HashMap概述
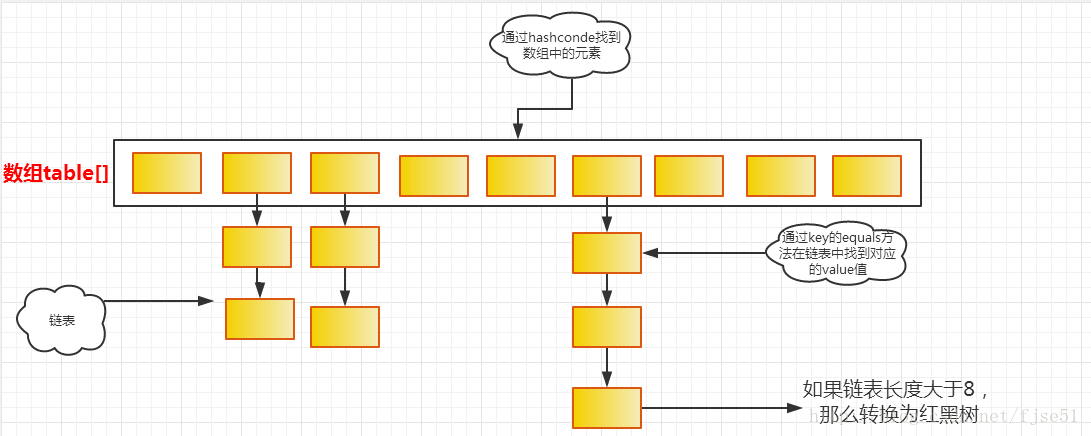
HashMap存储的是key-value的键值对,允许key为null,也允许value为null。HashMap内部为数组+链表的结构,会根据key的hashCode值来确定数组的索引(确认放在哪个桶里),如果遇到索引相同的key,桶的大小是2,如果一个key的hashCode是7,一个key的hashCode是3,那么他们就会被分到一个桶中(hash冲突),如果发生hash冲突,HashMap会将同一个桶中的数据以链表的形式存储,但是如果发生hash冲突的概率比较高,就会导致同一个桶中的链表长度过长,遍历效率降低,所以在JDK1.8中如果链表长度到达阀值(默认是8),就会将链表转换成红黑二叉树。
HashMap数据结构
1 2 //Node本质上是一个Map.存储着key-value 3 static class Node<K,V> implements Map.Entry<K,V> { 4 final int hash; //保存该桶的hash值 5 final K key; //不可变的key 6 V value; 7 Node<K,V> next; //指向一个数据的指针 8 9 Node(int hash, K key, V value, Node<K,V> next) { 10 this.hash = hash; 11 this.key = key; 12 this.value = value; 13 this.next = next; 14 }
从源码上可以看到,Node实现了Map.Entry接口,本质上是一个映射(k-v)
刚刚也说过了,有时候两个key的hashCode可能会定位到一个桶中,这时就发生了hash冲突,如果HashMap的hash算法越散列,那么发生hash冲突的概率越低,如果数组越大,那么发生hash冲突的概率也会越低,但是数组越大带来的空间开销越多,但是遍历速度越快,这就要在空间和时间上进行权衡,这就要看看HashMap的扩容机制,在说扩容机制之前先看几个比较重要的字段
1 //默认桶16个 2 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 3 4 //默认桶最多有2^30个 5 static final int MAXIMUM_CAPACITY = 1 << 30; 6 7 //默认负载因子是0.75 8 static final float DEFAULT_LOAD_FACTOR = 0.75f; 9 10 //能容纳最多key_value对的个数 11 int threshold; 12 13 //一共key_value对个数 14 int size;
threshold=负载因子 * length,也就是说数组长度固定以后, 如果负载因子越大,所能容纳的元素个数越多,如果超过这个值就会进行扩容(默认是扩容为原来的2倍),0.75这个值是权衡过空间和时间得出的,建议大家不要随意修改,如果在一些特殊情况下,比如空间比较多,但要求速度比较快,这时候就可以把扩容因子调小以较少hash冲突的概率。相反就增大扩容因子(这个值可以大于1)。
size就是HashMap中键值对的总个数。还有一个字段是modCount,记录是发生内部结构变化的次数,如果put值,但是put的值是覆盖原有的值,这样是不算内部结构变化的。
因为HashMap扩容每次都是扩容为原来的2倍,所以length总是2的次方,这是非常规的设置,常规设置是把桶的大小设置为素数,因为素数发生hash冲突的概率要小于合数,比如HashTable的默认值设置为11,就是桶的大小为素数的应用(HashTable扩容后不能保证是素数)。HashMap采用这种设置是为了在取模和扩容的时候做出优化。
确定哈希桶数据索引位置
HashMap的put方法实现
HashMap的get方法实现
扩容机制
总结