自然语言处理中,采用词向量表示文本。
用例子来说明
语料库:
Today is a good day.
Mona is a beautiful girl.词典:
{"Today":1, "is":2, "a":3, "good":4, "day":5, "Mona":6, "beautiful":7,
"girl":8}1.one-hot表示(独热表示)
Today:[1,0,0,0,0,0,0,0]
is:[0,1,0,0,0,0,0,0]
...
girl:[0,0,0,0,0,0,0,1]词典中的每个单词有唯一的索引。
词典中词的顺序和句子没有关联。
2.Bag of words(词袋形式)
出现次数累加:
Today is a good day. 这句话表示为[1,1,1,1,1,0,0,0]词权重TF-IDF(Term Frequency -Inverse Document Frequency)
词t的TF-IDF权重
,N表示文档总数,
含有t的文档数。
Today is a good day. 这句话表示为[0.693,1.099,1.099,0.693,0.693,0,0,0]3.元模型(Bi-gram和N-gram)
2-gram索引:
{“Today is”:1,
"is a":2,
"a good":3,
...
}优点:考虑词顺序
缺点:词表膨胀
4.共现矩阵表示(Cocurrence matrix)
Today is a good day.
Today is sunny.共现矩阵为:这个窗口为1且为对称窗口
count Today is a good day sunny .
Today 0 2 0 0 0 0 0
is 2 0 1 0 0 1 0
a 0 1 0 1 0 0 0
good 0 0 1 0 1 0 0
day 0 0 0 1 0 0 1
sunny 0 1 0 0 0 0 1
. 0 0 0 0 1 1 0共现矩阵的行(或列)作为词向量。缺点:向量维数随着词典大小线性增长(高维并稀疏)。 解决方法:降维和矩阵压缩。降维方法有:SVD降维。
NNLM(Neural Network Language model)
从语言模型出发,将模型的最优化过程转化为求词向量的过程。
目标函数:
NNLM结构图如下:
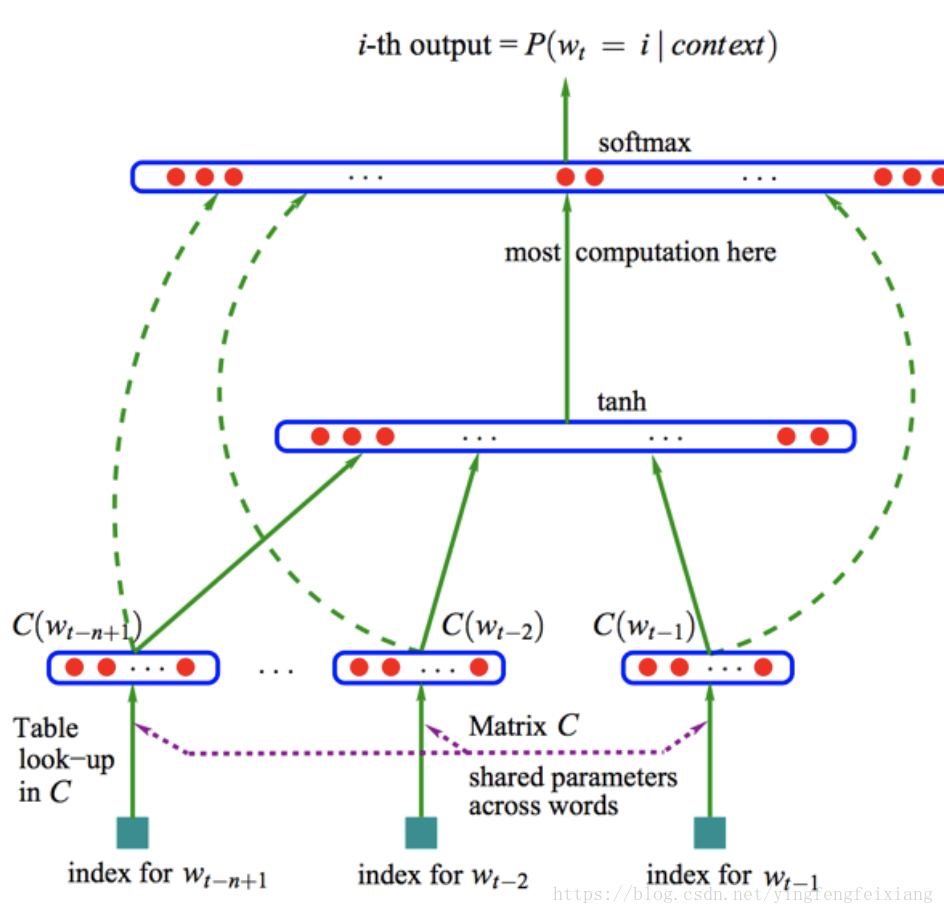
输入层(input):One-hot表示,(N-1)个前向词。输入为行向量
投影层(projection layer):采用线性映射将noe-hot表示投影到稠密D维表示。C为投影矩阵。生成稠密矩阵
隐藏层(hidden layer):全连接
输出层(output):Softmax分类器,输出为概率向量 ,取概率最大的max(p)。
word2vec:CBOW-Continuous Bag of Words Model
Word2vec结构根据NNLM结构并对其进行了简化。
