AVL树:每个节点额左子树和右子树的高度最多差1。查找、插入和删除在平均和最坏情况下都是O(logn)。
红黑树:红黑树和AVL树类似,都是在进行插入和删除操作时,特定的操作保持二叉树的平衡,从而获得较高的查询性能。
红黑树的4个性质:
1.每个结点都是红色或黑色
2.根节点是黑色,每个叶结点是黑色
4.如果一个结点是红色,则两个儿子都是黑色
5.每个结点到其子孙结点的所有路径上包含相同数目黑色结点
红黑树的查询性能不如AVL树,因为它不像AVL树追求高度的平衡(AVL每个节点额左子树和右子树的高度最多差1),同时为了维护这种平衡性,AVL树每次插入删除会进行大量的平衡度计算,故在插入和删除上远不如红黑树。
B树产生的原因:
首先,简单说一下B树产生的原因。B树是一种查找树,我们知道,这一类树(比如二叉查找树,红黑树等等)最初生成的目的都是为了解决某种系统中,查找效率低的问题。B树也是如此,它最初启发于二叉查找树,二叉查找树的特点是每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次I/O操作,随着树高度的增加,频繁的I/O操作一定会降低查询的效率。
这里有一个基本的概念,就是说我们从外存储器中读取信息的步骤,简单来分,大致有两步:
- 找到存储这个数据所对应的磁盘页面,这个过程是机械化的过程,需要依靠磁臂的转动,找到对应磁道,所以耗时长。
- 读取数据进内存,并实施运算,这是电子化的过程,相当快。
综上,对于外存储器的信息读取最大的时间消耗在于寻找磁盘页面。那么一个基本的想法就是能不能减少这种读取的次数,在一个磁盘页面上,多存储一些索引信息。B树的基本逻辑就是这个思路,它要改二叉为多叉,每个节点存储更多的指针信息,以降低I/O操作数
参考:https://blog.csdn.net/guoziqing506/article/details/64122287
B树示意图:
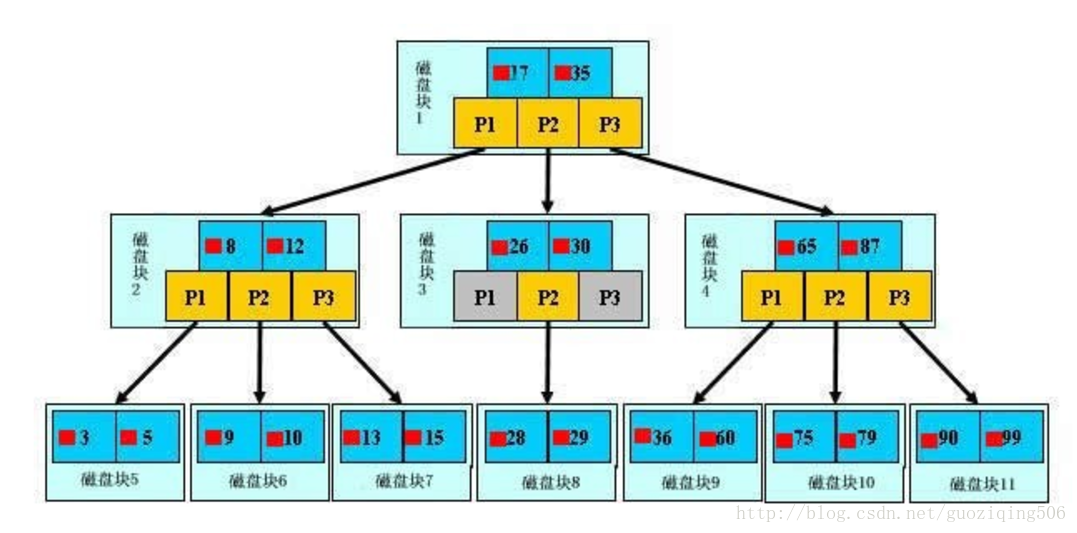
1.图中的小红方块表示对应关键字所代表的文件的存储位置,实际上可以看做是一个地址,比如根节点中17旁边的小红块表示的就是关键字17所对应的文件在硬盘中的存储地址。
2.P是指针,不用多说了,需要注意的是:指针,关键字,以及关键字所代表的文件地址这三样东西合起来构成了B树的一个节点,这个节点存储在一个磁盘块上
下面,看看搜索关键字的29的文件的过程:
1.从根节点开始,读取根节点信息,根节点有2个关键字:17和35。因为17 < 29 < 35,所以找到指针P2指向的子树,也就是磁盘块3(1次I/0操作)
2.读取当前节点信息,当前节点有2个关键字:26和30。26 < 29 < 30,找到指针P2指向的子树,也就是磁盘块8(2次I/0操作)
3.读取当前节点信息,当前节点有2个关键字:28和29。找到了!(3次I/0操作)
由上面的过程可见,同样的操作,如果使用平衡二叉树,那么需要至少4次I/O操作,B树比之二叉树的这种优势,还会随着节点数的增加而增加。另外,因为B树节点中的关键字都是排序好的,所以,在节点中的信息被读入内存之后,可以采用二分查找这种快速的查找方式,更进一步减少了读入内存之后的计算时间,由此更能说明对于外存数据结构来说,I/O次数是其查找信息中最大的时间消耗,而我们要做的所有努力就是尽量在搜索过程中减少I/O操作的次数。
B+树示意图:
B+树和B树相比,主要的不同点在以下3项:
1.内部节点中,关键字的个数与其子树的个数相同,不像B树种,子树的个数总比关键字个数多1个
2.对于B+树,所有指向文件的关键字及其指针都在叶子节点中,不像B树,有的指向文件的关键字是在内部节点中。换句话说,B+树中,内部节点仅仅起到索引的作用,而没有存储具体的数据。
3.B+树增加了叶子结点之间的指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针。
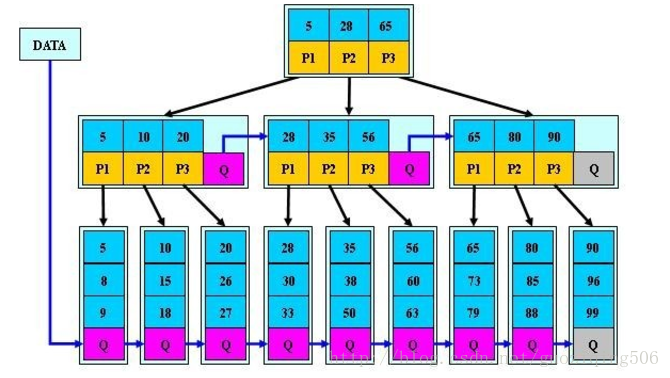
根据B+树的结构,我们可以发现B+树相比于B树,在文件系统,数据库系统当中,更有优势,原因如下:
-
B+树的非叶子结点只含有索引信息,意味着一个块中可以容纳更多的索引项,一是可以降低树的高度。二是一个内部节点可以定位更多的叶子节点。
-
B+树更有利于对数据库的扫描
B+树叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。所以对于数据库中频繁使用的范围查询,B+树有着更高的性能。