目录
2.1 词的独热表示one-hot representation
2.2 词的分布式表示distributed representation
GloVe模型(Global Vectors for Word Representation)
2.2.3 基于神经网络的分布表示,词嵌入( word embedding)
4.4 Word2Vec,Glove,FastText等各类WordEmbedding的比较
学习词向量相关内容这么久之后发现对word2vec, GloVe, Word Embedding这些内容的整体关系还不是很清楚,现在就稍微总结下词向量的整体框架到底是怎样的。
1 概述
先提下数据特征表示问题。数据表示是机器学习的核心问题,在过去的Machine Learning阶段,大量兴起特征工程,人工设计大量的特征解决数据的有效表示问题。而到了Deep Learning,想都别想,end2end,一步到位,hyper-parameter自动帮你选择寻找关键的特征参数。
那么在NLP领域,文字是如何表示的呢?其实很简答,类比于声音和图像,它俩都是通过matrix组成的vector来实现,那么文字其实也是通过vector的形式来表示的。
2 词的表示方法类型
2.1 词的独热表示one-hot representation
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。关于one-hot编码的资料很多,街货,这里简单举个栗子说明:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ...]
每个词都是茫茫 0 海中的一个 1。这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
现在我们分析他的不当处。1、向量的维度会随着句子的词的数量类型增大而增大;2、任意两个词之间都是孤立的,根本无法表示出在语义层面上词语词之间的相关信息,而这一点是致命的。
2.2 词的分布式表示distributed representation
传统的独热表示( one-hot representation)仅仅将词符号化,不包含任何语义信息。如何将语义融入到词表示中?Harris 在 1954 年提出的分布假说( distributional hypothesis)为这一设想提供了理论基础:上下文相似的词,其语义也相似。Firth 在 1957 年对分布假说进行了进一步阐述和明确:词的语义由其上下文决定( a word is characterized by thecompany it keeps)。
到目前为止,基于分布假说的词表示方法,根据建模的不同,主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。尽管这些不同的分布表示方法使用了不同的技术手段获取词表示,但由于这些方法均基于分布假说,它们的核心思想也都由两部分组成:一、选择一种方式描述上下文;二、选择一种模型刻画某个词(下文称“目标词”)与其上下文之间的关系。
2.2.1 基于矩阵的分布表示(Glove)
基于矩阵的分布表示通常又称为分布语义模型,在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。由于分布假说认为上下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。
常见到的Global Vector 模型( GloVe模型)是一种对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示。
GloVe模型(Global Vectors for Word Representation)
http://www.fanyeong.com/2018/02/19/glove-in-detail/
