一.通用概念
通配符
在bash下,可以使用*来匹配零个或多个字符,而用?匹配一个字符。

输入输出从定向
输入重定向用于改变命令的输入,输出重定向用于改变命令的输出。输出重定向更为常用,它经常用于将命令的结果输入到文件中,而不是屏幕上。输入重定向的命令是<,输出重定向的命令是>,另外还有错误重定向2>,以及追加重定向>>,稍后会详细介绍。
作业控制
当运行一个进程时,你可以使它暂停(按Ctrl+z),然后使用fg命令恢复它,利用bg命令使他到后台运行,你也可以使它终止(按Ctrl+c)。
链接
硬链接:只能对文件使用
语法:ln [待建立链接的文件名] [链接的文件名]
eg: ln hello.py a.py
建立链接后,a.py中的内容和hello.py的内容相同,并且删除a.py后不会对hello.py的内容产生影响
软连接(符号链接):可以对文件和目录使用
语法:ln -s [待建立链接的文件名] [链接的文件名]
eg:ln -s a.ch b.ch
建立链接后,a.ch中的内容和b.ch中的内容相同,但是删除a.ch后,b.ch变成无效文件
PS:删除软连接后,不会真的删除一个目录,只是删除了一个符号。
变量
环境变量PATH,这个环境变量就是shell预设的一个变量,通常shell预设的变量都是大写的。变量,说简单点就是使用一个较简单的字符串来替代某些具有特殊意义的设定以及数据。就拿PATH来讲,这个PATH就代替了所有常用命令的绝对路径的设定。因为有了PATH这个变量,所以我们运行某个命令时不再去输入全局路径,直接敲命令名即可。你可以使用echo命令显示变量的值。

除了PATH, HOME, LOGNAME外,系统预设的环境变量还有哪些呢?

使用env命令即可全部列出系统预设的全部系统变量了。不过登录的用户不一样这些环境变量的值也不一样。当前显示的就是root这个账户的环境变量了。下面笔者简单介绍一下常见的环境变量:
PATH 决定了shell将到哪些目录中寻找命令或程序
HOME 当前用户主目录
HISTSIZE 历史记录数
LOGNAME 当前用户的登录名
HOSTNAME 指主机的名称
SHELL 前用户Shell类型
LANG 语言相关的环境变量,多语言可以修改此环境变量
MAIL 当前用户的邮件存放目录
PWD 当前目录
历史记录
敲过的命令,linux是会有记录的,预设可以记录1000条历史命令。这些命令保存在用户的家目录中的.bash_history文件中。有一点需要你知道的是,只有当用户正常退出当前shell时,在当前shell中运行的命令才会保存至.bash_history文件中。
与命令历史有关的有一个有意思的字符那就是”!”了。常用的有这么几个应用:
(1)!! (连续两个”!”),表示执行上一条指令;
(2)!n(这里的n是数字),表示执行命令历史中第n条指令,例如”!100”表示执行命令历史中第100个命令;
(3)!字符串(字符串大于等于1),例如!ta,表示执行命令历史中最近一次以ta为开头的指令。

