1.K-Means算法
由于具有出色的速度和良好的可扩展性,K-Means聚类算法算得上是最著名的聚类方法。K-Means算
法是一个重复移动类中心点的过程,把类的中心点,也称重心(centroids),移动到其包含成员的平
均位置,然后重新划分其内部成员。 是算法计算出的超参数,表示类的数量;K-Means可以自动分
配样本到不同的类,但是不能决定究竟要分几个类。 必须是一个比训练集样本数小的正整数。
有时,类的数量是由问题内容指定的。也有一些问题没有指定聚类的数量,最优的聚类
数量是不确定的。后面我们会介绍一种启发式方法来估计最优聚类数量,称为肘部法则(Elbow
Method)。
K-Means的参数是类的重心位置和其内部观测值的位置。与广义线性模型和决策树类似,K-Means参
数的最优解也是以成本函数最小化为目标。K-Means成本函数公式如下:
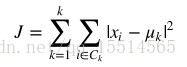
是第 uk个类的重心位置。成本函数是各个类畸变程度(distortions)之和。每个类的畸变程度等于
该类重心与其内部成员位置距离的平方和。若类内部的成员彼此间越紧凑则类的畸变程度越小,反
之,若类内部的成员彼此间越分散则类的畸变程度越大。求解成本函数最小化的参数就是一个重复配
置每个类包含的观测值,并不断移动类重心的过程。首先,类的重心是随机确定的位置。实际上,重
心位置等于随机选择的观测值的位置。每次迭代的时候,K-Means会把观测值分配到离它们最近的
类,然后把重心移动到该类全部成员位置的平均值那里。
原始数据:
2004-01-02,17.96,18.68,17.54,18.22
2004-01-05,18.45,18.49,17.44,17.49
2004-01-06,17.66,17.67,16.19,16.73
2004-01-07,16.72,16.75,15.05,15.05
2004-01-08,15.42,15.68,15.32,15.61
2004-01-09,16.15,16.88,15.57,16.75
2004-01-12,17.32,17.46,16.79,16.82
2004-01-13,16.06,18.33,16.53,18.04
2004-01-14,17.29,17.03,16.04,16.75
2004-01-15,17.07,17.31,15.49,15.56
2004-01-16,15.04,15.44,14.09,15
2004-01-20,15.77,16.13,15.09,15.21
2004-01-21,15.63,15.63,14.24,14.34
2004-01-22,14.02,14.87,14.01,14.71
2004-01-23,14.73,15.05,14.56,14.84
2004-01-26,15.78,15.78,14.52,14.55
2004-01-27,15.28,15.44,14.74,15.35
2004-01-28,15.37,17.06,15.29,16.78
