版权声明:沃斯里德小浩浩啊 https://blog.csdn.net/Healer66/article/details/82054862
字典树其实很简单啊。
它就是一个存储了很多字符串的树。如下图 :
:
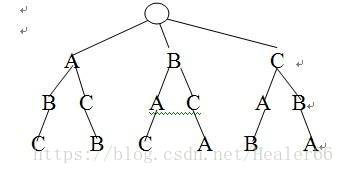
用这种结构存储字符串,不仅节省空间,而且方便增删和查找字符。
一般来说,都是用某种结构体来封装字典树的。
const int maxn = 26;
struct Trie
{
Trie *Next[maxn];//26个英文字母,所以一个节点有26个分叉
int Flag;// 标记当前节点是否是保存信息的结尾,也可以代表前缀个数
Trie()
{
Flag = 1;// 初始化以该信息为前缀的信息个数
memset(Next, 0, sizeof Next);
}
}*root;1、插入操作
将某字符串插入字典树,其实就是依次将该信息的前缀信息保存在对应节点中,并修改相应标记的Flag值即可。
void Insert(char *str)
{
int len = strlen(str);//strlen函数比较费时,所以提前保存字符长度
Trie *p = root, *q;// 将str的每一个字符插入trie树
for(int i = 0; i < len; i++)
{
int id = str[i] - 'a';
// 如果没有边,则新建一个trie节点,产生一条边,用以代表该字符
if(p->Next[id] == NULL)
{
q = new Trie();
p->Next[id] = q;
p = p->Next[id];
}
// 如果存在边,则沿着该边走
else
{
p = p->Next[id];
// 累加以该信息为前缀的信息个数
++(p->Flag);
}
}
}2、查询操作
查询某个信息是否存在于字典树中,实质上也是将该信息的前缀信息与字典树上存储的对应位置的信息进行匹配,然后判断标记的值即可。
int Query(char *str)
{
int len = strlen(str);
Trie *p = root;
// 在trie树上顺序搜索str的每一个字符
for(int i=0; i<len; ++i)
{
int id = str[i] - 'a';
p = p->Next[id];
// 若为空集,表示不存以此为前缀的信息
if(p == NULL) return 0;
}
// 返回以该信息为前缀的信息个数
return p->Flag;
}3、删除操作
递归释放字典树的每一个节点占用的空间即可。
void Free(Trie* T)
{
if(T == NULL) return;
// 释放trie树的每一个节点占用的内存
for(int i=0; i<MAXN; ++i)
{
if(T->Next[i]) Free(T->Next[i]);
}
delete(T);
}
部分引自:https://blog.csdn.net/u011787119/article/details/46991691