微博在构建基于Docker容器的混合云架构时,采用了Consul架构进行集群的节点发现和业务的服务发现,当使用Nginx作为代理的时候,只需要在upstream的配置中声明Consul集群,即可完成后端服务的动态发现。在这样一种服务发现的模式中,Consul处于系统的核心地位,一旦它出现问题就会导致整个集群的失联,由此可见在Consul架构的设计中,分布式高可用性是最基本要求。下面具体阐述Consul的分布式架构与其使用的一致性协议和通信协议:
1 架构
一个Consul的典型架构图如下所示:
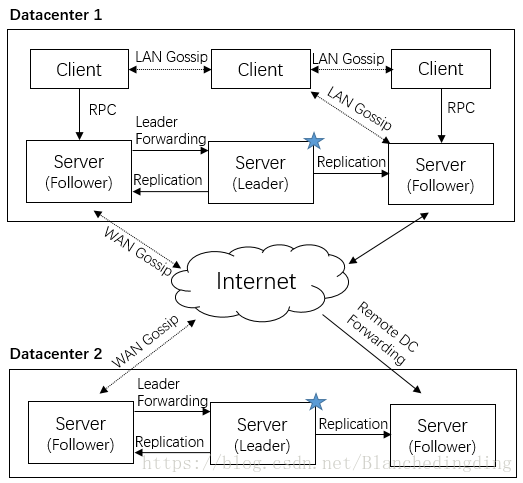
首先介绍一下其中的几个相关概念:
l Agent: Consul集群中每个成员节点上都必须运行的守护进程,有Client和Server两种模式,所有的Agent都可以调用DNS或HTTP API,并负责检查和维护服务同步。
l Client: 指集群中运行Client模式Agent的节点,它将所有的RPC转发到Server。
l Server: 指集群中运行Server模式Agent的节点,参与Raft协议,包括Leader选举、心跳同步等。Server维护集群的状态,响应RPC查询,与其他数据中心通过WAN Gossip交互,将查询转发到Leader或远程数据中心。
l 数据中心(Datacenter): 指在同一个私有的、低延迟、高带宽的网络环境中的一组网络基础设施,官方建议[1]一个Consul的数据中心包含3到5个Server(为了故障处理和性能的平衡)和N多个Client。
Consul允许多数据中心,数据中心之间是低耦合的,但由于故障检测、连接缓存和复用机制,跨数据中心的请求响应通常十分快速和可靠。Consul采用基于Raft算法的一致性协议进行Leader选举和事务管理,采用基于Gossip算法的通信协议进行通信和成员管理。
2 一致性协议(consensus protocol)——Raft算法
在分布式理论中,一致性协议描述了多个进程或实例如何通过一定的原则或规则,对某项内容达成一致的意见,这是一个通信和协商的过程,Consul使用Raft算法来达成这种“共识”。在Consul集群中只有Server节点会参与到Raft算法中,涉及到的两个主要流程就是Leader选举和日志复制(Log Replication):
2.1 Leader选举
Raft节点总是处于Follower、Candidate和Leader三个状态之一,所有的节点最初都是Follower,然后给自己设置一个150ms到300ms之间随机的election timeout时间(每个节点不同),一旦时间到了却没收到别的节点请求成为Leader的消息,它就将自己的状态转换成Candidate,并开启一个新的selection term(本地记录的term值加一),然后向其它节点发送RequestVote(包含新的term值和自己的节点信息),推荐自己为Leader。如果其它节点在这个term里还没有参与过选举,也就是说它自己不是Candidate也没有给别的Candidate投过票,它就把票投给这个Candidate,然后同步本地term值、重新设置自己的election timeout。
如果Candidate在一个selection term里获得了法定数量的投票(假设这个数据中心所有Server数量为N,法定数量至少为(N/2)+1)它就成为了一个Leader。赢得大多数选票意味着每个term期间只能选举一个Leader,如果两个节点同时成为Candidate、发起投票并平票,那么每个节点重置election term再重来一遍,直到一个Candidate获得了法定数量的投票。

Leader会每隔一个心跳时间(heartbeat timeout)发送Append Entries(日志记录条目,后文会详述)给自己的Followers,Followers会对每一条Append Entries进行响应,并再次重置自己的election timeout。整个election term会一直持续到有Follower没有收到heartbeats而成为一个Candidate为止。
2.2 日志复制(Log Replication)
Raft系统的中的主要工作单元就是日志条目(log entry),日志是一种有序的记录,如果所有的成员在记录内容及其顺序上达成一致,我们认为日志是一致的,所以这里的一致性问题就可以被分解为日志复制的问题。
一旦一个Leader被选举出来,我们就需要向系统中的所有节点复制所有的更改,这里就是通过在心跳同步的时候发送Append Entries来实现的:当一个Client向Leader发出增加一个日志条目的要求时,更改会被追加到Leader的日志中,然后Leader在下一个心跳同步时把更改内容发送给Followers,要求它们也将这个新的日志内容追加到日志中。如果法定数量的Followers将日志写入磁盘文件并向Leader发出了确认追加成功的消息,Leader就提交这个日志条目,然后在下一个心跳中通知所有Follower提交更改。
如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问法定数量的Followers,那么Leader只能正常更新它能访问的那些Follower,但不能提交任何更新,而剩下的大多数Follower由于没有了Leader,他们重新选举出一个Leader,然后这个Leader作为代表与外界交互。如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,因为在失联阶段这个老Leader的更新都没有提交,所以可以直接回滚后同步新Leader的日志。
因为Raft这种日志复制的特点,它的性能对网络延迟比较敏感。基于这个原因,每个数据中心选举出一个独立的Leader,并管理不相交的Server节点集。数据被数据中心分区隔离,所以每个Leader只负责其所在数据中心的数据。当收到一个对远程数据中心的请求,这个请求将被转发到正确的Leader。这样的设计提供了低延迟的事务处理和高可用性,而不用牺牲一致性。