2004-01-29,16.88,17.66,16.79,17.14
2.聚类趋势
'''
Created on 2017年9月21日
@author: zawdcxs
'''
import numpy as np
#读取数据
X = []
f = open('cluster.txt')
for v in f:
X.append(
[float(v.split(',')[-2]),
float(v.split(',')[-1])])
#转换成numpy array
X = np.array(X)
#归一化
a = X[:,:1]/18.68*100
b = X[:,1:]/17.54*100
X = np.concatenate((a,b),axis = 1)
#随机挑选出5个
pn = X[np.random.choice(X.shape[0],5,replace = False),:]
xn = []
for i in pn:
distance_min = 100
for j in X:
if np.array_equal(i, j):
continue
distance = np.linalg.norm(j-i)
if distance_min>distance:
distance_min = distance
xn.append(distance_min)
#随机挑选5个
qn = X[np.random.choice(X.shape[0],5,replace = False),:]
yn = []
for i in qn:
distance_min = 100
for j in X:
if np.array_equal(i, j):
continue
distance = np.linalg.norm(j-i)
if distance_min>distance:
distance_min = distance
yn.append(distance_min)
H = float(np.sum(yn))/(float(np.sum(xn))+float(np.sum(yn)))
print(H)
多次运行结果为:
0.39576295974300946
0.45160223964353785
0.5551196531740811
0.5949108798784908
0.6151669123334003
3.簇数确定
肘部法则:
如果问题中没有指定 的值,可以通过肘部法则这一技术来估计聚类数量。肘部法则会把不同 值的
成本函数值画出来。随着 值的增大,平均畸变程度会减小;每个类包含的样本数会减少,于是样本
离其重心会更近。但是,随着 值继续增大,平均畸变程度的改善效果会不断减低。 值增大过程
中,畸变程度的改善效果下降幅度最大的位置对应的 值就是肘部。
'''
Created on 2017年9月21日
@author: zawdcxs
'''
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
#读取数据
X = []
f = open('cluster.txt')
