pacemaker简介:
pacemaker作为linux系统高可用HA的资源管理器,位于HA集群架构中的资源管理,资源代理层,它不提供底层心跳信息传递功能。(心跳信息传递是通过corosync来处理的这个使用有兴趣的可以在稍微了解一下,其实corosync并不是心跳代理的唯一组件,可以用hearbeat等来代替)。pacemaker管理资源是通过脚本的方式来执行的。我们可以将某个服务的管理通过shell,python等脚本语言进行处理,在多个节点上启动相同的服务时,如果某个服务在某个节点上出现了单点故障那么pacemaker会通过资源管理脚本来发现服务在改节点不可用。
pacemaker只是作为HA的资源管理器,所以不要想当然理解它能够直接管控资源,如果你的资源没有做脚本配置那么对于pacemaker来说它就是不可管理的。
服务安装与配置:
【server4】
[root@server4 corosync]#yum install -y pacemaker
[root@server4 corosync]# cp corosync.conf.example corosync.conf
[root@server4 corosync]# yum install -y corosync
[root@server4 corosync]# vim corosync.conf
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 172.25.39.0
mcastaddr: 226.94.1.39
mcastport: 5405
ttl: 1
}
}
最后添加:
service {
name: pacemaker
ver: 0
}【server1】
发送【server4】配置文件到【server1】,配置一致
[root@server4 corosync]# scp corosync.conf [email protected]:/etc/corosync/
The authenticity of host '172.25.39.1 (172.25.39.1)' can't be established.
RSA key fingerprint is ce:b7:35:21:60:9f:f3:8d:f4:25:af:73:ad:ad:bc:ab.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '172.25.39.1' (RSA) to the list of known hosts.
[email protected]'s password:
corosync.conf 100% 446 0.4KB/s 00:00
[root@server4 corosync]#yum install -y pacemaker
[root@server4 corosync]# yum install -y corosync
[root@server1 ~]# /etc/init.d/pacemaker start
Starting Pacemaker Cluster Manager [ OK ]
[root@server1 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]
在【server1】和【server4】主机上同时下载
yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm 【server1】监控结点连接状态crm_mon
Last updated: Sat Aug 4 15:59:32 2018
Last change: Sat Aug 4 15:59:24 2018 via crmd on server4
Stack: classic openais (with plugin)
Current DC: server4 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured, 2 expected votes
0 Resources configured
Online: [ server1 server4 ]
【server4】进入交互式:
[root@server4 corosync]# crm
crm(live)# configure
crm(live)configure# show
node server4
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
添加虚拟IP:
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.39.100 cidr_netmask=24 op monitor interval=1min
crm(live)configure# show
node server1
node server4
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.39.100" cidr_netmask="24" \
op monitor interval="1min"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="fals"
crm(live)configure# commit
error: cluster_option: Value 'fals' for cluster option 'stonith-enabled' is invalid. Defaulting to true
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
Do you still want to commit? n
crm(live)configure# property
batch-limit= enable-startup-probes= pe-error-series-max= stonith-enabled=
cluster-delay= is-managed-default= pe-input-series-max= stonith-timeout=
cluster-recheck-interval= maintenance-mode= pe-warn-series-max= stop-all-resources=
crmd-transition-delay= migration-limit= placement-strategy= stop-orphan-actions=
dc-deadtime= no-quorum-policy= remove-after-stop= stop-orphan-resources=
default-action-timeout= node-health-green= shutdown-escalation= symmetric-cluster=
default-resource-stickiness= node-health-red= start-failure-is-fatal=
election-timeout= node-health-strategy= startup-fencing=
enable-acl= node-health-yellow= stonith-action=
crm(live)configure# property stonith-enabled=false ##关闭fence
crm(live)configure# commit
crm(live)configure# show
node server1
node server4
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.39.100" cidr_netmask="24" \