结构图:
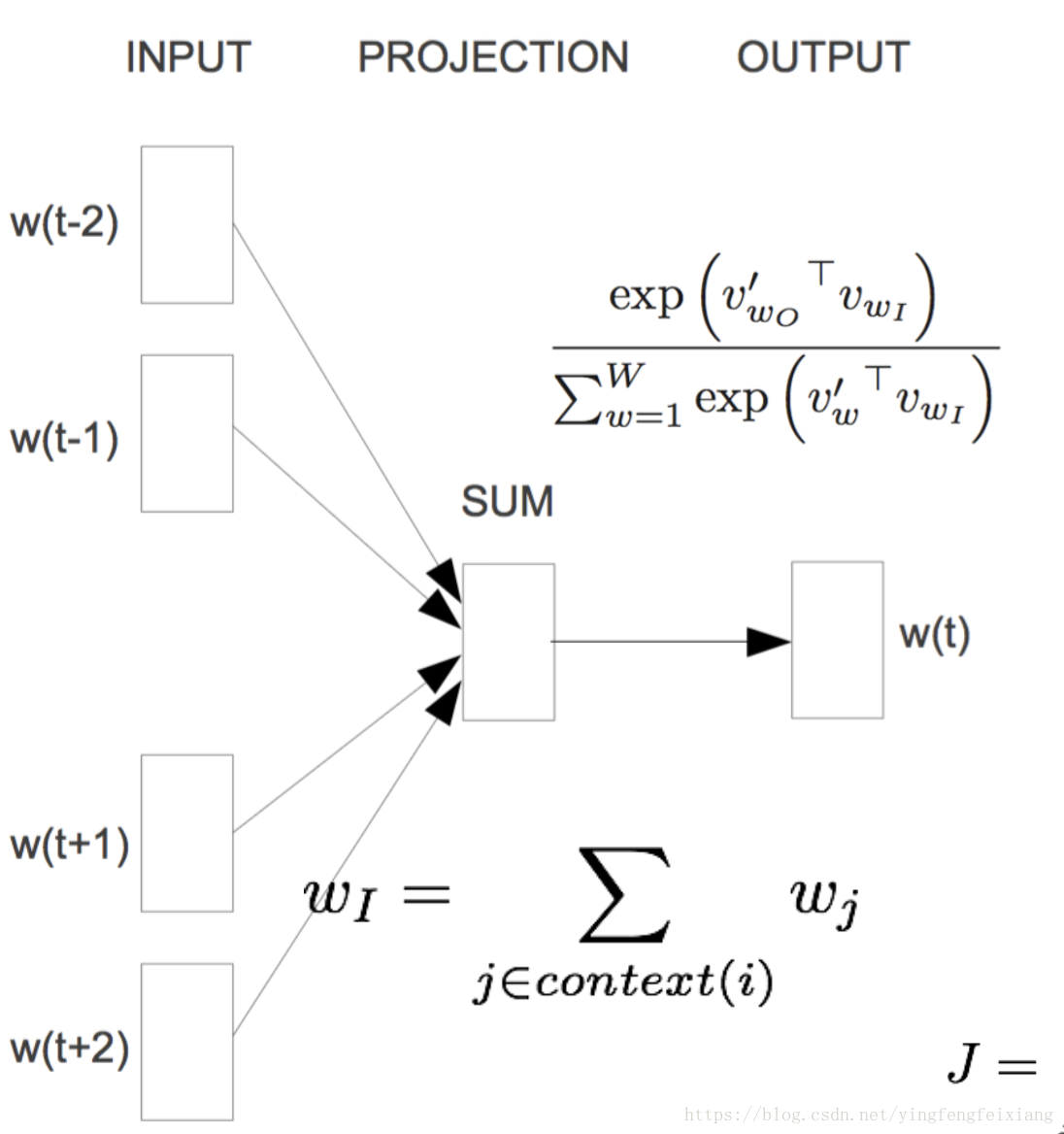
目标函数:
输入层(input):直接使用低维稠密表示
投影层(projection):简化为求和(或平均)
输出层(output):输出层依然是Softmax分类器,输出为概率向量 。
特点:
1.无隐层
2.使用双向上下文窗口
CBOW的改进
由于上诉CBOW输出维度依然是词的个数维度,维度太高。因此有了以下的改进方法。
CBOW:层次Softmax
1.层次Softmax采用哈夫曼树(Huffman Tree)来编码输出层的词典
2.计算路径上非叶子结点词向量贡献。假如某个词在树的第四层,路径上的前三层每个结点的参数为
,含有这三个参数的sigmoid函数相乘的最大值。
3.计算量为树的深度有V变为了
.
CBOW:负例采样
在样本不均衡情况下,采用负样本采样方法。将这个思想应用到word2vec中。
在输出中,我们实际就确定一个词为我们所需的词,为正例。而其他词都是不对的,也就为负例。假如有1w个词,正的为一个词,其他1w-1为负词。在计算时,不用1w-1个负词,而是从中选取300个(相当于负样本采样子集)。
接下来就是如何从中取这300个?
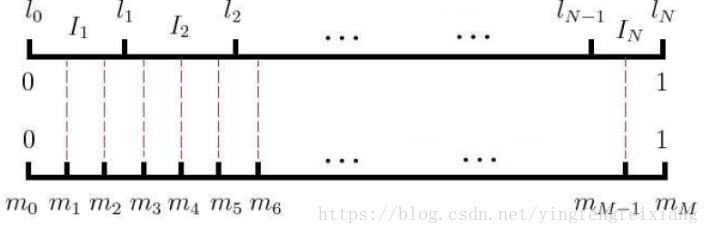
1.词汇表的词为V个,将长度为1的线段分为V份,每个词对应的线段长度为:
高频词对应的线段长,低频词对应的线段短.