for v in f:
X.append(
[float(v.split(',')[2]),
float(v.split(',')[3])])
#转换成numpy array
X = np.array(X)
distance = []
k = []
#簇的数量
for n_clusters in range(1,19):
cls = KMeans(n_clusters).fit(X)
#曼哈顿距离
def manhattan_distance(x,y):
return np.sum(abs(x-y))
distance_sum = 0
for i in range(n_clusters):
group = cls.labels_ == i
members = X[group,:]
for v in members:
distance_sum += manhattan_distance(np.array(v), cls.cluster_centers_[i])
distance.append(distance_sum)
k.append(n_clusters)
plt.scatter(k, distance)
plt.plot(k, distance)
plt.xlabel("k")
plt.ylabel("distance")
plt.show()
运行结果
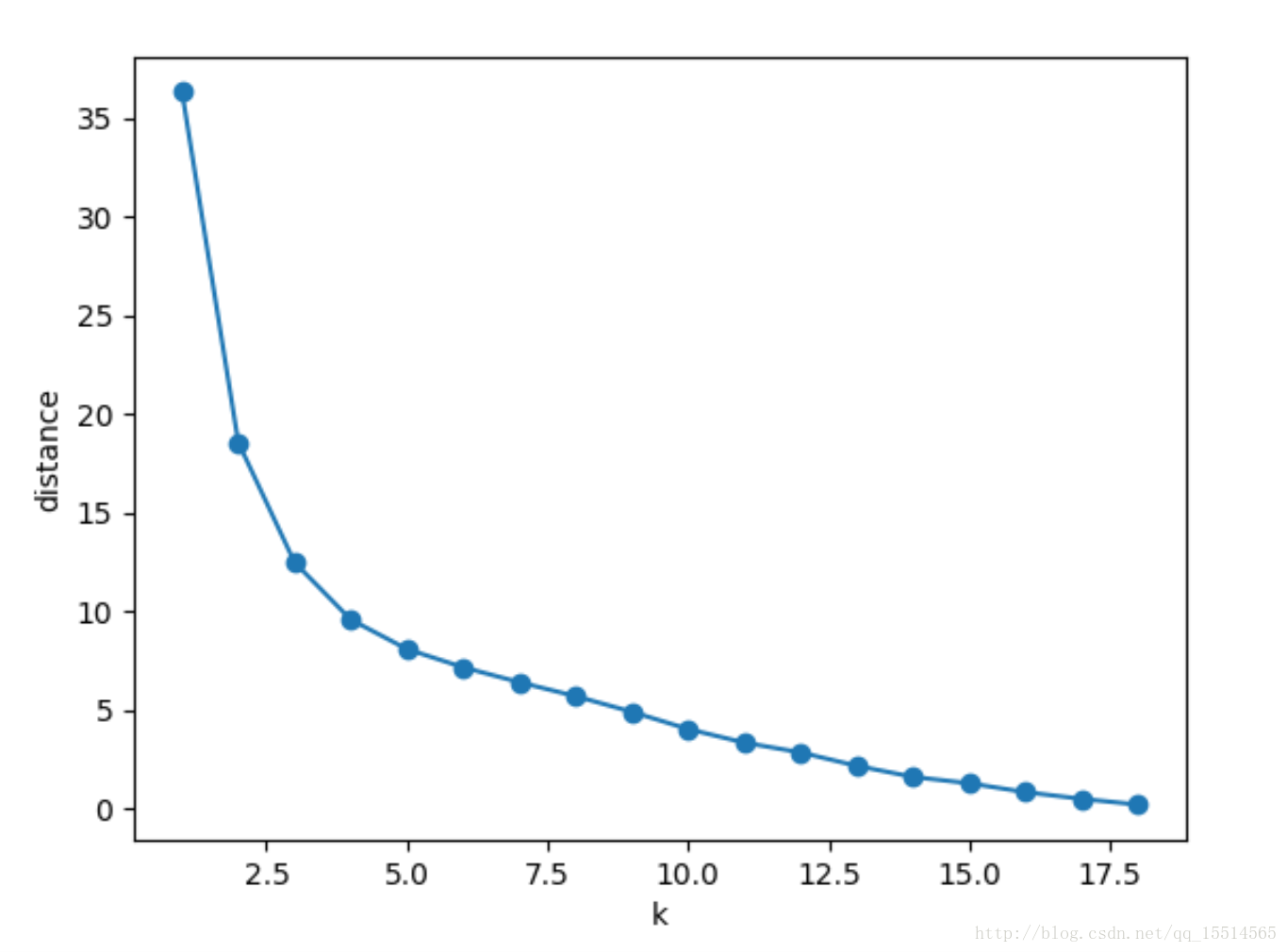
可以看到k取5时比较合适
4.测定聚类质量
K-Means是一种非监督学习,没有标签和其他信息来比较聚类结果。但是,还是有
一些指标可以评估算法的性能。已经介绍过类的畸变程度的度量方法。下面将介绍另一种聚类
算法效果评估方法称为轮廓系数(Silhouette Coefficient)。轮廓系数是类的密集与分散程度的评价
指标。它会随着类的规模增大而增大。彼此相距很远,本身很密集的类,其轮廓系数较大,彼此集
中,本身很大的类,其轮廓系数较小。轮廓系数是通过所有样本计算出来的,计算每个样本分数的均
值,计算公式如下:

a是每一个类中样本彼此距离的均值, b是一个类中样本与其最近的那个类的所有样本的距离的均
值。下面计算所有对象的轮廓系数的平均值
'''
Created on 2017年9月21日
@author: zawdcxs
'''
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 读取数据
X = []
f = open('cluster.txt')
for v in f:
X.append(
[float(v.split(',')[2]),
float(v.split(',')[3])])
# 转换成numpy array
X = np.array(X)
#把数据和对应的分类数放入聚类函数中进行聚类
cls = KMeans(n_clusters=6).fit(X)
#类簇的数量
n_clusters = len(set(cls.labels_))
# 曼哈顿距离
def manhattan_distance(x, y):