二.常用命令
参考:命令字典
awk命令:
语法:
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)
常用命令选项:
-F fsfs 指定输入分隔符,fs可以时字符串或正则表达式
-v var=value赋值一个用户定义变量,将外部变量传递给awk
-f scriptfile从脚本文件中读取awk命令
awk脚本
模式可以是以下任意一种:
正则表达式:使用通配符的扩展集
关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试
模式匹配表达式:用运算符
~(匹配)和~!不匹配BEGIN 语句块, pattern语句块, END语句块
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大刮号内,主要部分是:变量或数组赋值、输出命令、内置函数、控制流语句。
awk执行过程分析
第一步: 执行BEGIN { commands } pattern 语句块中的语句
BEGIN语句块:在awk开始从输入输出流中读取行之前执行,在BEGIN语句块中执行如变量初始化,打印输出表头等操作。
第二步:从文件或标准输入中读取一行,然后执行pattern{ commands }语句块。它逐行扫描文件,从第一行到最后一行重复这个过程,直到全部文件都被读取完毕。
pattern语句块:pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行。
{ }类似一个循环体,会对文件中的每一行进行迭代,通常将变量初始化语句放在BEGIN语句块中,将打印结果等语句放在END语句块中。
第三步:当读至输入流末尾时,执行END { command }语句块
END语句块:在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
AWK内置变量
-
$n : 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
-
$0 : 这个变量包含执行过程中当前行的文本内容。
-
ARGC : 命令行参数的数目。
-
ARGIND : 命令行中当前文件的位置(从0开始算)。
-
ARGV : 包含命令行参数的数组。
-
CONVFMT : 数字转换格式(默认值为%.6g)。
-
ENVIRON : 环境变量关联数组。
-
ERRNO : 最后一个系统错误的描述。
-
FIELDWIDTHS : 字段宽度列表(用空格键分隔)。
-
FILENAME : 当前输入文件的名。
-
NR : 表示记录数,在执行过程中对应于当前的行号
-
FNR : 同NR :,但相对于当前文件。
-
FS : 字段分隔符(默认是任何空格)。
-
IGNORECASE : 如果为真,则进行忽略大小写的匹配。
-
NF : 表示字段数,在执行过程中对应于当前的字段数。
print $NF答应一行中最后一个字段 -
OFMT : 数字的输出格式(默认值是%.6g)。
-
OFS : 输出字段分隔符(默认值是一个空格)。
-
ORS : 输出记录分隔符(默认值是一个换行符)。
-
RS : 记录分隔符(默认是一个换行符)。
-
RSTART : 由match函数所匹配的字符串的第一个位置。
-
RLENGTH : 由match函数所匹配的字符串的长度。
-
SUBSEP : 数组下标分隔符(默认值是34)。
基本使用
log.txt文本内容如下:
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo用法一:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号实例:
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
# 格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo用法二:
awk -F #-F相当于内置变量FS, 指定分割字符实例:
# 使用","分割
$ awk -F, '{print $1,$2}' log.txt
---------------------------------------------
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# 或者使用内建变量
$ awk 'BEGIN{FS=","} {print $1,$2}' log.txt
---------------------------------------------
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割
$ awk -F '[ ,]' '{print $1,$2,$5}' log.txt
---------------------------------------------
2 this test
3 Are awk
This's a
10 There apple用法三:
awk -v # 设置变量实例:
$ awk -va=1 '{print $1,$1+a}' log.txt
---------------------------------------------
2 3
3 4
This's 1
10 11
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
---------------------------------------------
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10s用法四:
awk -f {awk脚本} {文件名}实例:
$ awk -f cal.awk log.txtVIM
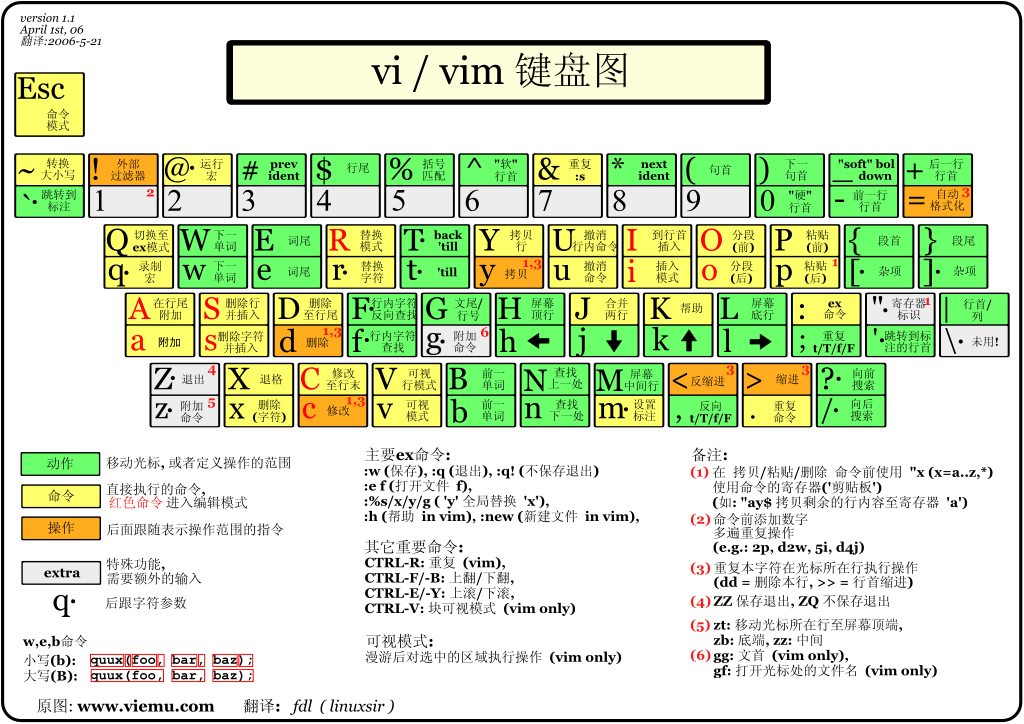
命令模式
此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
以下是常用的几个命令
- i 切换到输入模式,以输入字符。
- x 删除当前光标所在处的字符。
- : 切换到底线命令模式,以在最底一行输入命令。
输入模式
在命令模式下按下i就进入了输入模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合,输入字符
- ENTER,回车键,换行
- BACK SPACE,退格键,删除光标前一个字符
- DEL,删除键,删除光标后一个字符
- 方向键,在文本中移动光标
- HOME/END,移动光标到行首/行尾
- Page Up/Page Down,上/下翻页
- Insert,切换光标为输入/替换模式,光标将变成竖线/下划线
- ESC,退出输入模式,切换到命令模式
