
分布式的词嵌入(word embedding)将一个词表征成一个连续空间中的向量,并且有效地挖掘了词的语义和句法上的信息,从而被作为输入特征广泛得应用于下游的NLP任务(比如:命名实体识别,文本分类,情感分析,问答系统等等)。CBOW,skip-gram 和Glove模型算是最热的最受青睐的方法来进行词嵌入的学习了。后来人们又在这三个模型的基础上发明了各种变体来提高词嵌入的质量。
今天要介绍的是通过增添中文字形结构的信息来提高中文词嵌入质量的几个最新方法。和传统的CBOW,skip-gram 和Glove模型不同的是,后者只考虑了词的共现性,而前者通过中文词语中字、偏旁部首等信息来增加对词义的表征。
共介绍2017年2篇和2018年2篇文献。
公子,前戏没有,直接主菜。
文献一
题目:“Learning Chinese Word Representations From Glyphs Of Characters”
作者:台湾国立大学, Tzu-Ray Su, Hung-Yi Lee
发表时间:2017年8月
step1:预处理数据
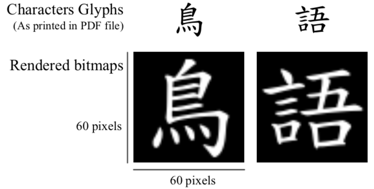
首先将语料中的“字”都表示成一张图片,并且调整到60*60大小,如下:
step2: 提取字符符号特征
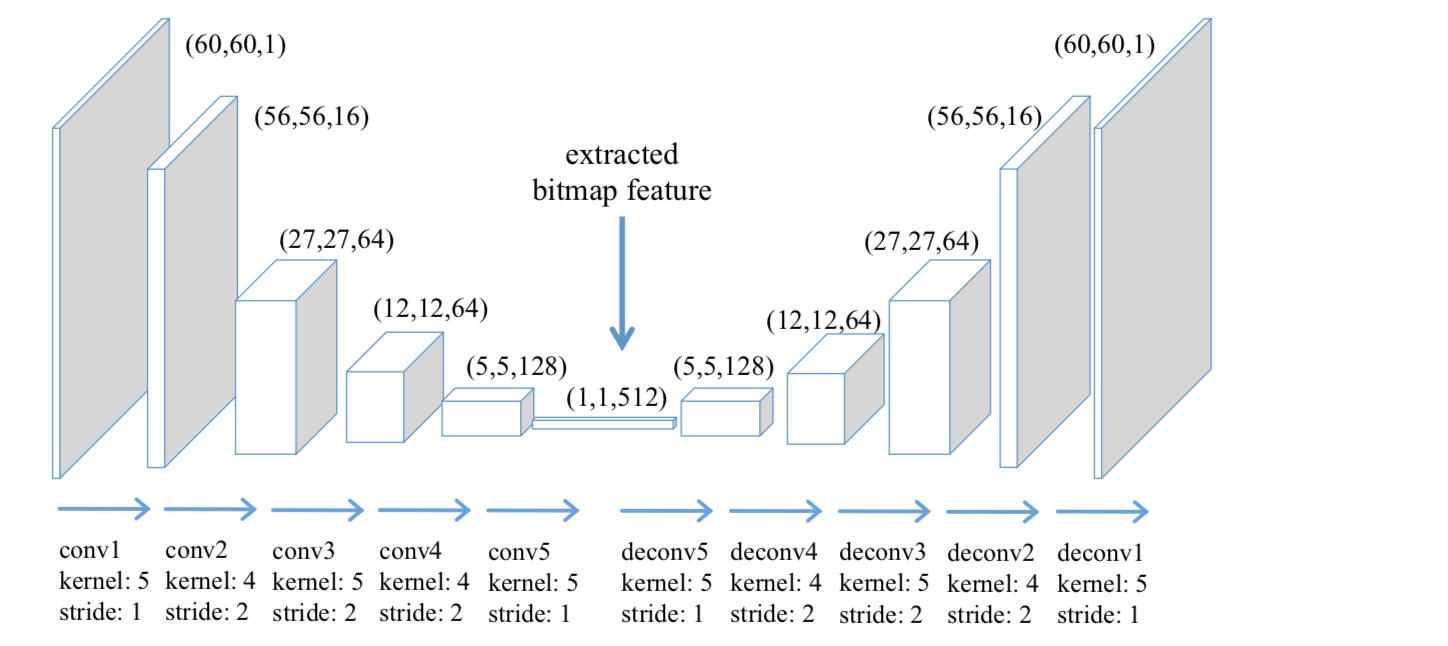
接着,利用convAE模型来,输入字符图片,输出high level的特征。
convAE模型的结构如下图,左右两部分对称,左边encoder是5个卷积层,kenel,stride等信息可在图中已标明,右边decoder也是5卷积,左右两边相同等级的卷积共享kernel。对这个模型,我们输入字符图片,并且在encoder层最后会输出512维的特征,这组特征就是我们想得到的字符符号特征,用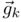 表示。
表示。
step3: 构建模型一
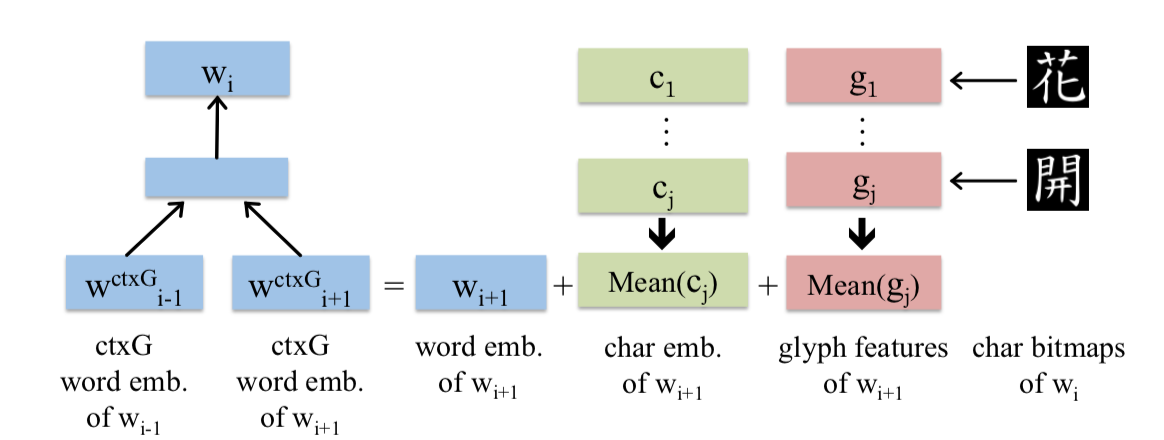
作者在CWE(character-enhanced word embedding)上做了些许手脚,把glyph feature增添到输入层的信息中。
先来看看什么是CWE 模型(如下图):
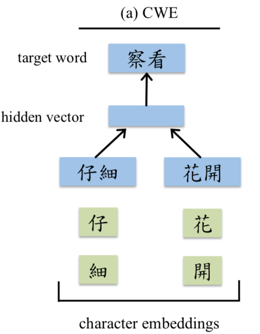
可见除了按照传统的方式输入”词“外,还将词中的每个”字“也作为输入,得到新的词向量为:
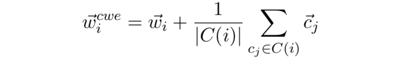