op monitor interval="1min"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false"测试:
关闭server1服务:
[server1]
Reconnecting...[root@server1 ~]# /etc/init.d/corosync stop
Signaling Corosync Cluster Engine (corosync) to terminate: [ OK ]
Waiting for corosync services to unload:. [ OK ]查看到【server1】下线
[server4]监控
Last updated: Sat Aug 4 16:29:47 2018
Last change: Sat Aug 4 16:22:15 2018 via cibadmin on server4
Stack: classic openais (with plugin)
Current DC: server4 - partition WITHOUT quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured, 2 expected votes
1 Resources configured
Online: [ server4 ]
OFFLINE: [ server1 ]
重新让【server1】上线
【server1】
[root@server1 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]查看到【server1】又重新工作
Last updated: Sat Aug 4 16:31:39 2018
Last change: Sat Aug 4 16:22:15 2018 via cibadmin on server4
Stack: classic openais (with plugin)
Current DC: server4 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured, 2 expected votes
1 Resources configured
Online: [ server1 server4 ]
vip (ocf::heartbeat:IPaddr2): Started server1若是一个双结点集群,当有一端关掉服务时,另一结点则会自动丢弃资源,也不再接管,因为一个结点不能构成集群
[root@server4 ~]# crm node standby
表示不接管资源,但心跳仍正常;当恢复为node时,资源不会回切
[server1]
Last updated: Sat Aug 4 16:53:43 2018
Last change: Sat Aug 4 16:52:10 2018 via crm_attribute on server4
Stack: classic openais (with plugin)
Current DC: server4 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured, 2 expected votes
2 Resources configured
Node server4: standby ##当前节点已经停止
Online: [ server1 ]
Resource Group: hagroup
vip (ocf::heartbeat:IPaddr2): Started server1 ##【server1】备用节点开始工作
haproxy (lsb:haproxy): Started server1
[server4]
[root@server4 ~]# crm node online
[server1]
Last updated: Sat Aug 4 16:59:02 2018
Last change: Sat Aug 4 16:59:02 2018 via crm_attribute on server4
Stack: classic openais (with plugin)
Current DC: server4 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured, 2 expected votes
2 Resources configured
Online: [ server1 server4 ]
Resource Group: hagroup
vip (ocf::heartbeat:IPaddr2): Started server1
haproxy (lsb:haproxy): Started server1Fence机制
在server1和server4上建立/etc/cluster
[root@foundation39 ~]# systemctl start fence_virtd
[root@foundation39 cluster]# scp -r fence_xvm.key root@172.25.39.1:/etc/cluster/ #将fence的钥匙传给server1
[root@foundation40 cluster]# scp -r fence_xvm.key root@172.25.39.4:/etc/cluster/ #将fence的钥匙传给server4[root@server4 ~]# crm
crm(live)# configure
crm(live)configure# property stonith-enabled=true #开启fence机制,更改为ture表示资源会迁移
crm(live)configure# commit
[root@server4 cluster]# yum install -y fence-virt #在server1上相同下载fence-virt
[root@server4 cluster]# crm
crm(live)# configure
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="server1:test1;server4:test4" op monitor interval=1min #添加vmfence
crm(live)configure# commit
crm(live)configure# show
node server1
node server4 \
attributes standby="off"
primitive haproxy lsb:haproxy \
op monitor interval="1min"
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.39.100" cidr_netmask="24" \
op monitor interval="1min"
primitive vmfence stonith:fence_xvm \
params pcmk_host_map="server1:test1;server4:test4" \
op monitor interval="1min"
group hagroup vip haproxy
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
crm(live)configure# property stonith-enabled=true
crm(live)configure# commit 测试:
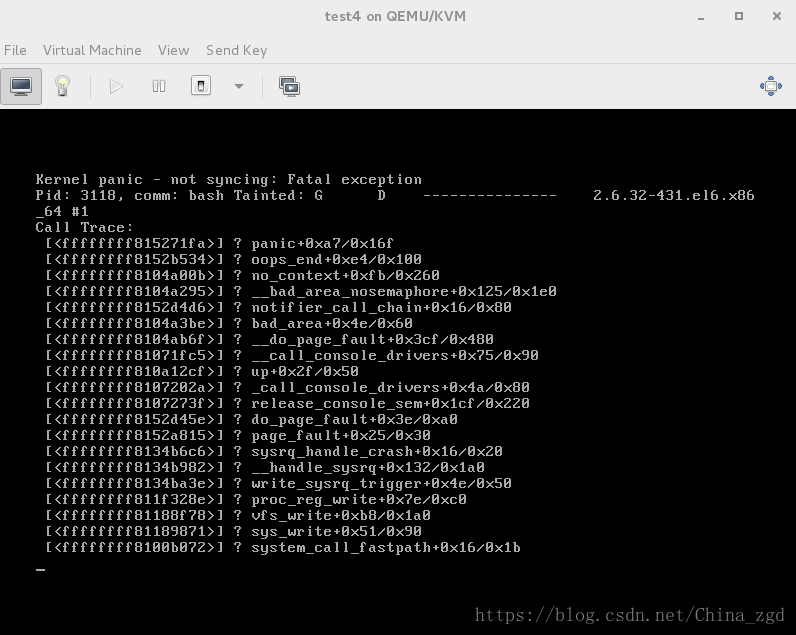
崩溃server4内核,server4自动重启
server1会接管他的工作
服务起在哪个节点崩溃哪个内核
[root@server4 cluster]# echo c > /proc/sysrq-trigger