https://blog.csdn.net/u014665013/article/details/79642083
GloVe构建过程


2.2.2 基于聚类的分布表示
后续更新。。。
2.2.3 基于神经网络的分布表示,词嵌入( word embedding)
基于神经网络的分布表示一般称为词向量、词嵌入( word embedding)或分布式表示( distributed representation)。
神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模。由于神经网络较为灵活,这类方法的最大优势在于可以表示复杂的上下文。在前面基于矩阵的分布表示方法中,最常用的上下文是词。如果使用包含词序信息的 n-gram 作为上下文,当 n 增加时, n-gram 的总数会呈指数级增长,此时会遇到维数灾难问题。而神经网络在表示 n-gram 时,可以通过一些组合方式对 n 个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
3 词嵌入
3.1 概念
基于神经网络的分布表示又称为词向量、词嵌入,神经网络词向量模型与其它分布表示方法一样,均基于分布假说,核心依然是上下文的表示以及上下文与目标词之间的关系的建模。
前面提到过,为了选择一种模型刻画某个词(下文称“目标词”)与其上下文之间的关系,我们需要在词向量中capture到一个词的上下文信息。同时,上面我们恰巧提到了统计语言模型正好具有捕捉上下文信息的能力。那么构建上下文与目标词之间的关系,最自然的一种思路就是使用语言模型。从历史上看,早期的词向量只是神经网络语言模型的副产品。
2001年, Bengio 等人正式提出神经网络语言模型( Neural Network Language Model ,NNLM),该模型在学习语言模型的同时,也得到了词向量。所以请注意一点:词向量可以认为是神经网络训练语言模型的副产品。
3.2 理解
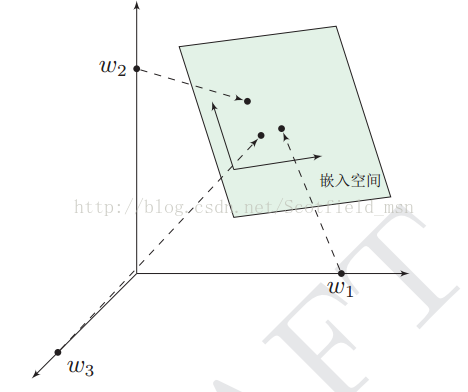
前面提过,one-hot表示法具有维度过大的缺点,那么现在将vector做一些改进:1、将vector每一个元素由整形改为浮点型,变为整个实数范围的表示;2、将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间。如图示:
4 神经网络语言模型与word2vec
4.1 神经网络语言模型
上面说,通过神经网络训练语言模型可以得到词向量,那么,究竟有哪些类型的神经网络语言模型呢?个人所知,大致有这么些个:
a) Neural Network Language Model ,NNLM
b) Log-Bilinear Language Model, LBL
c) Recurrent Neural Network based Language Model,RNNLM
d) Collobert 和 Weston 在2008 年提出的 C&W 模型
e) Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
到这,估计有人看到了两个熟悉的term:CBOW、skip-gram,有看过word2vec的同学应该对此有所了解。我们继续。
4.2 word2vec与CBOW、Skip-gram
现在我们正式引出最火热的另一个term:word2vec。
上面提到的5个神经网络语言模型,只是个在逻辑概念上的东西,那么具体我们得通过设计将其实现出来,而实现CBOW( Continuous Bagof-Words)和 Skip-gram 语言模型的工具正是well-known word2vec!另外,C&W 模型的实现工具是SENNA。
所以说,分布式词向量并不是word2vec的作者发明的,他只是提出了一种更快更好的方式来训练语言模型罢了。分别是:连续词袋模型Continous Bag of Words Model(CBOW)和Skip-Gram Model,这两种都是可以训练出词向量的方法,再具体代码操作中可以只选择其一,不过据论文说CBOW要更快一些。