其他部分与CBOW,skip-gram是一样的,只是增添了“字”的信息到词向量中。
本文的作者是在CWE的基础之上又做了两类变更。
增添ctxG:
首先是增加了上下文词的glyph feature信息。
写成公式为:
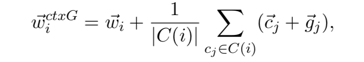
增添targG:
同时,也在CWE的基础上尝试了另一种方法,就是将上下文词的glyph feature信息换成了目标词的glyph feature信息。
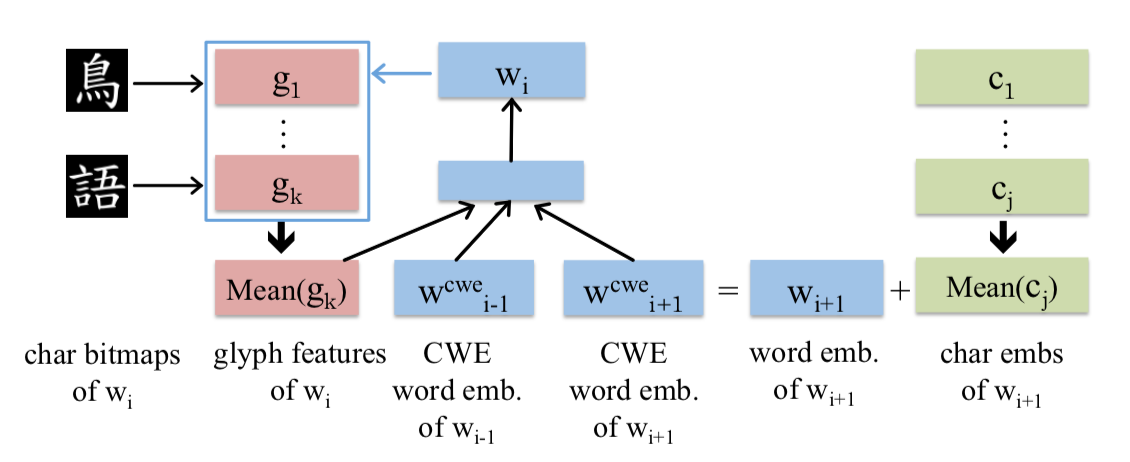
step4: 构建模型二
作者构建的第二类模型,是不使用“词”,“字”的信息,而是有且仅有使用glyph feature。
分别构建了两个模型:RNN+skim和RNN+Glove.
RNN+skim:
如图,输入的是中心词“花”“香”;先进入convAE得到glyph feature:g(花),g(香);再依次输入两层的GRU;GRU的输出经过两层全连接层;最后接上skip-gram。
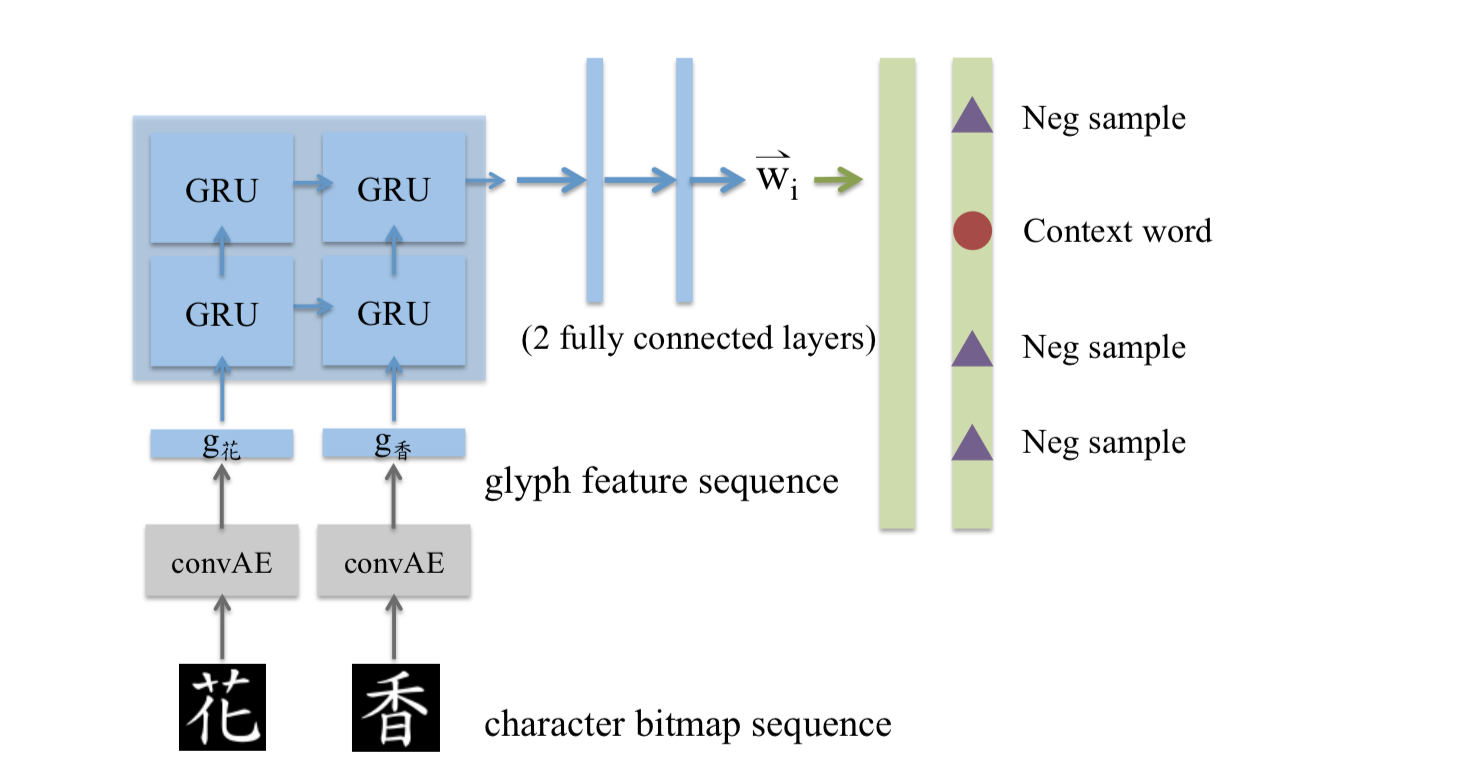
RNN+Glove:
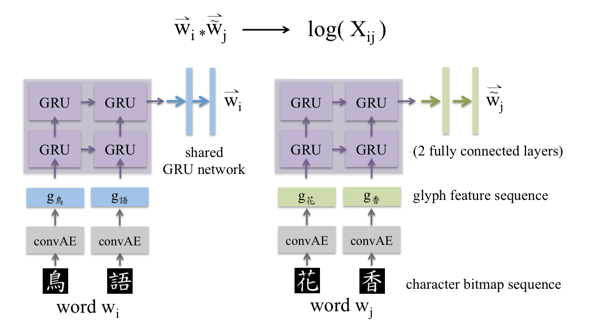
