RNN的应用场景:
语音识别,音乐生成,语音分析,DNA检测,文本翻译,。。
在接下来介绍RNN的基本结构之前,首先定义一些notation, 表示输入x的第一个单词, 表示第i个输入x的第一个单词, 表示输入x的长度, 表示第i个输出y的第一个单词, 表示输出y的长度。
引出:
用传统的神经网络解决以上场景会存在两个问题:
1.每个样本的输入输出的长度都不同;
2.在其他部分学习到的特征无法分享;(可参考卷积神经网络)
而用RNN的各种不同的结构就可以解决这两个问题。
RNN有不同的基本结构:

| 结构 | 应用场景 | 输入输出 |
|---|---|---|
| One to may | 音乐生成 | 输入为一个整数或者情感词或者为空,输出为一段音乐 |
| Many to One | 情感分析 | 输入为一个句子,输出为情感评分1~5 |
| Many to many(equal) | 文本标注 | 输入为一段文本,输出为每个单词的词性 |
| Many to many(unequal) | 翻译 | 输入为一段文本,输出为另一段文本(结构为编码器+译码器) |
一般激活函数使用tanh,损失函数使用交叉熵损失函数。
语言分析模型一般有两种方式:基于词汇的向量和基于字符的向量。基于字符的向量的好处是不存在未知字符,但缺点是计算成本高,最终生成的序列太长。所以现在最广泛使用的还是基于词汇的向量,当计算机计算量提高之后可能会使用基于字符的向量表示。
模型采样
用已知的文本训练好模型之后,可以用这个模型做采样生成这种风格的其他文本。例如用莎士比亚的诗句去训练一个模型,然后对每个输出进行采样,就能得到随机的莎士比亚风格的诗句。
梯度消失问题及其解决方法
做文本翻译时,有时候下一个的单复数与很早之前的主语有关,而在传统的RNN框架中会存在梯度消失问题,梯度消失不擅于处理长期依赖,因此较早以前的信息很难传递后后面,为了解决这个问题,就产生了一些新的RNN隐藏层结构,例如GRU(gated recurrent unit)和LSTM(long short-term memory)。
当然,RNN中同样也会存在梯度爆炸问题,但这种问题比较容易被发现,如参数出现Nan,这是可以采用梯度修剪clipping来解决。
RNN中主要存在的问题还是梯度消失问题。
GRU
只有两个门,结构更简单。
LSTM
有三个门:输入门(更新门),遗忘门,输出门
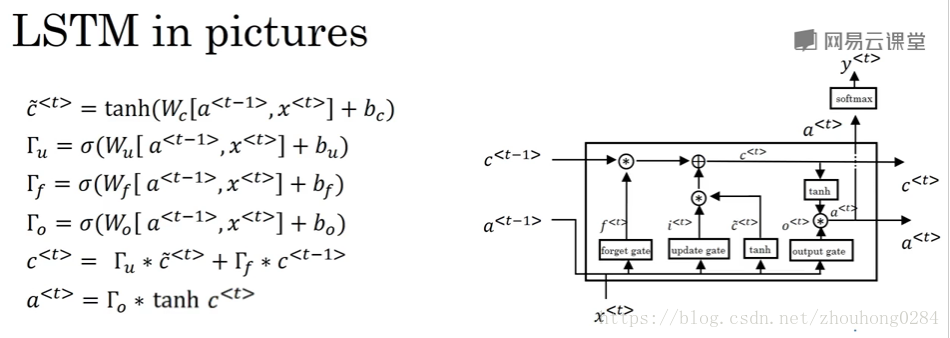
主要了解两点:
1.
表示c的一个候选值,因此最终的细胞状态就是通过更新门和遗忘门来决定是更新原始细胞值为候选值,还是保持原来的值;a是输出,它是更新后的细胞值经过一个tanh函数和输出门来决定的。
这种公式的形式值得借鉴,先写候选细胞值,然后写三个门函数,然后更新细胞值,输出数据。
2.看图片中的最上面那条黑线就能看出,只要控制好更新门和遗忘门,就能把细胞值的记忆保存下来,因此可以建立长期依赖。
双向RNN(Bi-RNN)
存在两个方向的前向传播RNN,这样每一个输出能同时受到前后输入的影响,在文本分类中经常用到这种结构。
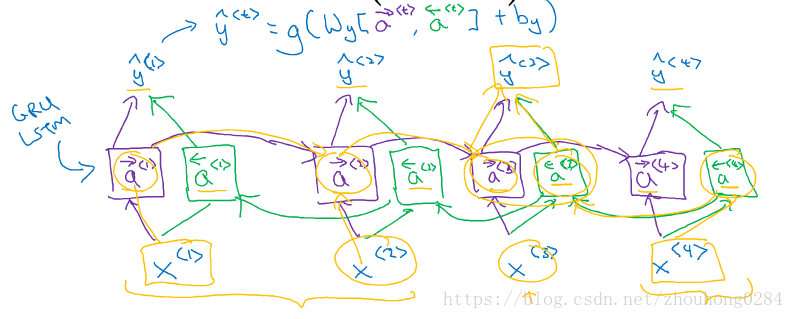
深层RNN网络
一般来说隐藏层不超过3层,每一层都可以用标准RNN、GRU、LSTM和bi-RNN构成。注意在这里每一层就只有一个构建了,因为它在时间上是串行的,相当于用了很多个平行结构。