顺便说说这两个语言模型。统计语言模型statistical language model就是给你几个词,在这几个词出现的前提下来计算某个词出现的(事后)概率。CBOW也是统计语言模型的一种,顾名思义就是根据某个词前面的C个词或者前后C个连续的词,来计算某个词出现的概率。Skip-Gram Model相反,是根据某个词,然后分别计算它前后出现某几个词的各个概率。
补充下,Word embedding的训练方法大致可以分为两类:一类是无监督或弱监督的预训练;一类是端对端(end to end)的有监督训练。无监督或弱监督的预训练以word2vec和auto-encoder为代表。这一类模型的特点是,不需要大量的人工标记样本就可以得到质量还不错的embedding向量。不过因为缺少了任务导向,可能和我们要解决的问题还有一定的距离。因此,我们往往会在得到预训练的embedding向量后,用少量人工标注的样本去fine-tune整个模型。
相比之下,端对端的有监督模型在最近几年里越来越受到人们的关注。与无监督模型相比,端对端的模型在结构上往往更加复杂。同时,也因为有着明确的任务导向,端对端模型学习到的embedding向量也往往更加准确。例如,通过一个embedding层和若干个卷积层连接而成的深度神经网络以实现对句子的情感分类,可以学习到语义更丰富的词向量表达。
4.2.1 CBOW
4.2.2 Skip-Gram
4.3 其他WordEmbedding形式
4.3.1 FastText
推荐博文https://blog.csdn.net/feilong_csdn/article/details/88655927
模型架构
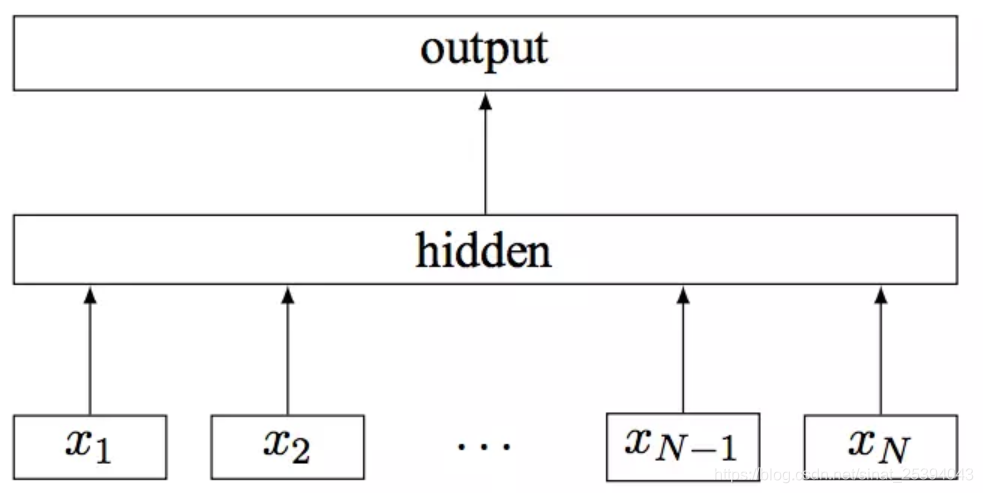
其中x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
这里的n-gram向量指的是除了词的子串外,词本身也被包含进了 n-gram字母串包。以 where 为例,n=3n=3 的情况下,其子串分别为
<wh, whe, her, ere, re>,以及其本身 。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
使用N-gram优点:
1、为罕见的单词生成更好的单词向量:根据上面的字符级别的n-gram来说,即是这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量
2、在词汇单词中,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量
3、n-gram可以让模型学习到局部单词顺序的部分信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息
但正如上面提到过,随着语料库的增加,内存需求也会不断增加,严重影响模型构建速度,针对这个有以下几种解决方案:
1、过滤掉出现次数少的单词
2、使用hash存储
3、由采用字粒度变化为采用词粒度
4.3.2 doc2vec
尽管word2vec提供了高质量的词汇向量,仍然没有有效的方法将它们结合成一个高质量的文档向量。对于一个句子、文档或者说一个段落,怎么把这些数据投影到向量空间中,并具有丰富的语义表达呢?过去人们常常使用以下几种方法:
- bag of words
- LDA
- average word vectors
- tfidf-weighting word vectors
就bag of words而言,有如下缺点:1.没有考虑到单词的顺序,2.忽略了单词的语义信息。因此这种方法对于短文本效果很差,对于长文本效果一般,通常在科研中用来做baseline。