构建两个网络,输入分别是中心词,和上下文词,网络的前面部分与上文的一样,只是输入中心词的网络GRU后面接的是一个共享的GRU网络,输入上下文词的网络GRU输出后接的是一个2层的全连接。然后两个的输出的内积就是log(Xij)的预测。目标函数与Glove模型一样。
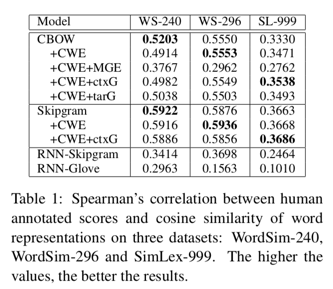
实验结果
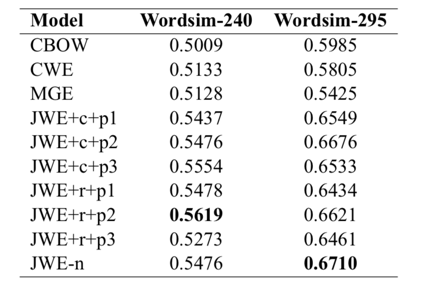
在word similarity上的评估:
在word analogy上的评估:
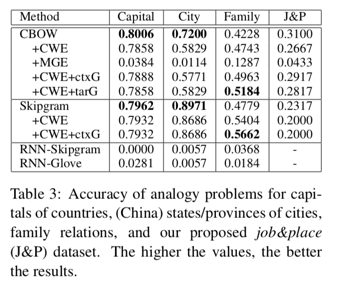
额额额,但是效果好些都不咋地呢。尤其是模型二,抛弃词和字的信息,仅利用glyph feature的信息效果尤其差。但是,不急不急,接下去介绍的文献都会有小小惊喜。
文献二
题目:“Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components”
作者:香港大学, Jinxing Yu Xun Jian Hao Xin Yangqiu Song
发表时间:2017年9月
模型
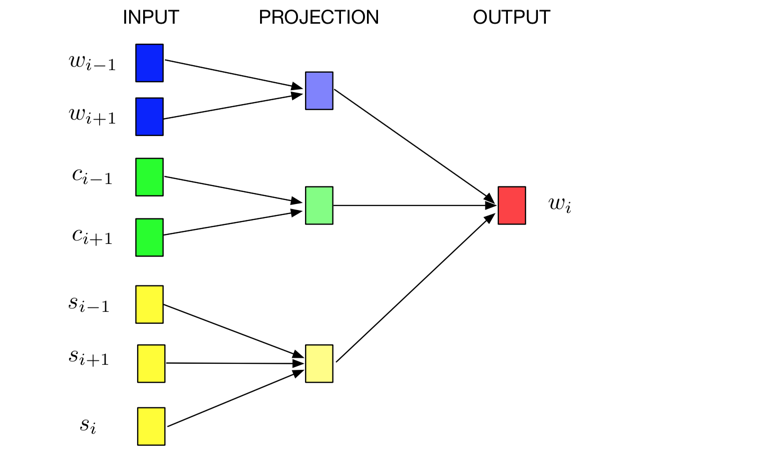
