NLP常见任务
自动摘要
指代消解
机器翻译
词性标注
分词
主题识别
文本分类
1 向量空间子结构

最终目标:词向量表示作为机器学习,特别是深度学习的输入和表示空间

1.1 离散表示
(1) 均没有考虑时序:
a. 文档的向量表示可以直接将各词的词向量表示加和,词袋模型
b. 词权重 TF-IDF:
c. Binary weightinng:
(2) 考虑时序
Bi-gram 和 N-gram

离散表示的问题
- 无法衡量词向量之间的关系
- 词表维度随语料库增长膨胀
- n-gram词序列随语料库膨胀很快
- 数据稀疏问题
1.2 分布式表示
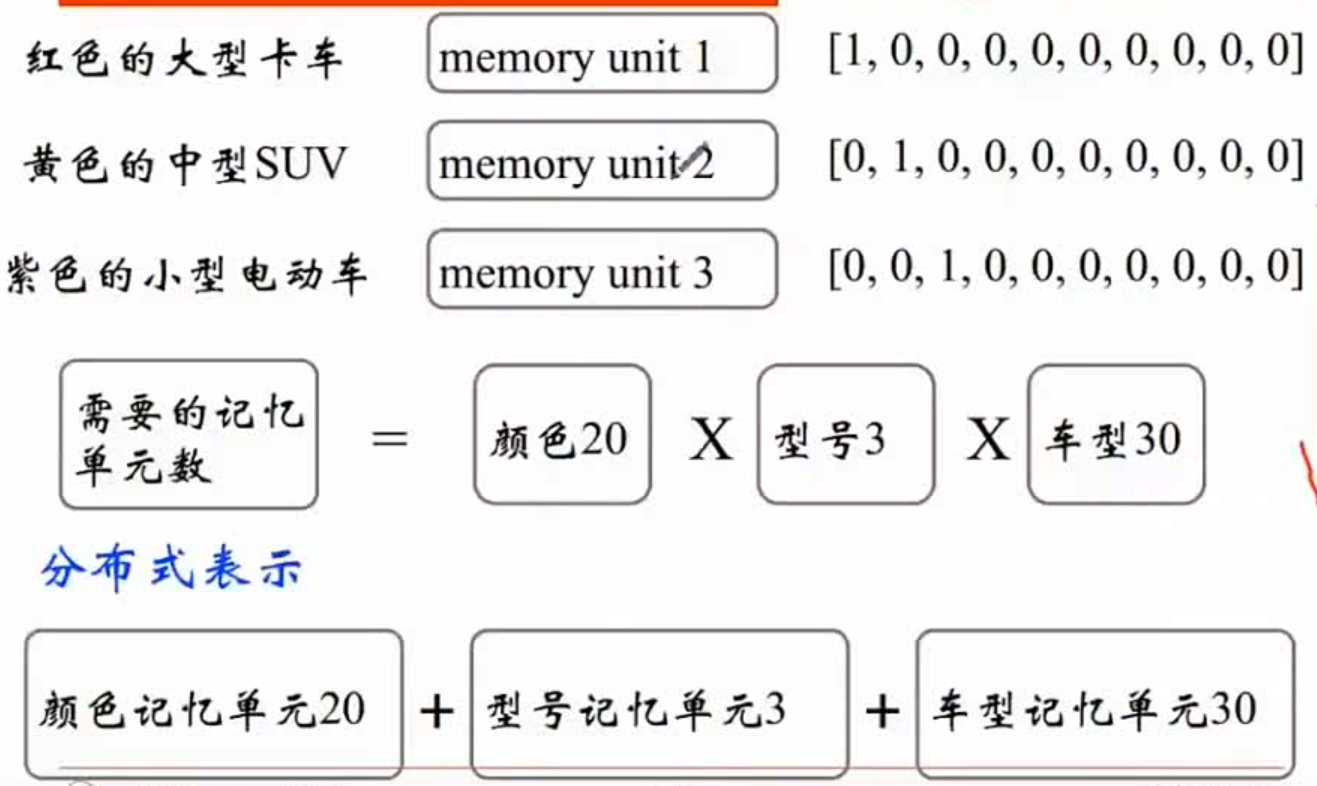
现代统计自然语言处理中最有创见的想法之一:用一个词附近的其他词来表示该词
1.2.1 共现矩阵(Concurrence matrix)
主要用于发现主题(topic),用于主题模型,如LSA(Latent Semantic Analysis)