word2vec实际应用中取
2.将[0,1]划分为M等份M>>V,每次 随机生成一个[1,M-1]间的数,看这个数落在那个词对应的部分上。
词划分与M划分如图:
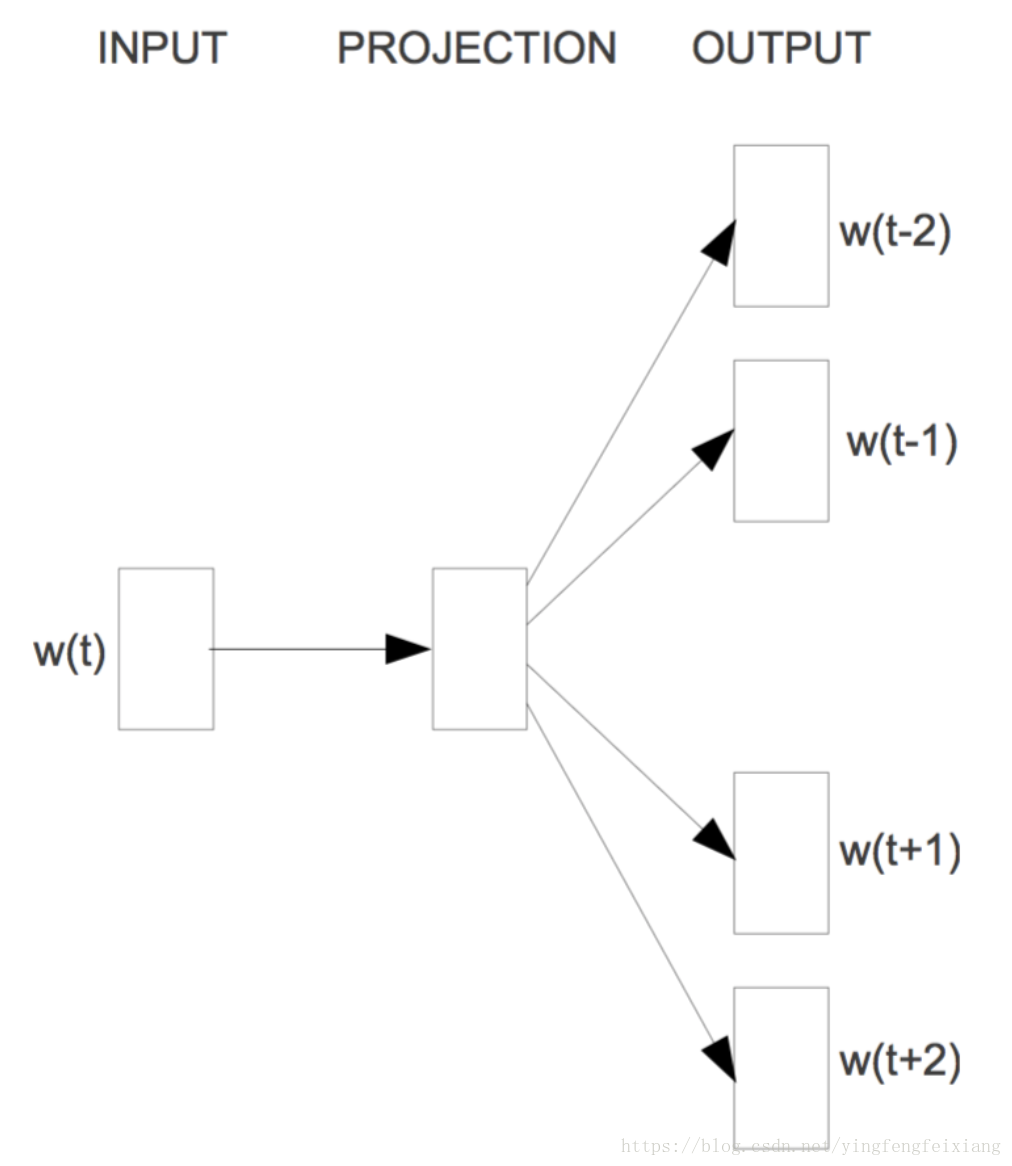
word2vec:Skip-Gram模型
Skip-Gram模型思想与CBOW思想是相反的。它是利用一次次来预测周围的词。
Skip-Gram模型结构如图:
word2vec存在问题
1.对于每个内容窗口单独训练,没有考虑全局。
2.对多义词无法很好的表示和处理,因为其使用了唯一的词向量。
gensim 中word2vec的参数
from gensim.models import word2vec(1) sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
(2) size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
(3) window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为 ,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
(4) sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
(5) hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
(6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
(7) cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的 为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示 ,默认值也是1,不推荐修改默认值。
注:文章主要为了便于自己记忆与理解,或有多处错误地方。推荐对word2vec介绍比较好的博客,参考http://www.cnblogs.com/pinard/p/7160330.html
文档:https://radimrehurek.com/gensim/models/word2vec.html
参数参考:http://www.mamicode.com/info-detail-1937943.html