average word vectors就是简单的对句子中的所有词向量取平均。是一种简单有效的方法,但缺点也是没有考虑到单词的顺序
tfidf-weighting word vectors是指对句子中的所有词向量根据tfidf权重加权求和,是常用的一种计算sentence embedding的方法,在某些问题上表现很好,相比于简单的对所有词向量求平均,考虑到了tfidf权重,因此句子中更重要的词占得比重就更大。但缺点也是没有考虑到单词的顺序
LDA模型当然就是计算出一片文档或者句子的主题分布。也常常用于文本分类任务,后面会专门写一篇文章介绍LDA模型和doc2vec的本质不同。
Doc2Vec 或者叫做 paragraph2vec, sentence embeddings,是一种非监督式算法,可以获得 sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性,可以用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如经典的情感分析问题。
doc2vec基本原理
训练句向量的方法和词向量的方法非常类似。训练词向量的核心思想就是说可以根据每个单词的上下文预测,也就是说上下文的单词对是有影响的。那么同理,可以用同样的方法训练doc2vec。例如对于一个句子i want to drink water,如果要去预测句子中的单词want,那么不仅可以根据其他单词生成feature, 也可以根据其他单词和句子来生成feature进行预测。
doc2vec训练方法
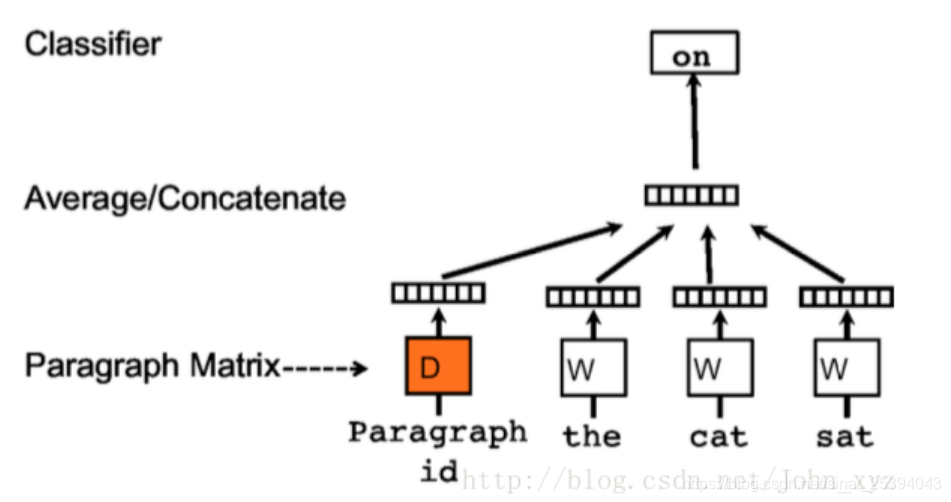
1.Distributed Memory Model of Paragraph Vectors(PVDM)
它不是仅是使用一些单词来预测下一个单词,我们还添加了另一个特征向量,即文档Id。
因此,当训练单词向量W时,也训练文档向量D,并且在训练结束时,它包含了文档的向量化表示。
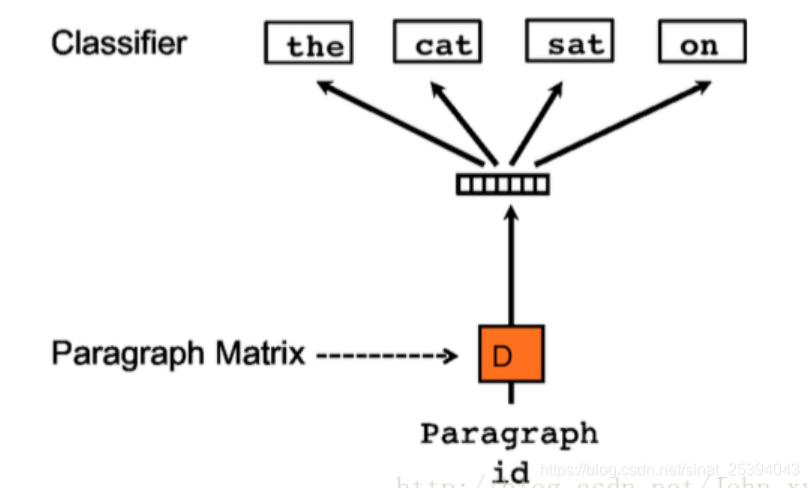
2.Distributed Bag of Words version of Paragraph Vector(PV-DBOW)
4.3.3 Sentence2Vec
类似于Sentence2Vec
4.3.4 cw2vec
推荐博文 https://blog.csdn.net/HHTNAN/article/details/81807680
4.4 Word2Vec,Glove,FastText等各类WordEmbedding的比较
Glove与Word2Vec https://zhuanlan.zhihu.com/p/31023929

word2vec、fastText:优化效率高,但是基于局部语料;glove:基于全局预料,结合了LSA和word2vec的优点;基于NNLM/RNNLM的词向量:词向量为副产物,存在效率不高等问题;矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大;elmo、GPT、bert:动态特征;


5 References
https://blog.csdn.net/Scotfield_msn/article/details/69075227
https://blog.csdn.net/u014033218/article/details/88526003
http://www.fanyeong.com/2018/02/19/glove-in-detail/
https://blog.csdn.net/rosefun96/article/details/85688014
cw2vec https://blog.csdn.net/HHTNAN/article/details/81807680
doc2vec https://blog.csdn.net/u010417185/article/details/80654558
