1、选取最适用的字段属性
MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN来定义整型字段。
另外一个提高效率的方法是在可能的情况下,应该尽量把字段设置为NOTNULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
2、使用连接(JOIN)来代替子查询(Sub-Queries)
MySQL从4.1开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。例如,我们要将客户基本信息表中没有任何订单的客户删除掉,就可以利用子查询先从销售信息表中将所有发出订单的客户ID取出来,然后将结果传递给主查询,如下所示:
DELETE FROM customerinfo
WHERE CustomerID NOT IN (SELECT CustomerID FROM salesinfo)
使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询可以被更有效率的连接(JOIN)..替代。例如,假设我们要将所有没有订单记录的用户取出来,可以用下面这个查询完成:
SELECT * FROM customerinfo
WHERE CustomerID NOT IN (SELECTC ustomerID FROM salesinfo)
如果使用连接(JOIN)..来完成这个查询工作,速度将会快很多。尤其是当salesinfo表中对CustomerID建有索引的话,性能将会更好,查询如下:
SELECT * FROM customerinfo
LEFT JOIN salesinfo ON customerinfo.CustomerID=salesinfo.CustomerID
WHERE salesinfo.CustomerID ISNULL
连接(JOIN)..之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
3、使用联合(UNION)来代替手动创建的临时表
MySQL从4.0的版本开始支持union查询,它可以把需要使用临时表的两条或更多的select查询合并的一个查询中。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用union来创建查询的时候,我们只需要用UNION作为关键字把多个select语句连接起来就可以了,要注意的是所有select语句中的字段数目要想同。下面的例子就演示了一个使用UNION的查询。
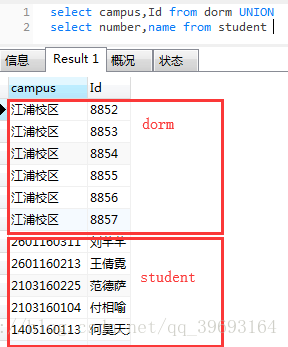
select campus,Id from dorm UNION
...UNION
select number,name from student
例如
4、使用索引
索引是提高数据库性能的常用方法,它可以令数据库服务器以比没有索引快得多的速度检索特定的行,尤其是在查询语句当中包含有MAX(),MIN()和ORDERBY这些命令的时候,性能提高更为明显。
那该对哪些字段建立索引呢?
一般说来,索引应建立在那些将用于JOIN,WHERE判断和ORDERBY排序的字段上。尽量不要对数据库中某个含有大量重复的值的字段建立索引。对于一个ENUM类型的字段来说,出现大量重复值是很有可能的情况
例如customerinfo中的“province”..字段,在这样的字段上建立索引将不会有什么帮助;相反,还有可能降低数据库的性能。我们在创建表的时候可以同时创建合适的索引,也可以使用ALTERTABLE或CREATEINDEX在以后创建索引。此外,MySQL从版本3.23.23开始支持全文索引和搜索。全文索引在MySQL中是一个FULLTEXT类型索引,但仅能用于MyISAM类型的表。对于一个大的数据库,将数据装载到一个没有FULLTEXT索引的表中,然后再使用ALTERTABLE或CREATEINDEX创建索引,将是非常快的。但如果将数据装载到一个已经有FULLTEXT索引的表中,执行过程将会非常慢。
5、优化的查询语句
1)select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的
2) 对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
3) Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
4) 不要写一些没有意义的查询,如需要生成一个空表结构:select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
5) 在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
6) 不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
7) 应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
8) 应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = '张三'
可以这样查询:
select id from t where num = 10 union allselect id from t where Name = '张三'
9) in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
10) 下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%’
若要提高效率,可以考虑全文检索。
读者可以再下方留下更好的优化技巧,欢迎交流~~