终于彻底搞懂word2vec是什么了………….其实很简单,理解了之后再看之前写的稀里糊涂的代码有种豁然开朗的感觉。。
先转载一篇给我Word2Vec解惑的文章:http://blog.csdn.net/mylove0414/article/details/61616617
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder
- 杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
- 上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
- 宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
- 北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
使用Vector Representations可以有效解决这个问题。Word2Vec可以将One-Hot Encoder转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。
如果将embed后的城市向量通过PCA降维后可视化展示出来,那就是这个样子
!!!!word2vec模型其实就是简单化的神经网络
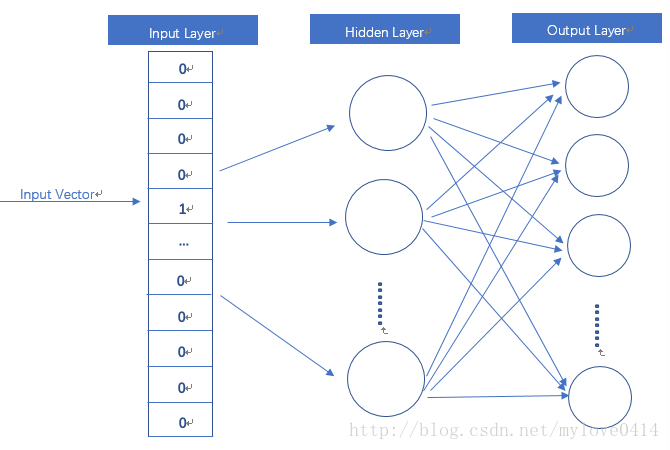
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。有的地方定为Input Layer和Hidden Layer之间的权重,其实说的是一回事

这里[10 12 19] 就是 [0 0 0 1 0]这个词的词向量
之前一直不太明白为什么有的地方说词向量是隐藏层输出有得地方说是输入层和隐藏层间的权重,看到这个计算公式瞬间就懂了…….词汇原本是one-hot编码的,所以只有一个位置为1其他地方为0的。列数取决于你有多少个词,词向量的行数一定等于one-hot编码的的列数,所以这么一乘,加之隐藏层无激活函数,所以隐藏层的输出就是权重矩阵某一行的值。所以上面的说法都可以。或者说权重矩阵其实就是每个词的向量编码一行一行的堆叠起来
所以说之前的只有一个1其他全是0的超长稀疏表达矩阵就转变为了稠密的矩阵,而这个稠密矩阵有几列取决于我们自己定义的隐藏层的宽度
word2vec本质
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果(权重矩阵)。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。因此上面图片写word2vec模型实际上是错的,其实是CBOW/Skip-gram 模型,通过这两个预测词汇模型提供词汇训练的方式,损失的计算(利用了相似语境中出现的词语其语义也接近这一思路 例如:i love you 和 i like you 中love和like语义接近),通过这两个模型的损失降低过程,将输入层到隐藏层的权重矩阵(词向量)最优化,最后我们要的就是这个矩阵。