前言
自然语言处理,基础部分是语言模型,即如何描述自然语句所需要的数学模型,在此之上,词的表达是重要的学习任务。
概率语言模型
现在应用范围最广的就是概率语言模型了,以条件概率来描述某句话出现的概率。比如这个句子“小猫在草地上打滚”,我们将这句话出现的概率拆解成条件概率:
多么简单明了的数学模型啊,当前词出现的概率,依赖于之前的所有出现过的词,很符合顺序逻辑。
首先面临的问题是: 依赖关系太长,计算成了不现实的问题;另外, 词的表示 就成了NLP迫切需要解决的事情了。针对第一个问题,最先出现的是Ngram方法,将依赖限制到固定相邻几个词范围内,其本质上仍然将词作为孤立的单元,以one-hot形式出现的;关于后者,如下要介绍的方法,都是在概率语言模型下,就学习词向量所做的工作。
skip-gram & CBOW
首先出现的神级作品,就是Mikolov的skip-gram学习模型,第一次用超级简单的模型实现了大规模数据集(百个10亿规模)的词向量学习。
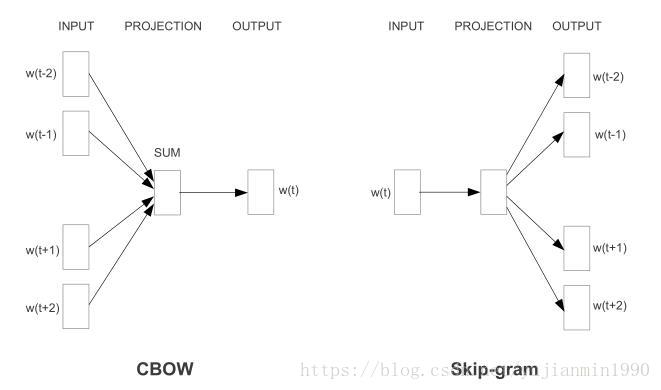
1)skip-gram: 以中心词来预测周围词。
2)CBOW: 以周围词来预测中心词,词袋模型。
两者相比,词袋模型训练时间更短,但是skip-gram更精准。
为提高优化效率,利用 分层softmax,该方法首次应用在语言模型中,是在05年,Morin, Bengio的 《Hierarchical Probabilistic Neural Network Language Model》。
skip-gram的升级版本,还是Mikolov,使用Negative Sample Method NEG代替Hierarchical Softmax, 并辅助以 下采样方法解决高低频词分布不均衡问题。同时,将熟语作为整体来训练,得到熟语的词向量表示。其 负采样下的样本pair概率计算如下:
其中 是单个词在语料中的频次分布,再作 的幂次方, 在是小样本集下取[5,20],大样本集下取[2,5],论文中的经验值。
整体优化目标,仍是窗口内的周围词概率最大化:
下采样的基本思想 是由于高低频词的严重不均衡化,导致高频词的信息能提供的信息比低频词要少,那么适当的采样是科学合理的。其采样概率基于频词作适当调整,以 丢弃训练词 ,越高频的越容易被丢弃, 是手选阈值,通常为 :
NEG方法训练更快,不再沿路径计算路径节点只需采样即可,并且对高频词更友好;下采样方法可提高2~10倍训练速度,且对低频词更友好。
NCE和NEG的关系: NCE可以用来做为softmax的log概率的最大化估计,基于NCE采样来表示条件概率 ,以此做词向量训练的方法名称被Mikolov称为NEG。NCE的首次提出是12年Gutmann, Hyvrinen 的 《Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics》,首次用在Language Model中是13年Minh, Whye Teh的 《A Fast and Simple Algorithm for Training Neural Probabilistic Languages Models》。
notice 1:为什么之前的方法不能够实现超大规模数据集的学习,因为大部分的方法,比如LSI / LSA是基于矩阵分解的。
notice 2: 2003,bengio的 《A Neural Probabilistic Language Model》才是Word Embedding的首次提出,尝试将one-hot词表示通过前向神经网络映射成稠密表示。
noitce 3: 对分层softmax 和 NEG有个比较好的 博客介绍。
GloVec
GloVec,global vectors 弥补了全局和局部(窗口类方法)的割裂性,本质仍然是统计模型分解,也是简单模型计算词向量的典型算法,14年由Pennington提出,是一个统计强化版的skip-gram。
如何得到的GloVec的思路有点绕,简单如下解释:
1) 假设
表示词
出现在词
上下文中的概率,
表示词
在词
上下文中的频次。其中
依赖于三个词
,将依赖关系表示为
。
