序列号
一、什么是序列号?
TCP会对每个字节的数据都进行编号,数据的编号就是数据的序列号,每个字节都有自己独一无二的编号,故序列号具有唯一性
二、序列号的作用?
接收端为了区别重复的报文段(报文段也叫帧),接收端有时会收到很多重复的数据,那么TCP协议就需要能够识别出那些是重复的包,并且把重复的丢弃掉,此时就需要使用序列号,来实现去重
ps:TCP的序列号即表示该报文段从第N个字节开始发送
确认应答(ACK)机制
一、什么是确认应答机制
收到一条报文后,向发送端发送一条确认ACK,此ACK的作用就是告诉发送端:接收端已经成功的收到了消息,并且希望收到下一条报文的序列号是什么
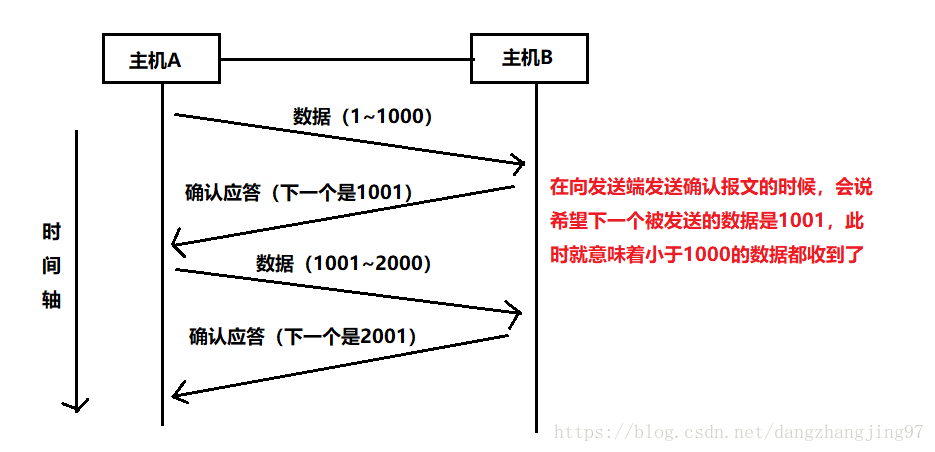
二、为什么需要确认应答机制
在TCP连接成功后,发送的每一条数据都可能会丢失,因此需要确认应答,以保证数据的完整性
三、确认应答的作用
1.来确认接收端收到数据了
2.可以知道收到的是哪一条数据
超时重传机制
一、什么是超时重传机制
TCP每发送一个报文段,就会对这个报文段设置一次计时器,只要计时器设置的
重传时间到,但发送端还没有收到接收端发来的确认,此时就会重传此报文段
超时重传机制是内核实现实现的,因为超时重传机制是TCP的一部分,而TCP
又属于内核,所以超时重传机制也就是内核实现的
二、为什么在超时重传机制中,计时器设置的时间为什么要变得越来越长?
一个报文段可以好几次的超时,就是说呢第一次发此报文段时超时了,发送端
会重新发,第二次发的时候还是超时了,此时发送端还是会重新发送,但是发送端
对一个超时的报文段不会一直发,发几次之后,就会丢弃此报文段
计时器设置的时间在好几次的发送中,为什么要变得越来越长呢?因为在发送
数据的时候,数据传输可能还没建立好,此时就重传,可能会浪费资源
三、超时的时间如何确定?
最理想的情况下,找到一个最小的时间,保证“确认应答一定能在这个时间内
返回”,但是这个时间的长短,会随着网络环境的不同,会有差异,如果超时时间
设置的太长,会影响整体的重传效率,但是如果设置的太短,有可能会频繁的发送
重复的包
TCP为了保证无论在任何环境下都能比较高性能的通信,会动态的计算这个
最大超时时间,所以超时时间不是确定的,是TCP动态的计算的 在Linux(Windows)中,超时以500ms为一个单位进行控制,每次判定超时
重发的超时时间都是500ms的整数倍
如果重发一次之后,仍然得不到应答,等待2*500ms后再进行重传,如果还是
得不到发送端的确认应答,此时就会等待4*500ms进行重传,依次类推,以指数形
式递增,累计到一定的重传次数,TCP会认为网络或者对端的主机出现异常,强制
关闭连接
延迟应答
一、什么是延迟应答?
数据传输的时候,发送端给接收端发送数据,接收端给发送端发去确认应答信息,这样比较耗时,效率低下,延迟应答就是接收端收到数据之后,稍微等一会再应答,这样可以提高数据的传输效率,因为发送端发好几次数据,接收端只需要一次来确认应答,这样可以降低网络拥塞的概率
二、所有的包都可以延迟应答吗?
不是
数量限制:每隔N个包就必须应答一次
时间限制:超过最大延迟时间就必须应答一次
ps:具体的延迟应答数量和超时时间,依操作系统不同也有差异,一般N取2,超时时间取200ms
捎带应答
什么是捎带应答?
虽然有延迟应答,但是客户端和服务器在应用层还是还是”一发一收”,此时就会导致数据传输效率低下,捎带应答就是接收端在给发送端发送数据的时候,捎带着向发送端发去确认应答,应答的内容是接收端已经收到发送端发送的数据
使用捎带应答之前:
客户端:你好吗?
服务器:我收到你发的消息了(接收端的ACK应答)
服务器:我很好
使用捎带应答时:
客户端:你好吗?
服务器:我很好(接收端给发送端发送的数据),我也收到你发的消息了(接收端的ACK应答)
使用捎带应答后,ACK就可以搭顺风车了,在接收端给发送端发送数据的时候,ACK就可以捎带着给发送端发送过去