return np.sum(abs(x - y))
#计算所有向量的轮廓系数的平均值
#轮廓系数的和
sv_sum = 0
#遍历每一簇
for i in range(n_clusters):
a_group = cls.labels_ == i
a_members = X[a_group,:]
#遍历每个向量
for v in a_members:
# av:v到同一簇其他点的距离的平均值
distance_sum = 0
for k in a_members:
if np.array_equal(v, k):
continue
distance_sum += manhattan_distance(np.array(v), np.array(k))
av = distance_sum / len(a_members)
print("cluster_"+str(i)+"_vector_"+str(v)+"av: " + str(av))
# bv:v到其他所有簇的最小平均距离(从每个簇中挑选一个离v最近的向量)
distance_sum = 0
for j in range(n_clusters):
distance_min = 100
b_group = cls.labels_ == i
b_members = X[b_group]
for m in b_members:
if np.array_equal(v, m):
continue
distance = manhattan_distance(np.array(v), np.array(m))
if distance_min > distance:
distance_min = distance
distance_sum += distance_min
bv = distance_sum / n_clusters
print("cluster_"+str(i)+"_vector_"+str(v)+"bv: " + str(bv))
sv = float(bv-av)/max(av,bv)
print("cluster_"+str(i)+"_vector_"+str(v)+"sv: " + str(sv))
sv_sum += sv
#所有向量轮廓系数均值
sv_mean = sv_sum/len(X)
print("sv_mean: "+str(sv_mean))
#画图
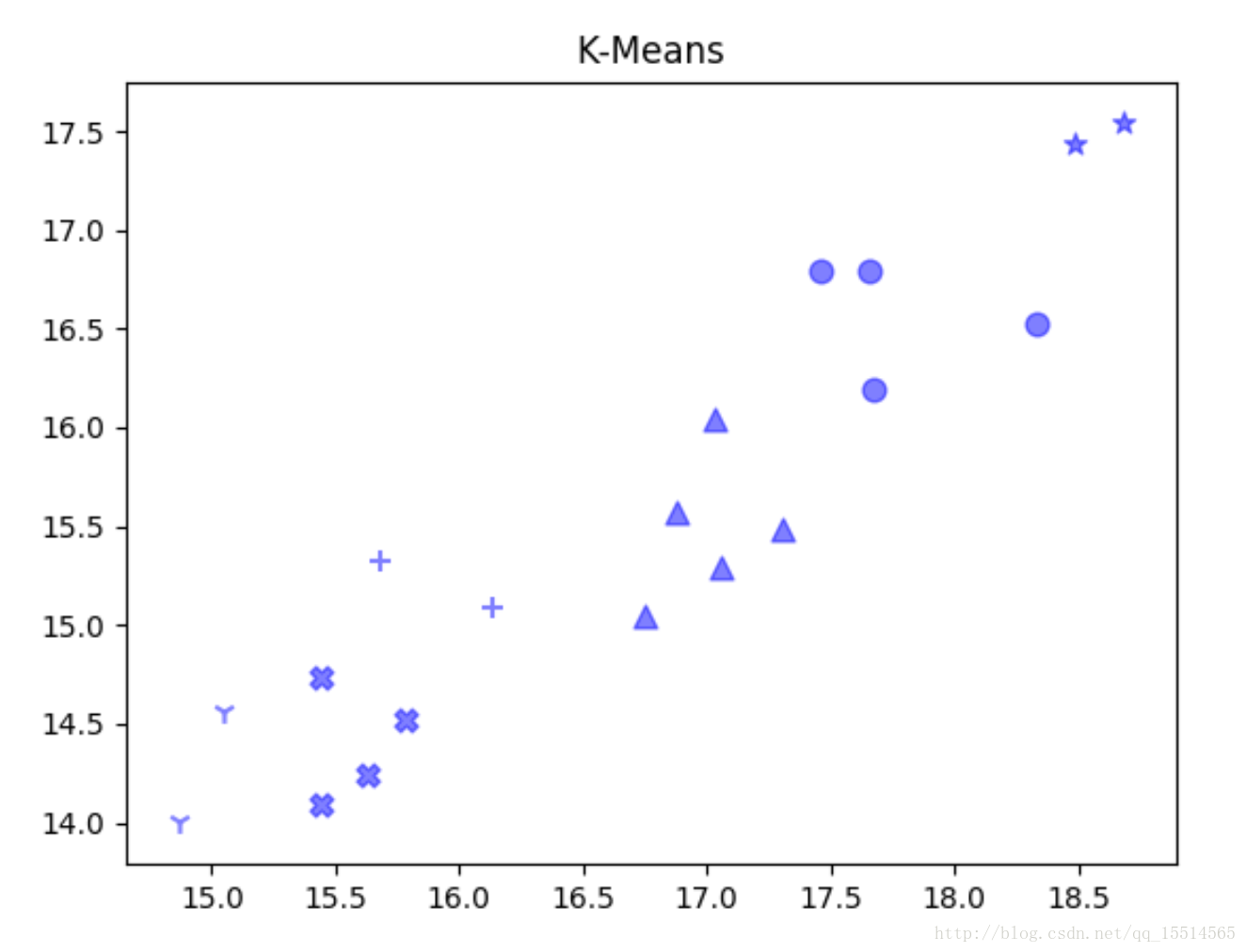
markers = ['X','o','*','^','+','1','2','3','4']
for i in range(n_clusters):
members = cls.labels_ == i
plt.scatter(
X[members,0], X[members,1], s=60, c='b', marker=markers[i], alpha=0.5)
plt.title("K-Means")
plt.show()
聚类质量计算结果:sv_mean: 0.645681114234 还可以吧