仍然使用CBOM的框架,只是对输入部分做了修改。原来的CBOM输入是上下文”词”w,现在新增“字”c和“偏旁”s的嵌入向量。于是,这个模型可以联合训练出词,字,偏旁的向量表征。
损失函数为三者的相加:
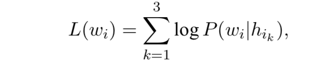
作者尝试了不同的组合来构建模型:
JWE+c+p1:使用上下文词,上下文词中的字,上下文字中的偏旁,预测目标词
JWE+c+p2:使用上下文词,目标词中的字,目标词中的偏旁,预测目标词
JWE+c+p3:使用上下文词,上下文词中的字和偏旁,目标词中的字和偏旁,预测目标词词
JWE+r+p1:使用上下文词,上下文词中的偏旁,预测目标词
JWE+r+p2:使用上下文词,目标词中的偏旁,预测目标词
JWE+r+p3:使用上下文词,上下文词中的偏旁,目标词中的偏旁,预测目标词词
JWE-n:只是用字
实验结果
在word similatity上的评估:
在word analogy上的评估:
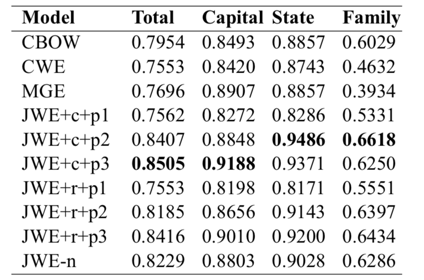
从结果上看,可见比传统的CBOM上,和最近提出的CWE和MGE等模型都表现稍微较优。
文献三