底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
- q 退出程序
- w 保存文件
按ESC键可随时退出底线命令模式。
运算符
-
算术运算:(+,-,*,/,&,!,……,++,--)
所有用作算术运算符进行操作时,操作数自动转为数值,所有非数值都变为0
-
赋值运算:(=, +=, -=,*=,/=,%=,……=,**=)
-
逻辑运算符: (||, &&)
-
关系运算符:(<, <=, >,>=,!=, ==)
-
正则运算符:(~,~!)(匹配正则表达式,与不匹配正则表达式)
awk 'BEGIN{a="100testa";if(a ~ /^100*/){print "ok";}}'
ok
过滤第一列大于2的行
$ awk '$1>2' log.txt #命令
#输出
3 Are you like awk
This's a test
10 There are orange,apple,mongo过滤第一列等于2的行
$ awk '$1==2 {print $1,$3}' log.txt #命令
#输出
2 is过滤第一列大于2并且第二列等于'Are'的行
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令
#输出
3 Are you将外部变量值传递给awk
借助 -v 选项,可以将来自外部值(非stdin)传递给awk
VAR=10000
echo | awk -v VARIABLE=$VAR '{ print VARIABLE }'
定义内部变量接收外部变量
var1="aaa"
var2="bbb"
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2
当输入来自文件时
awk '{ print v1,v2 }' v1=$var1 v2=$var2 filename
文件操作
-
打开文件
open("filename") -
关闭文件
close("filename") -
输出到文件 重定向到文件,如
echo | awk '{printf("hello word!n") > "datafile"}'
循环结构
for循环
for(变量 in 数组)
{语句}
for(变量;条件;表达式)
{语句} do...while循环
do
{语句} while(条件) 其他相关语句
-
break:退出程序循环 -
continue: 进入下一次循环 -
next:读取下一个输入行 -
exit:退出主输入循环,进入END,若没有END或END中有exit语句,则退出脚本。
MAN
强大的help工具
1是普通的命令
2是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文件)
3是库函数,如printf,fread
4是特殊文件,也就是/dev下的各种设备文件
5是指文件的格式,比如passwd,就会说明这个文件中各个字段的含义
6是给游戏留的,由各个游戏自己定义
7是附件还有一些变量,比如向environ这种全局变量在这里就有说明
8是系统管理用的命令,这些命令只能由root使用,如ifconfig
------------------------------------
n新文档,可能要移到更适合的领域。
o老文档,可能会在一段期限内保留。
l本地文档,与本特定系统有关的。
在shell中输入man+数字+命令/函数即可以查到相关的命令和函数。若不加数字,那Linux man命令默认从数字较小的手册中寻找相关命令和函数。
例 如:我们输入man ls,它会在最左上角显示“LS(1)”,在这里,“LS”表示手册名称,而“(1)”表示该手册位于第一节章,同样,我们输入“man ifconfig”它会在最左上角显示“IFCONFIG(8)”。也可以这样输入命令:“man [章节号]手册名称”。
man -f command显示man程序的所有手册
例如:man -f kill
man n command显示指定章节的手册
man -a command显示所有章节的手册
man -w command显示手册所在的路径
man -aw command结合-a参数显示所有章节的手册路径
- 向下键向下移一行
- 向上键向上移一行
- 空白键向下翻一页
- /string 向下找string这个字符串,比如,想搜索copy,就输入它
- ?string 向上找string这个字符串
- 配合n(向下查询)、N(向上查询)
- [Page Down] 向下翻一页
- [Page Up] 向上翻一页
- [Home] 到第一页
- [End] 到最后一页
- Q 结束
在使用时可以先 通过man -f <命令>查看所有手册 再通过man <数字> <命令>去看特定的手册内容
chmod
chmod命令用来变更文件或目录的权限
如果使用命令操作:
-
u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。
-
+ 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
-
r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
如果使用数字操作:
chmod abc <file>
其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。
r=4,w=2,x=1
-
若要rwx属性则4+2+1=7;
-
若要rw-属性则4+2=6;
-
若要r-x属性则4+1=5。
实例
将文件 file1.txt 设为所有人皆可读取 :
chmod ugo+r file1.txt
将文件 file1.txt 设为所有人皆可读取 :
chmod a+r file1.txt
将文件 file1.txt 与 file2.txt 设为该文件拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 :
chmod ug+w,o-w file1.txt file2.txt
将 ex1.py 设定为只有该文件拥有者可以执行 :
chmod u+x ex1.py
将目前目录下的所有文件与子目录皆设为任何人可读取 :
chmod -R a+r *
此外chmod也可以用数字来表示权限如 :
chmod 777 file
查找文件方法的区别
which 查看可执行文件的位置,通过PATH环境变量查找到可执行程序的位置
whereis 查看文件的位置,查找速度很快,将其相关文件全部查出来
find 可根据条件查找,实际搜寻硬盘查询文件名称,在硬盘上遍历查找,较小号硬盘资源,效率也较低
locate 配合数据库查看文件位置。
三.常用符号
1) ;
分号。平时我们都是在一行中敲一个命令,然后回车就运行了,那么想在一行中运行两个或两个以上的命令如何呢?则需要在命令之间加一个”;”了。

