在一个文件系统,允许一个文件也是一个目录。(ZooKeeper主要用来存储相互协作的数据:状态信息、配置、位置信息等等。所以每个节点中存储的数据量通常很小,一般在字节到千字节范围。)这些数据节点,术语上被称为 znode 。
Znode内部维护了一个数据结构,包括数据的版本号、访问控制列表、时间戳,以实现数据验证和同步更新。每次znode的数据更改时,版本号都会增加。每当客户端查询一个节点数据时,也会得到数据的版本号。
每个znode节点的数据都是以原子的方式进行读写的。读取操作可以获取到一个znode节点相关的所有数据字节,写入操作将替换掉所有数据。每个节点都有一个ACL(访问控制列表),以限制谁可以做什么。
ZooKeeper还有一个临时节点的概念。当创建临时节点的session(会话)处于活动状态,这些节点就会一直存在。当会话结束这些节点就会被删除。
四、条件化更新和监听器
ZooKeeper支持监听机制,术语叫做watch。客户端可以在znode上设置一个watch。当znode发生改变时,将触发监听事件,客户端将会收到一个server发送过来的数据包,说明znode发生了变化。
五、ZooKeeper提供哪些保证?
ZooKeeper非常快速而且简单。由于其设计目标是作为构建更加复杂的分布式系统的基础服务。所以它提供了以下保证:
- Sequential Consistency 顺序一致性
客户端发送的更新操作会按照它们的发送顺序被执行。
- Atomicity 原子性
操作要么全部成功,要么全部失败。
- Single System Image 单一系统镜像
无论客户端连接到哪一个ZooKeeper节点,看到的服务视图是一致的(各个节点数据是一致的)。
- Reliability 可靠性
一旦数据发生更新,它就会被持久化直到客户端再次覆盖更新。
- Timeliness 实效性
客户端看到的系统视图需要保证在一定的时间范围内保持最新状态。
六、简易的API
提供简洁易用的编程接口是ZooKeeper的设计目标之一。因此,它仅支持以下这几个操作:
- create
在树的某个位置创建节点 - delete
删除节点 - exists
判断节点是否存在 - get data
读取节点的数据 - set data
写入数据到节点 - get children
获取节点的孩子 - sync
等待节点间数据同步
七、实现机制
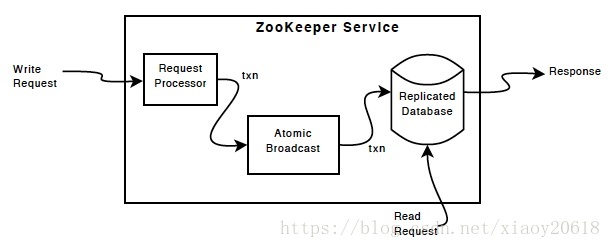
Replicated Database是一个包含完整数据树的内存数据库。所有的更新操作日志会被记录到磁盘,并且这些操作在被应用到内存数据库之前会被序列化到磁盘中。
每一台ZooKeeper服务器都能够向客户端提供服务。客户端连接到指定的服务器然后提交请求。读请求由每台服务器上面的本地数据库副本接受并处理。写请求由一致性协议处理。
作为一致性协议的一部分。来自客户端的所有写请求,会被转发到一台称为 leader 的服务器节点上。其余的ZooKeeper节点,称为 follower,接受leader的消息并达成一致。