题目:“cw2vec: Learning Chinese Word Embeddings with Stroke n-gram Information”
作者:蚂蚁金服, Shaosheng Cao1,2 and Wei Lu2 and Jun Zhou1 and Xiaolong Li1
发表时间:2018年
这篇来自蚂蚁金服的论文提出一个叫cw2vec的模型,利用中文字的笔画信息来挖掘语义和形态上的信息。
step1:笔画编码
对中文的笔画做一个归类,分成5类,并且1-5编号:

step2:词编码
对词进行笔画上的编码。
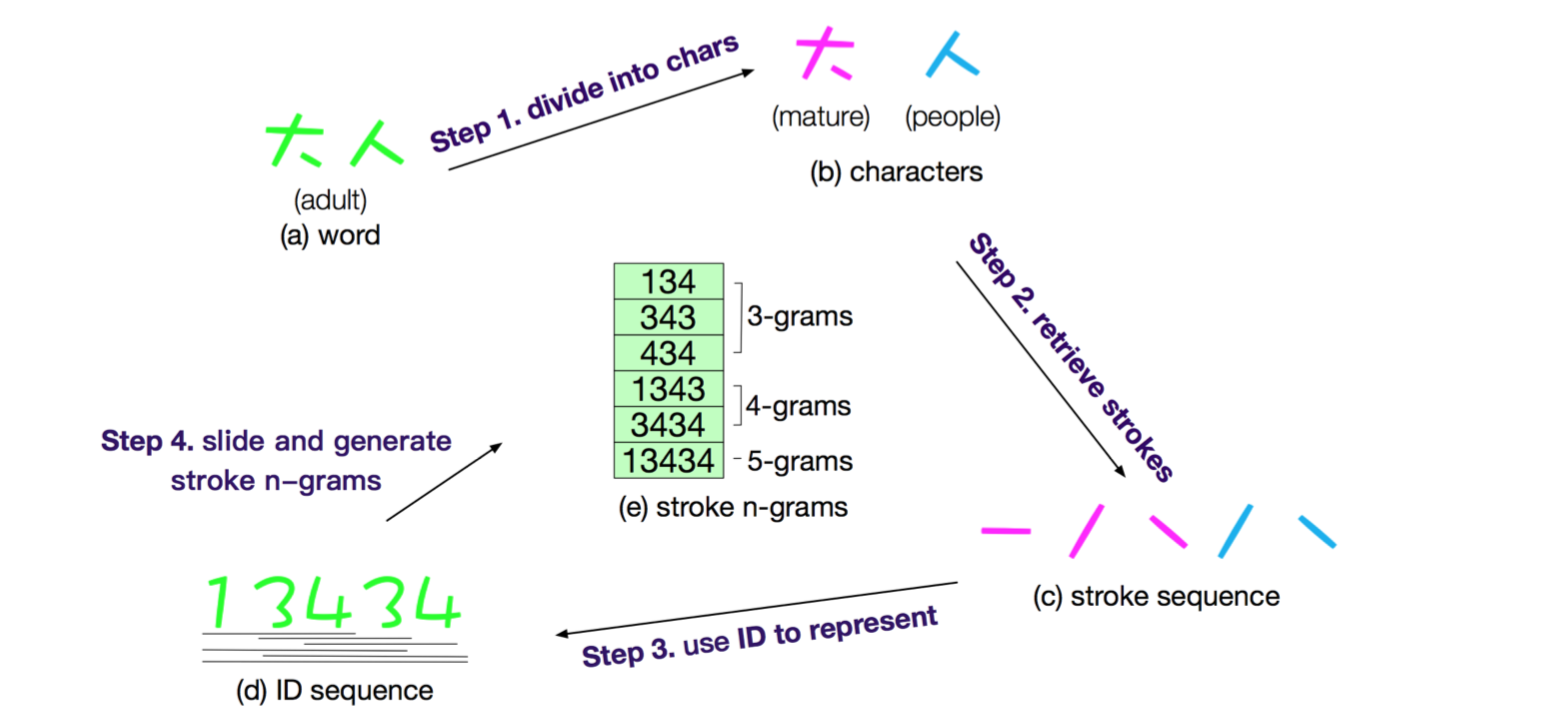
步骤如下:
1)输入词“大人”
2)将词拆分成“大”和“人”
3)将字按照笔画的顺序拆分和排列
4)将笔画去匹配对应的id
5)对词的笔画编码进行n-gram的抽取,形成最终的表征
step3:构建模型
将编码好的词对输入CBOM模型:
目标函数为
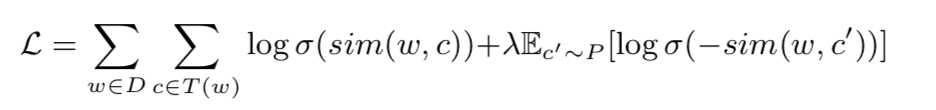
其中
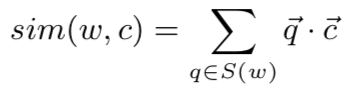
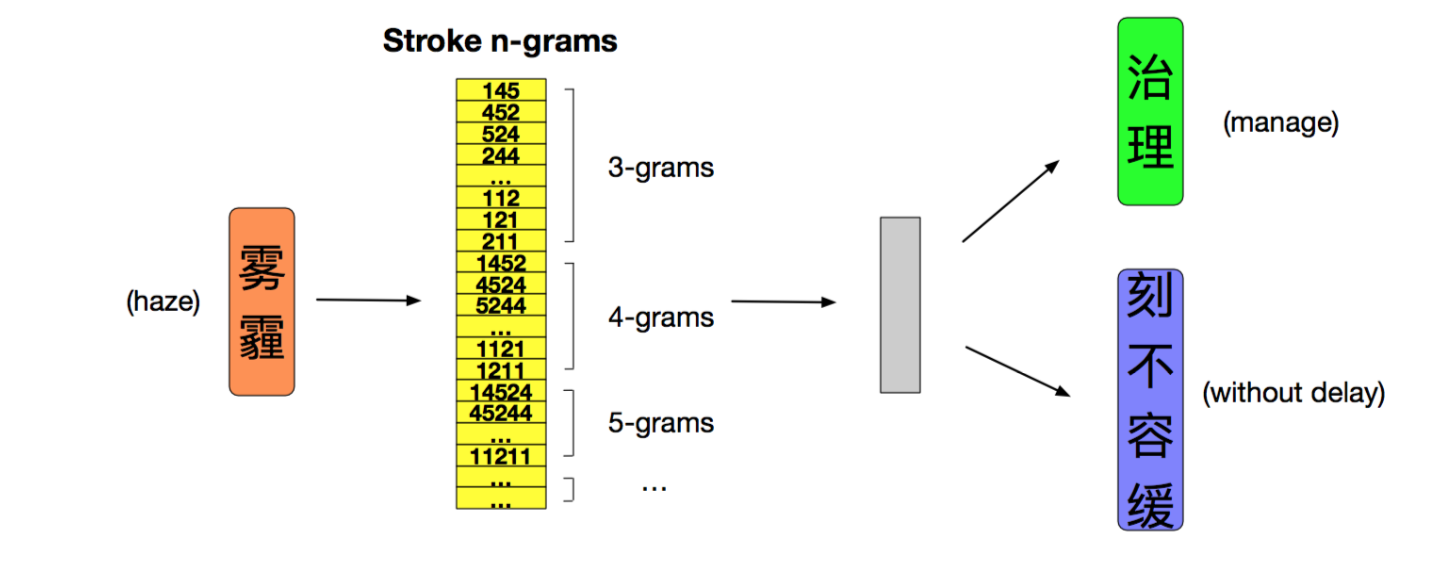
实验结果