2) ~
用户的家目录,如果是root则是 /root ,普通用户则是 /home/username

3) &
如果想把一条命令放到后台执行的话,则需要加上这个符号。通常用于命令运行时间非常长的情况。

使用jobs可以查看当前shell中后台执行的任务。用fg可以调到前台执行。这里的sleep命令就是休眠的意思,后面跟数字,单位为秒,常用语循环的shell脚本中。

此时你按一下CTRL +z 使之暂停,然后再输入bg可以再次进入后台执行。

如果是多任务情况下,想要把任务调到前台执行的话,fg后面跟任务号,任务号可以使用jobs命令得到。

4) >, >>, 2>, 2>>
前面提到过的重定向符号> 以及>> 分别表示取代和追加的意思,然后还有两个符号就是这里的2>和 2>> 分别表示错误重定向和错误追加重定向,当我们运行一个命令报错时,报错信息会输出到当前的屏幕,如果想重定向到一个文本里,则要用2>或者2>>。

5) [ ]
中括号,中间为字符组合,代表中间字符中的任意一个

6) && 与 ||
在上面的分号,用于多条命令间的分隔符。另外还有两个可以用于多条命令中间的特殊符号,那就是“&&”和”||”。下面笔者把这几种情况全列出:
1) command1 ; command2
2) command1 && command2
3) command1 || command2
使用”;”时,不管command1是否执行成功都会执行command2;使用”&&”时,只有command1执行成功后,command2才会执行,否则command2不执行;使用”||”时,command1执行成功后command2 不执行,否则去执行command2,总之command1和command2总有一条命令会执行。