2.3 一致性模式
Consul中所有的写操作都通过Raft复制日志,但Consul对读请求提供了3种不同的一致性模式。
l Default
Default模式只有Leader提供读服务,但对于Leader使用租赁机制(Leader leasing),即在一个给定的时间窗口内,Leader的角色不会变动。如果它被从其余节点中隔离开来,一个新的Leader会被选举出来,但同时旧的Leader不会有状态的转换,这意味着在这个时间窗口内会存在两个Leader节点。
由于旧Leader不能提交新的日志,所以这里没有数据不一致的风险。然而,如果旧Leader提供读取数据的服务,其结果可能不是最新的。做这种权衡,是因为读操作是快速的,通常是强一致型的,并且只在极少数很难触发的条件下会读到旧的值。租赁机制的时间窗口也是有限的,到期后Leader如果还处于隔离状态就会下台。
l Consistent
Consistent模式同样也只有Leader提供读服务,但它是没有附加条件的强一致性模式,需要Leader验证法定数量的节点来确定它仍旧是Leader,这样就增加了一轮到所有Server节点的消息往返。这种模式保证了读到的数据总是一致的,但是由于额外的往返增加了时间的延迟。
l Stale
Stale模式下,任何一个Server无论是不是Leader都可以提供读取数据的服务,这意味着读取到的可能是旧数据,但都是Leader一个心跳时间内产生的。这种权衡容许非常快速且具备良好伸缩性的读操作,也允许在没有Leader的情况下(这意味着此时集群不可用),集群仍旧可以响应读请求。
3 通信协议——Gossip协议
在分布式服务框架中,一个最基础的问题就是远程服务是怎么通讯的,Consul使用Gossip协议管理成员关系、广播消息到整个集群。
3.1 通信方式与协调机制
Gossip是一个带冗余的容错算法,且是一个最终一致性算法。因为Gossip不要求节点知道所有其他的节点,因此具有去中心化的特点,节点之间完全对等,不需要任何的中心节点。
l 通信方式
两个节点A与B之间存在三种通信方式:
push: A节点将数据 (key, value, version)推送给B节点,B节点更新A中比自己新的数据。
pull: A仅将数据(key, version)推送给B,B将本地比A新的数据 (key,value,version) 推送给A,A更新本地。
push/pull: 与pull类似,只是多了一步,A再将本地比B新的数据推送给B,B更新本地。
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,push需通信1次,pull需2次,push/pull则需3次,从效果上来讲,push/pull最好,一个周期内可以使两个节点完全一致,收敛速度最快。
l 协调机制
协调机制是讨论在每次两个节点通信时,如何交换数据能达到最快的一致性。协调所面临的最大问题是,因为受限于网络负载,不可能每次都把一个节点上的所有数据发送给另外一个节点,即每个Gossip的消息大小都有上限,在有限的空间上有效率地交换所有的消息是协调要解决的主要问题。Gossip节点的工作方式分为两种,一种是Anti-Entropy,就是以固定的概率传播所有数据,另一种是Rumor-Mongering,仅传播新到达的数据。下面的协调机制主要针对Anti-Entropy,包括了精确协调和整体协调两个层次上的协调。[3]
精确协调希望在每个通信周期内都能准确消除双方的不一致性,具体表现为相互发送对方需要更新的数据,但是因为每个节点都在并发地与多个节点通信,理论上精确协调很难做到。精确协调需要给每个数据项维护version,每次交互时发送所有的(key, value, version)进行比对,从而找出双方不同之处然后进行更新。但因为Gossip消息存在大小限制,因此每次选择发送哪些数据就成了问题。可以随机选择一部分数据,也可以确定性的选择数据。对确定性的选择而言,根据版本有“最老优先”和“最新优先”两种方式,“最老优先”会优先更新版本最老的数据,而“最新更新”正好相反,这样会造成旧数据始终得不到机会更新。
整体协调与精确协调不同之处在于,整体协调不是为每个数据都维护单独的版本号,而是为每个节点上的宿主数据维护统一的version,相当于把所有的宿主数据看作一个整体,当与其他节点进行比较时,只需比对这些宿主数据的最高version,如果最高version相同说明这部分数据全部一致,否则再进行精确协调。
3.2 Consul中的Gossip
Consul中的Gossip协议涉及到两个不同的Gossip Pool——LAN Pool和WAN Pool。
每个Consul数据中心都有一个包含所有Server和Client的LAN pool,设置LAN Pool有如下几个目的:首先,Pool中的成员信息可以让Client自动发现Server节点,减少所需的配置;其次,分布式故障检测的工作可以由整个集群共享,而不是集中在少数几个Server上;最后,Gossip允许可靠和快速的事件广播,比如,Leader选举。
WAN Pool是全局唯一的,无论属于哪一个数据中心,所有Server都要加入WAN Pool。由WAN Pool提供的成员信息让Server可以执行跨数据中心的请求,集成式的故障检测允许Consul优雅地处理整个数据中心或只是远程数据中心单个Server节点的失联。
参考文献
[1] Consul官方文档, https://www.consul.io/docs/internals/index.html[2] The Secret Lives of Data, http://thesecretlivesofdata.com/raft/
[3] Gossip算法. 纯粹的码农. http://blog.csdn.net/chen77716/article/details/6275762. 2011-03-24