文中分别使用了word similarity, word analogy, text classifiction 和named entity recognition来进行比较,前两者是内部评估任务,后两者是外部评估任务。
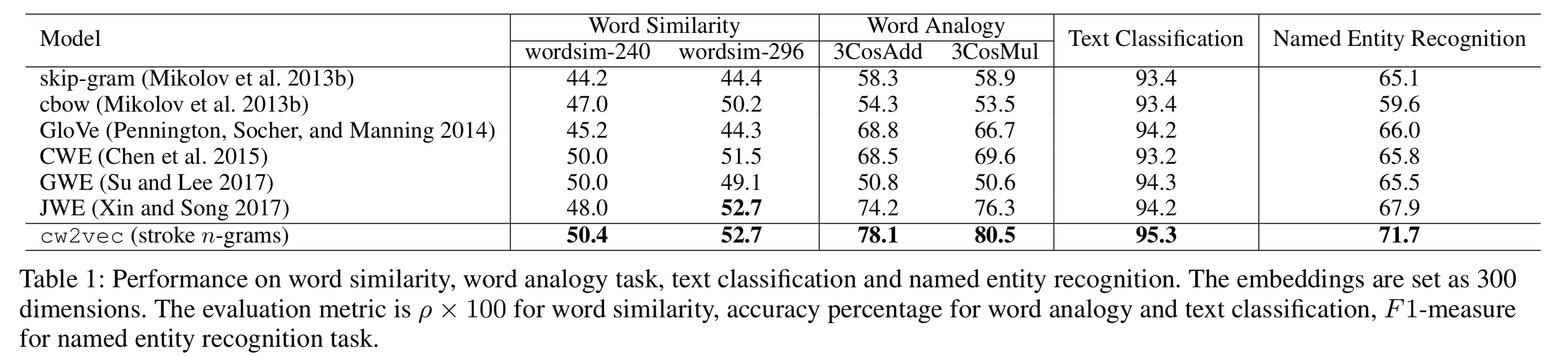
可见,在这4个评估中,本文提出的方法都是最好的哦~~
注意,表中比较的GWE和JWE分别是上文中讲的两篇文献中的模型。
文献四
题目:“Joint Learning Embeddings for Chinese Words and their Components via Ladder Structured Networks”
作者:腾讯, Yan Song, Shuming Shi, Jing Li
发表时间:2018年
模型
腾讯的这篇文章网络结构有一丢丢复杂。先来看一下整体的模型结构。
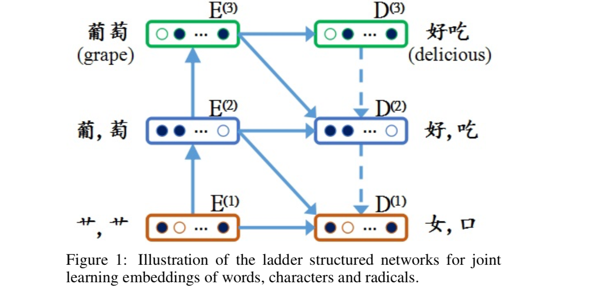
首先看上下有三层,,从下到上分别是表征偏旁,表征字,表征词的向量。
然后再看左右有两部分,左边佳作encoder path,右边叫做decoder path。
先说左边,从下往上先由偏旁预测字,再由字预测词,两个步骤的目标函数为:
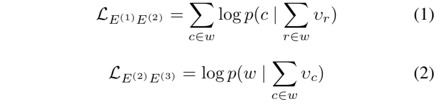
再说右边,虚线的箭头是没有预测步骤的,因为知道词,就肯定已经知道了字和偏旁。
然后说上下三层,在同一层中,左边的指向右边的箭头:
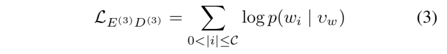
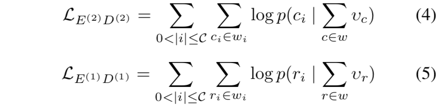
最后说右下指向的箭头:
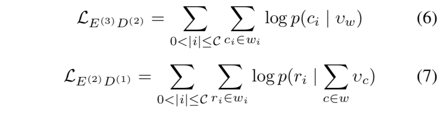
总的目标函数是这7个小步骤的目标函数的相加:
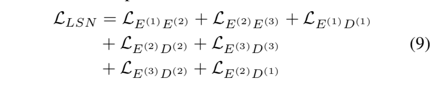
实验结果
Model trained on the PD98 在两个数据集上的word similarity比较:
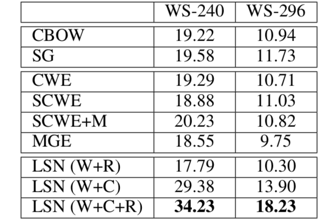
Model trained on the Wiki datasets 在两个数据集上的word similarity比较:
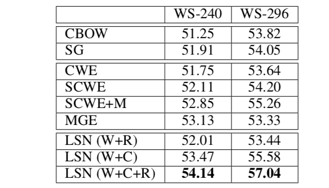
在POS tagging上的比较:

可见,论文提出的模型效果在比较中是最好的。
但注意,比较的模型中,并没有本文上面提到的3篇文献。