四.常用命令集合
调试方法
top 打开TUP

- 第1行:Top 任务队列信息(系统运行状态及平均负载),与uptime命令结果相同。
- 第1段:系统当前时间,例如:16:07:37
- 第2段:系统运行时间,未重启的时间,时间越长系统越稳定。
- 格式:up xx days, HH:MM
- 例如:241 days, 20:11, 表示连续运行了241天20小时11分钟
- 第3段:当前登录用户数,例如:1 user,表示当前只有1个用户登录
- 第4段:系统负载,即任务队列的平均长度,3个数值分别统计最近1,5,15分钟的系统平均负载
- 系统平均负载:单核CPU情况下,0.00 表示没有任何负荷,1.00表示刚好满负荷,超过1侧表示超负荷,理想值是0.7;
- 多核CPU负载:CPU核数 * 理想值0.7 = 理想负荷,例如:4核CPU负载不超过2.8何表示没有出现高负载。
- 第2行:Tasks 进程相关信息
- 第1段:进程总数,例如:Tasks: 231 total, 表示总共运行231个进程
- 第2段:正在运行的进程数,例如:1 running,
- 第3段:睡眠的进程数,例如:230 sleeping,
- 第4段:停止的进程数,例如:0 stopped,
- 第5段:僵尸进程数,例如:0 zombie
- 第3行:Cpus CPU相关信息,如果是多核CPU,按数字1可显示各核CPU信息,此时1行将转为Cpu核数行,数字1可以来回切换。
- 第1段:
us用户空间占用CPU百分比,例如:Cpu(s): 12.7%us, - 第2段:
sy内核空间占用CPU百分比,例如:8.4%sy, - 第3段:
ni用户进程空间内改变过优先级的进程占用CPU百分比,例如:0.0%ni, - 第4段:
id空闲CPU百分比,例如:77.1%id, -
p.s. Linux机器load升高
1. 有可能是cpu过高导致的。可以查看程序中是否有循环过多的代码;查看是否有使用while(true){...}来实现锁;查看代码是否出现死锁
2. 内存占用高。有可能在代码中大量使用强引用类型导致对象不能及时释放;线程池使用缓存线程池时,线程池并没有及时释放
- 第5段:
wa等待输入输出的CPU时间百分比,例如:0.0%wa, - 第6段:
hiCPU服务于硬件中断所耗费的时间总额,例如:0.0%hi, - 第7段:
siCPU服务软中断所耗费的时间总额,例如:1.8%si, - 第8段:
stSteal time 虚拟机被hypervisor偷去的CPU时间(如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)
- 第1段:
- 第4行:Mem 内存相关信息(Mem: 12196436k total, 12056552k used, 139884k free, 64564k buffers)
- 第1段:物理内存总量,例如:Mem: 12196436k total,
- 第2段:使用的物理内存总量,例如:12056552k used,
- 第3段:空闲内存总量,例如:Mem: 139884k free,
- 第4段:用作内核缓存的内存量,例如:64564k buffers
- 第5行:Swap 交换分区相关信息(Swap: 2097144k total, 151016k used, 1946128k free, 3120236k cached)
- 第1段:交换区总量,例如:Swap: 2097144k total,
- 第2段:使用的交换区总量,例如:151016k used,
- 第3段:空闲交换区总量,例如:1946128k free,
- 第4段:缓冲的交换区总量,3120236k cached
进程信息:
在top命令中按f按可以查看显示的列信息,按对应字母来开启/关闭列,大写字母表示开启,小写字母表示关闭。带*号的是默认列。
- A:
PID= (Process Id) 进程Id; - E:
USER= (User Name) 进程所有者的用户名; - H:
PR= (Priority) 优先级 - I:
NI= (Nice value) nice值。负值表示高优先级,正值表示低优先级 - O:
VIRT= (Virtual Image (kb)) 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES - Q:
RES= (Resident size (kb)) 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA - T:
SHR= (Shared Mem size (kb)) 共享内存大小,单位kb - W:
S= (Process Status) 进程状态。D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程 - K:
%CPU= (CPU usage) 上次更新到现在的CPU时间占用百分比 - N:
%MEM= (Memory usage (RES)) 进程使用的物理内存百分比 - M:
TIME+ = (CPU Time, hundredths) 进程使用的CPU时间总计,单位1/100秒
b:PPID= (Parent Process Pid) 父进程Id
