官方文档:API
Pipeline执行流程的分析
管道 Pipeline按顺序应用列表转换和最终的估计量。 中间步骤的管道必须“转换”,也就是说,他们 必须实现拟合和转换方法。 最后估计只需要实现。 在 Pipeline里,转化器可以使用内存来进行缓存。
管道 Pipeline的目的就是可以组装几个步骤 旨在在一起而设置不同的参数。 为此,可以为各个步骤设置参数名称。
流水线Pipeline机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
流水线机制实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines)。
注意:流水线机制更像是编程技巧的创新,而非算法的创新。
Pipeline 的中间过程由scikit-learn相适配的转换器(transformer)构成,最后一步是一个estimator。比如上述的代码,StandardScaler和PCA transformer 构成intermediate steps,LogisticRegression 作为最终的estimator。
(注:最后一步一定是estimator)
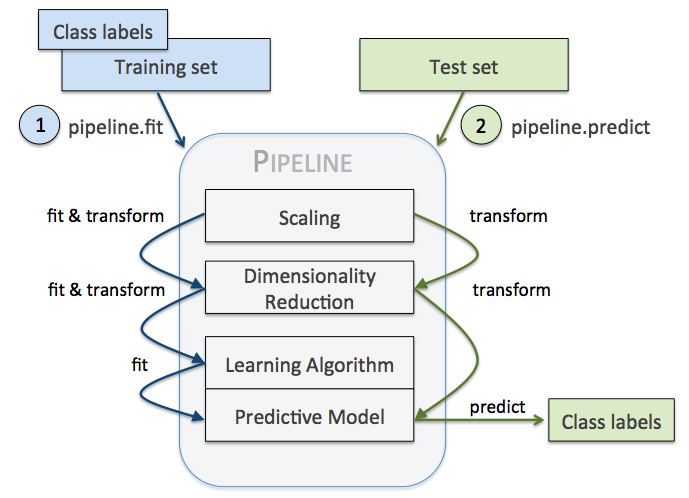
pipeline 与深度神经网络的multi-layers
只不过步骤(step)的概念换成了层(layer)的概念,甚至the last step 和 输出层的含义都是一样的。
参考资料:https://blog.csdn.net/lanchunhui/article/details/50521648