使用sklearn库来进行k-means聚类十分简单,官网的教程是挺好的。但其他地方的一些例子和教程则很多都是要么只是写给作者自己看的,要么是代码不能直接运行的。这里我写这篇文章,用尽量简单的易懂方式来封装k-means代码:
首先创建一个kmeans.py文件,这个文件是k-means算法的封装文件,里面就定义一个函数,用于利用sklearn库来进行k-means聚类,代码如下:
# -*- coding: utf-8 -*-
"""
@author ZibinPan
Created on Tue Feb 27 14:24:29 2018
sklearn k-means聚类实用封装库
用法:传入的参数均为list类型,x1为x坐标,x2为y坐标,types_num为聚类数,types为各类的名称,colors为各类点的颜色,shapes为各类点的形状
返回一个kmeans_model对象,其labels_属性记录着聚类的标签(如0,1,2等),cluster_centers_属性记录着聚类的中心
另外也返回聚类后的x1_result和x2_result对象,x1_result记录着原x1列表的聚类结果,
即x1_result列表中有n个元素(n为聚类数),其中每个元素都是一个列表(原x1列表中属于该类的所有元素组成的列表)
x2_result同上
"""
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
def kmeans_building(x1,x2,types_num,types,colors,shapes):
X = np.array(list(zip(x1, x2))).reshape(len(x1), 2)
kmeans_model = KMeans(n_clusters=types_num).fit(X) # 设置聚类数n_clusters的值为types_num
# 整理分类好的原始数据, 并画出聚类图
x1_result=[]; x2_result=[]
for i in range(types_num):
temp=[]; temp1=[]
x1_result.append(temp)
x2_result.append(temp1)
for i, l in enumerate(kmeans_model.labels_): # 画聚类点
x1_result[l].append(x1[i])
x2_result[l].append(x2[i])
plt.scatter(x1[i], x2[i], c=colors[l],marker=shapes[l])
for i in range(len(list(kmeans_model.cluster_centers_))): # 画聚类中心点
plt.scatter(list(list(kmeans_model.cluster_centers_)[i])[0],list(list(kmeans_model.cluster_centers_)[i])[1],c=colors[i],marker=shapes[i],label=types[i])
plt.legend()
return kmeans_model,x1_result,x2_result然后创建一个test.py文件来调用上面封装好的函数:
import matplotlib.pyplot as plt
import kmeans
plt.figure(figsize=(8, 6))
x1 = [1, 2, 3, 1, 5, 6, 5, 5, 6, 7, 8, 9, 7, 9] # x坐标列表
x2 = [1, 3, 2, 2, 8, 6, 7, 6, 7, 1, 2, 1, 1, 3] # y坐标列表
colors = ['b', 'g', 'r'] # 颜色列表,因为要分3类,所以该列表有3个元素
shapes = ['o', 's', 'D'] # 点的形状列表,因为要分3类,所以该列表有3个元素
labels=['A','B','C'] # 画图的标签内容,A, B, C分别表示三个类的名称
kmeans_model,x1_result,x2_result=kmeans.kmeans_building(x1, x2, 3, labels, colors, shapes) # 本例要分3类,所以传入一个3
print(kmeans_model)
print(x1_result)
print(x2_result)运行效果:
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
[[5, 6, 5, 5, 6], [7, 8, 9, 7, 9], [1, 2, 3, 1]][[8, 6, 7, 6, 7], [1, 2, 1, 1, 3], [1, 3, 2, 2]]
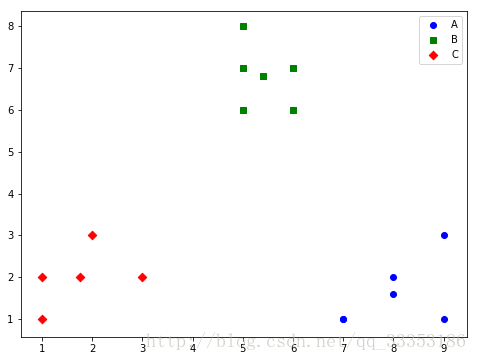
函数返回的x1_result和x2_result便是将原始数据分好类后的数据集。