c:RUSER= (Real user name)
d:UID= (User Id) 进程所有者的用户id
f:GROUP= (Group Name) 进程所有者的组名
g:TTY= (Controlling Tty) 启动进程的终端名。不是从终端启动的进程则显示为 ?
j:P= (Last used cpu (SMP)) 最后使用的CPU,仅在多CPU环境下有意义
p:SWAP= (Swapped size (kb)) 进程使用的虚拟内存中,被换出的大小,单位kb
l:TIME= (CPU Time) 进程使用的CPU时间总计,单位秒
r:CODE= (Code size (kb)) 可执行代码占用的物理内存大小,单位kb
s:DATA= (Data+Stack size (kb)) 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
u:nFLT= (Page Fault count) 页面错误次数
v:nDRT= (Dirty Pages count) 最后一次写入到现在,被修改过的页面数
y:WCHAN= (Sleeping in Function) 若该进程在睡眠,则显示睡眠中的系统函数名
z:Flags= (Task Flags <sched.h>) 任务标志,参考 sched.h - X:
COMMAND= (Command name/line) 命令名/命令行
mv 修改心跳文件名字 可以暂停外部访问自己进行测试 之后再用curl模拟请求
awk -F " " '{print $7}' | sort | more | uniq -c 一般可以直接以此解析日志 取到所需要的内容
查找文件
find / -name filename.txt 根据名称查找/目录下的filename.txt文件。
find . -name "*.xml" 递归查找所有的xml文件
find . -name "*" |xargs grep "hello" 递归查找所有文件内容中包含hello world的xml文件
grep -H 'spring' *.xml 查找所以有的包含spring的xml文件
find ./ -size 0 | xargs rm -f & 删除文件大小为零的文件
ls -l | grep '.jar' 查找当前目录中的所有jar文件
grep 'test' d* 显示所有以d开头的文件中包含test的行。
grep 'test' aa bb cc 显示在aa,bb,cc文件中匹配test的行。
grep '[a-z]\{5\}' aa 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
查看一个程序是否运行
ps –ef|grep tomcat 查看所有有关tomcat的进程
ps -ef|grep --color java 高亮要查询的关键字
终止进程
kill -9 19979 终止线程号位19979的进程
查看文件,包含隐藏文件
ls -al
当前工作目录
pwd
复制文件
cp source dest 复制文件
cp -r sourceFolder targetFolder 递归复制整个文件夹
scp sourecFile name@ip:addr 远程拷贝
创建目录
mkdir newfolder
删除目录
rmdir deleteEmptyFolder 删除空目录
rm -rf deleteFile 递归删除目录中所有内容
移动文件
mv /temp/movefile /targetFolder
重命名
mv oldNameFile newNameFile
切换用户
su -username
修改文件权限
chmod 777 file.java file.java的权限-rwxrwxrwx,r表示读、w表示写、x表示可执行
压缩文件
tar -czf test.tar.gz /test1 /test2
列出压缩文件列表
tar -tzf test.tar.gz
解压文件
tar -xvzf test.tar.gz
查看文件前10行
head -n 10 example.txt
查看文件后10行
tail -n 10 example.txt
查看日志最近更新
tail -f exmaple.log 这个命令会自动显示新增内容,屏幕只显示10行内容的(可设置)。
使用超级管理员身份执行命令
sudo rm a.txt 使用管理员身份删除文件
查看端口占用情况
netstat -tln | grep 8080 查看端口8080的使用情况
查看端口属于哪个进程
lsof -i :8080
查看进程
ps aux|grep java 查看java进程
ps aux 查看所有进程
以树状格式列出目录
tree a
PS:Mac下使用tree命令
文件下载
wget http://file.tgz
PS :Mac下安装wget命令
curl http://file.tgz
网络检测
ping www.just-ping.com
远程登录
ssh userName@ip
打印信息
echo $JAVA_HOME 打印java home环境变量的值
Java常用命令
java
javac
其他命令
svn
git
maven
p.s.参考 Hollis 微信公众