用python做网络爬虫时,有时需要登录某些网站。
例如使用requests请求登录豆瓣网的时候需要输入用户密码,可能还需要输入验证码,比较麻烦。
现在在请求豆瓣网链接www.douban.com的时候,使用post加上cookies,可以不用输入账号和密码直接登录。
方法如下:
打开浏览器,打开豆瓣的主页,按下键盘上的F12键(打开浏览器的开发者工具),此时输入账号和密码登录豆瓣网。查看开发者工具中请求登录时的cookies信息,如图:
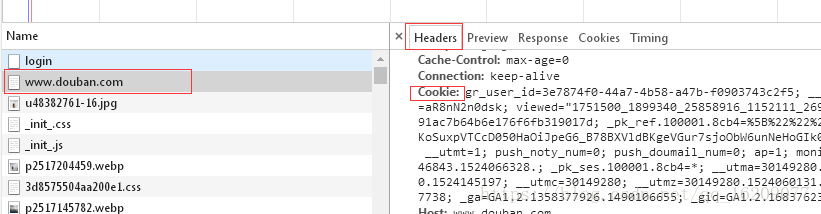
把右侧Cookies对应的内容保存下来。
下面使用python程序登录豆瓣:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'}
cookies = {'cookie': 'xxx'} #xxx是刚才保存的cookies信息,粘贴在这里
url = 'https://www.douban.com'
r = requests.get(url, cookies = cookies, headers = headers)
with open('douban.txt', 'wb+') as f:
f.write(r.content) #把登陆主页后返回的数据保存到文件中查看douban.txt文件,如果文件中”xxx的帐号”, xxx是你豆瓣的账号名,即为登录成功。