记录词语的一种分布式表示方法word2vec,论文Distributed Representations of Sentences and Documents,其中有两种常用的无监督模型CBOW和Skip-gram,大同小异,但思想其实是有监督的。关键在于似然函数的构造和训练的加速。
一、CBOW
已知当前词的上下文来预测当前词,如图
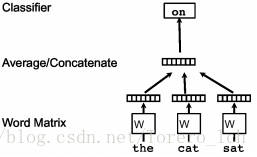

- Huffman树:带权路径长度最短的树,又称最优二叉树;
- 为什么叫hierarchi softmax:树的最下层的概率加起来等于1;
- 为什么用hierarchi softmax:如图中,若直接使用softmax,就要对词表中的每一个词计算,复杂度O(V),使用Huffman树后复杂度降为O(log2V),2为底,速度大大加快。(fasttext论文中也说是
和
)
- 在推导的时候想到了一个问题,因为都把word2vec结构也称为神经网络,就在想为什么这里没有用反向传播。看了看应该是此处的目标函数可以直接对要更新的参数求导,但多层的神经网络里想直接求偏导太困难,所以需要用到链式法则和全导数等方法。
- 为什么这里的概率用sigmoid来求?这里的sigmoid对应到传统的softmax中就是起到激活函数的作用,没有找到相关的解释,有可能是sigmoid的值域为(0,1),符合概率要求,也有可能是形式好便于求导吧。
二、Skip-gram
与CBOW很相似,推导基本一样,梯度更新如上图中;
三、Paragraph Vector
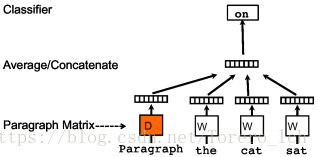
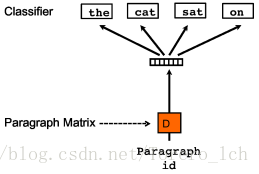
第一种叫PV-DM,第二种叫PV-DBOW。(和word2vec的叫法反过来了,感觉怪怪的)
整个PV过程和Word2Vec基本一样,增加了一个文档向量,在该文档内的训练过程中是共享的,不断更新。在PV-DBOW中,对应产生文档中的词语,跟Skip-gram原理一样。
四、训练向量的评价标准
原先好像是以词向量对于实际任务的收益来作为评价标准,比如词汇类比任务(A-B=C-D)和常见的NLP应用任务,但是脱离实际任务,又很难讲不同的词向量谁更好,所以现在很多工作开始学习任务相关的词向量。参考