居于窗中的Word-Word共现矩阵可以挖掘语法和语义信息
window length一般设为(5~10)
使用对称的窗函数(左右window length都为5~10)
存在的问题
- 向量维度随着字典大小线性增长
- 存储整个词典的空间消耗非常大
- 一些模型如文本分类模型会面临稀疏性问题
- 模型会欠稳定
1.2.2 SVD降维
最直接的方式,用SVD对共现矩阵向量做降维
存在的问题
- 实践复杂度
- 加入新词需要重新计算
- 与其他深度学习模型框架差异大
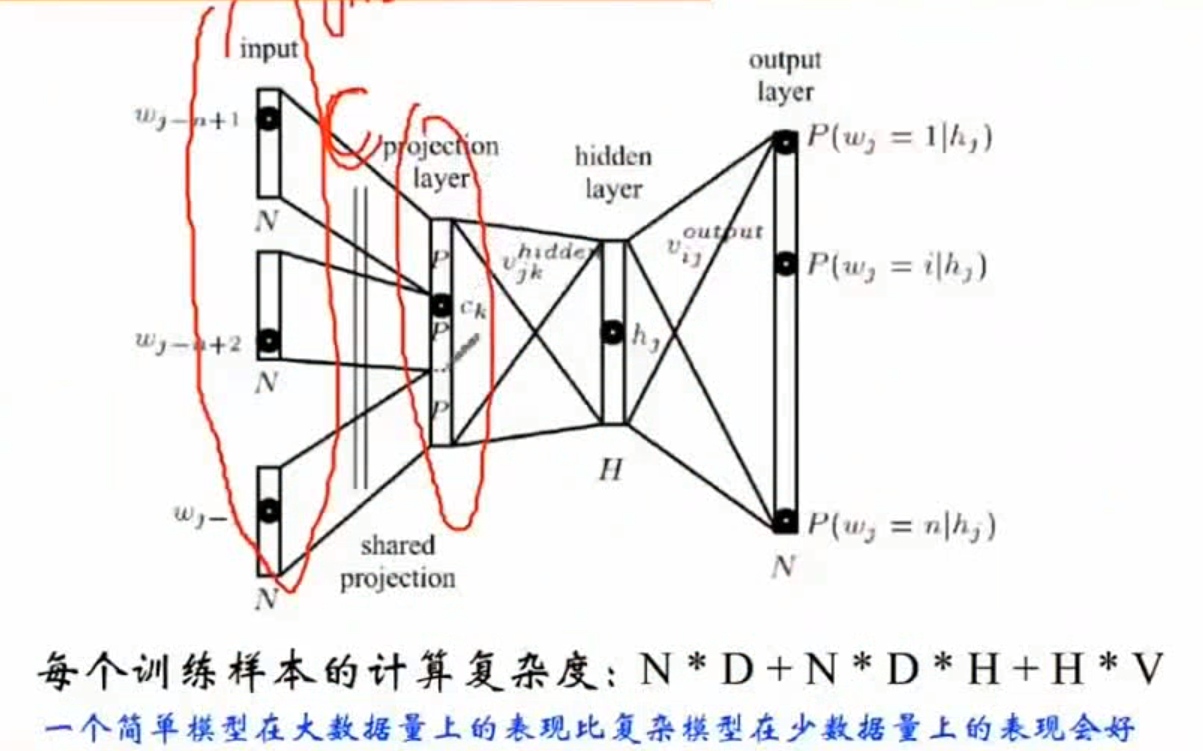
1.2.3 NNLM(Nerual Network Language model)
直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程
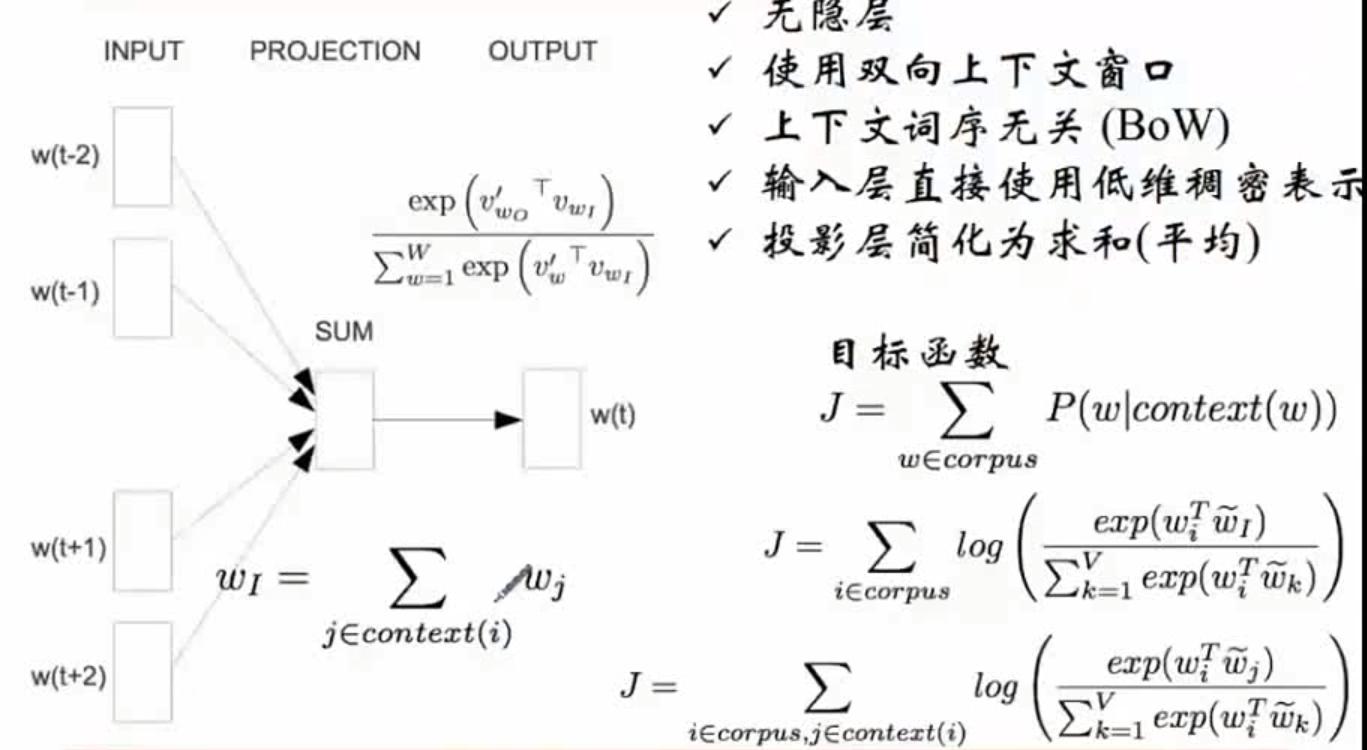
1.2.4 word2vec:CBOW(连续词袋)
神经网络比较依赖cpu,考虑到计算量,优化为word2vec