2) 词向量的空间是具有线性特质的,那么表示两个词的商,用差来描述也是可以的:
3) 为了更好地对齐两边的形式,压缩为数值:
4) 将商与差的假设关系【隐藏着log通解】替换上去:
5) 将假设关系对应的通解带入:
6) 一般还会加入bias:
,
作为常数合并到bias中。
整体优化目标:
f(x)是非减函数,f(0)=0,对大值x->f(x)较小,避免overweight。论文给出了非常适合的一个f函数:
,其中
最后还给出了skip-gram也放到这个解释框架下的样式,从而给出结论,GloVec能覆盖住skip-gram窗口所不能覆盖的全局统计信息。
notice 1: 词向量的学习有个有意思的现象, 模型简单并不会影响词向量的好使程度。
notice 2: 矩阵分解类方法,矩阵形式有term-doc和term-term;分解方法有LSA/HAL/COALS/PPMI/HPCA。
noitce 3: 关于方程通解问题,详细了解可以找下高等数学下册部分。
RNN-LM
基于RNN结构来学习词向量,还是这个Mikolov,他的RNNLM工作都总结在博士论文里,超级长还不如看开源代码。
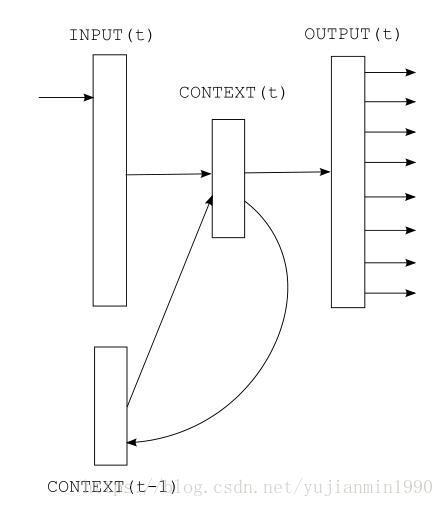
主要是做啥呢?如下图解释:
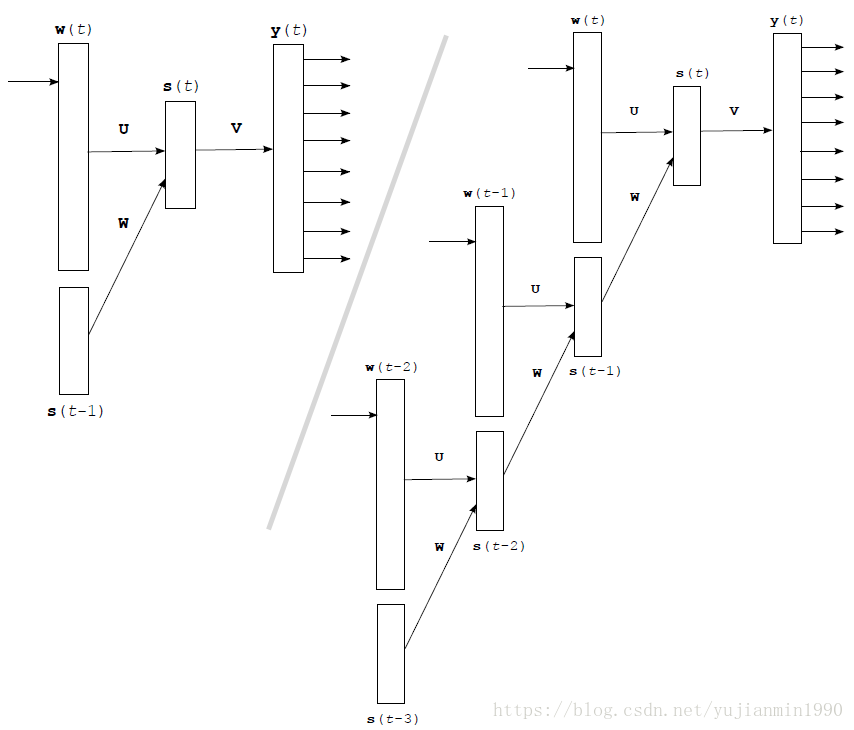
主要公式: ,其中 是one-hot的词, 是向量矩阵。
RNN可以真正充分地利用所有上文信息来预测下一个词,而不像前面的其它工作那样,只能开一个 n 个词的窗口,只用前 n 个词来预测下一个词。就是这里使用的RNN是最简单的RNN结构,训练优化比较困难。为缓解巨大的词表带来的softmax过大问题,根据词频将 个词分成 ,先判断是哪个组再判断是哪个词。
拓展思考
非直接统计目标学习的词向量
直接用索引式的向量矩阵来表示词向量集合,然后基于当前的学习任务(非上述统计的学习任务,而是比如分类等任务),这个时候学习得到的词向量,是匹配当前任务度最好的词向量。只不过不再是基于统计目标优化得到的词向量,而成了是基于任务目标优化得到的词向量。没有明确结论两者有优劣之分的。
Debiasing Word Embdding
这个问题应该是模型对现实世界的真实反映,为什么词向量里面会出现歧视色彩,主要是语料库来自现实世界,而现实中就是存在歧视现象。所谓的修正,也仅限于人为的修正。基本方法如下:
1)用一组偏性别词向量,计算其主成分,top-one则是性别方向g,作为性别子空间。
2)指定中性别词集合,其与性别子空间的距离要保持阈值以上。
受限于各种原因,本文对word embedding的各个方面并没有照顾地那么全,希望读者多多思考和补充。
Reference
- 《2013 - Efficient Estimation of Word Representations in Vector Space》
- 《2013 - Distributed Representations of Words and Phrases and their Compositionality》建议重点阅读。
- 《2003 - A Neural Probabilistic Language Model》
- 《2005 - Hierarchical Probabilistic Neural Network Language Model》
- 《2012 - Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics》
- 《2013 - A Fast and Simple Algorithm for Training Neural Probabilistic Languages Models》
- 《2014 - GloVe: Global Vectors for Word Representation》
- 《2010 - Recurrent Neural Network based Language Model》
- 《2013 - Distributed Representations of Words and Phrases and their Compositionality》